软材料(如凝胶、弹性体)的设计面临多重挑战:需从海量结构单元(如单体)的组合中筛选最优类型、配比及排列方式,同时弱分子相互作用与热涨落导致跨尺度非线性结构-性能关系,尤其依赖介观结构的调控。传统理论模型难以精确预测,长期依赖实验试错。将数据驱动工具整合至端到端框架可加速软材料研发,但高质量数据集构建面临材料设计多样性高与实验通量低的矛盾。以水下粘合水凝胶为例,尽管应用前景广阔,其强韧可重复粘附性能的优化仍具挑战。现有研究虽识别出多种有效单体,却难以建立统一数据集或简化设计原则。
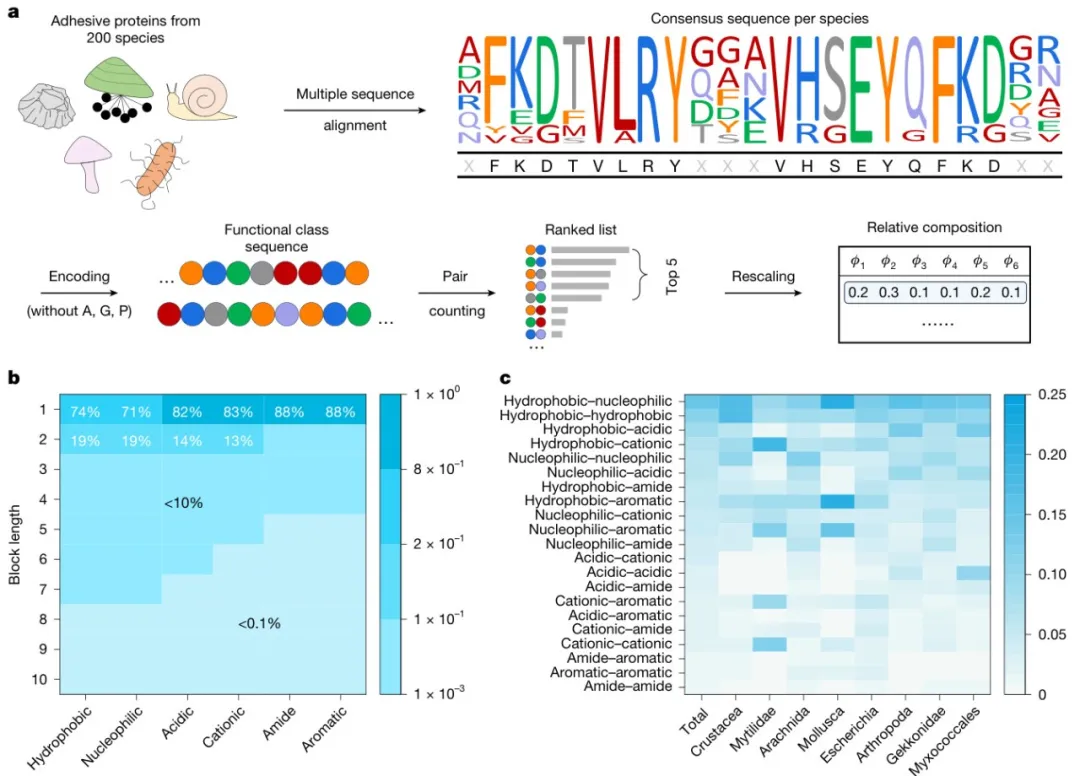
生物软组织(如壁虎足垫)的复杂结构为合成软材料设计提供了天然模板。特别是各类生物体共有的粘合蛋白,其保守序列模式为水下粘合剂开发提供了关键线索。然而,如何有效识别这些模式、转化为合成策略,并通过机器学习实现预测,仍是构建端到端设计模型的核心挑战。
日本北海道大学龚剑萍教授、Wei Li、Ichigaku Takigawa、深圳大学范海龙副教授
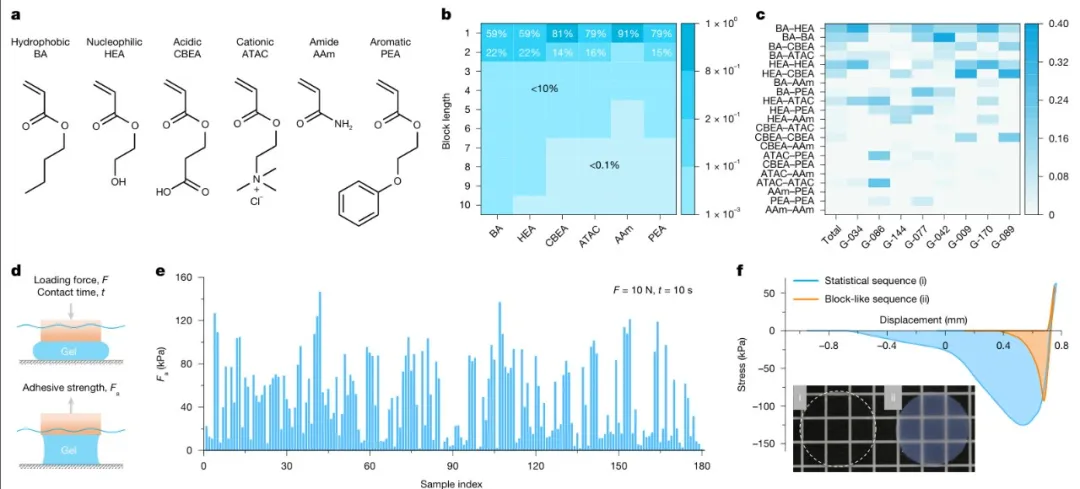
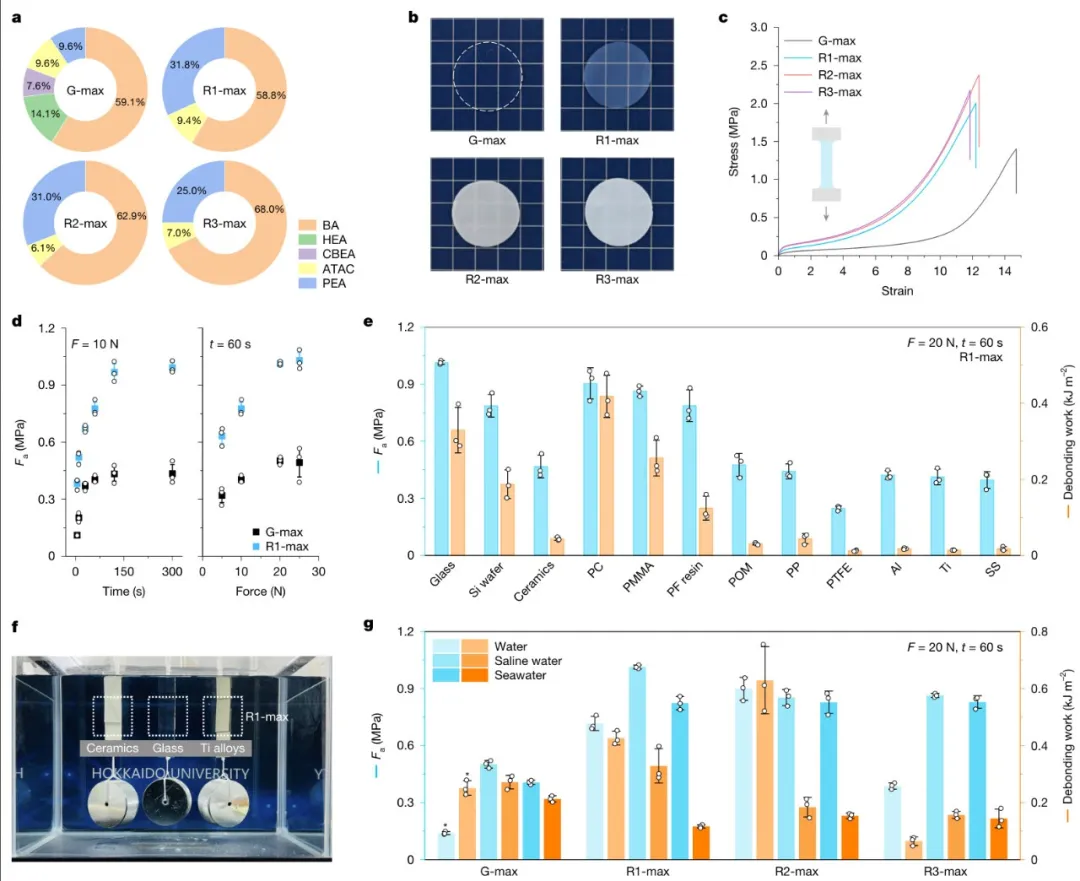
等研究人员介绍了一种新的数据驱动方法,该方法集成了数据挖掘(DM)、实验和机器学习(ML),以有效开发高性能水下粘合水凝胶。通过挖掘粘合蛋白数据库,提取特征序列特征来指导水凝胶设计。使用随机共聚和相对组成策略,把这些特征复制到180种合成水凝胶中,从而在生物保真度和实用合成之间取得平衡。在这些DM驱动的水凝胶中,有几种表现出比文献中报道的更高的粘合强度(Fa)。这组180种合成水凝胶形成了一个小而高质量的数据集,可通过ML进一步优化,从而使ML驱动的水凝胶的水下Fa超过1 MPa——比以前报道的水下粘合水凝胶和弹性体提高了一个数量级。所制备的超粘附性水凝胶在广泛的应用领域中拥有巨大的潜力,能够提供传统粘合剂难以企及的可靠解决方案。相关研究成果以“Data-driven de novo design of super-adhesive hydrogels”为题发表在Nature上。

![]()
![]()
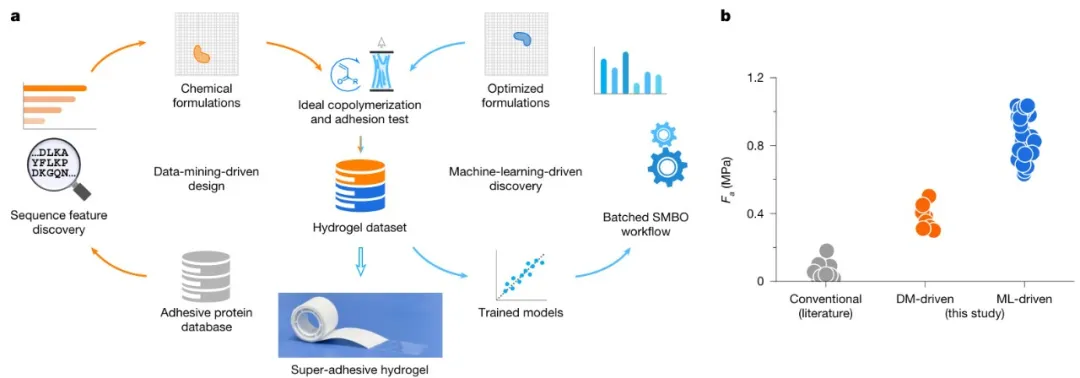
数据驱动的全新设计方法:提出了一种全新的数据驱动方法,将数据挖掘(DM)、实验和机器学习(ML)相结合,从头设计高性能水下粘附水凝胶。这种方法突破了传统软材料设计依赖实验试错的局限,通过挖掘蛋白质数据库中的信息,指导水凝胶的设计和优化。
从蛋白质序列中提取设计特征:通过挖掘黏附蛋白数据库,提取了具有代表性的蛋白质序列特征,并将其转化为水凝胶的设计策略。通过理想随机共聚的方法,在聚合物链中统计复制这些序列特征,从而实现了针对水下环境的高性能水凝胶设计。
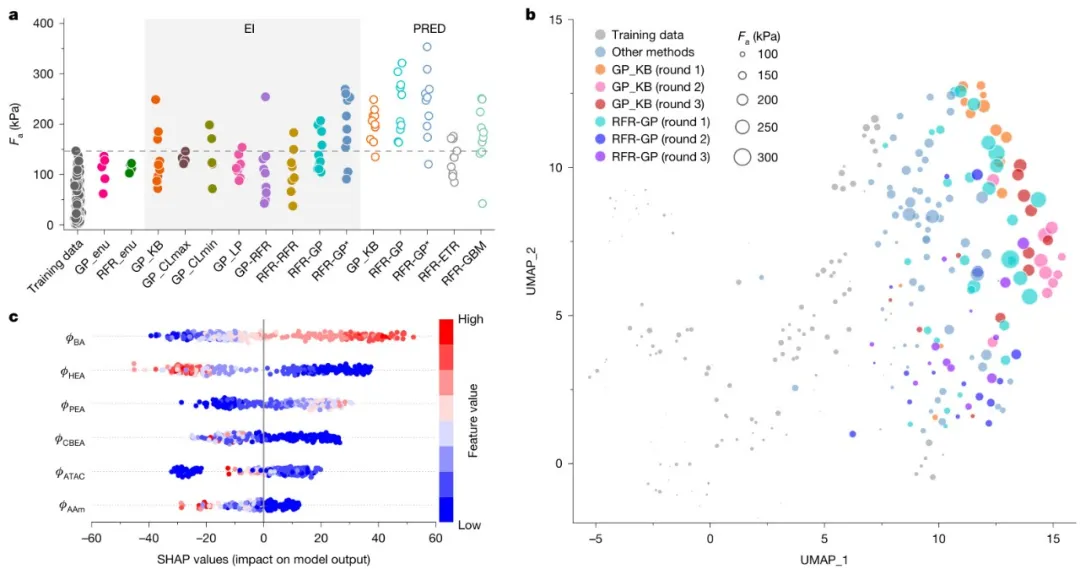
机器学习优化水凝胶配方:利用机器学习模型对初始的180种生物启发水凝胶数据集进行优化,实现了显著的黏附强度提升,最大值超过了1MPa,比之前报道的水下黏附水凝胶和弹性体提高了1个数量级。
超高性能水凝胶的广泛应用:通过数据驱动方法设计的超黏附水凝胶在多种应用中展现出巨大的潜力,包括生物医学工程、海洋养殖和深海探索等领域。这些水凝胶不仅在水下环境中表现出优异的黏附性能,还具有良好的生物相容性。
![]()
![]()
![]()
![]()
![]()
图5.通过DM(G-max)和ML优化(R1-max、R2-max和R3-max)确定的水凝胶的特性和性能
这项研究引入了一种数据驱动的方法,该方法整合了从蛋白质中提取有价值的序列信息、可扩展的聚合物合成和迭代机器学习,以解决软材料从头设计和开发中长期存在的挑战。除了粘合性水凝胶之外,该数据驱动的设计框架还提供了一种系统化、可扩展的端到端方法,用于开发各种功能性软材料。然而,挑战依然存在,主要原因是单体多样性、用于将单体序列控制到适合材料开发的规模的聚合物合成技术以及数据集的可扩展性方面的限制。克服这些挑战需要扩展模块化单体库、改进聚合技术,并开发能够泛化到稀疏、多尺度数据集的基于物理信息的机器学习模型。
https://doi.org/10.1038/s41586-025-09269-4(点击文末阅读原文可下载原文献)
声明:仅代表作者个人观点,作者水平有限,如有不科学之处,请在下方留言指正!
华研科技(www.cqhuayan.cn)由中科院博士成立,是一支具有科研背景及丰富科研绘图经验的团队,专注于
期刊封面、论文插图(TOC/流程图/摘要图/示意图)、科学动画、宣传片、科普视频等设计制作,科研绘图培训/专场培训,为国内外高校和科研院所提供丰富的可视化服务方案。设计作品已发表在Nature、Science、Cell等国际著名杂志上,服务客户的研究领域涵盖生物、物理、化学、医学、计算机、人工智能等各个学科,提供的科学可视化手段包括三维建模、手绘、VR/AR、数字孪生等。华研科技志在为广大科研工作者提供完美的科学可视化服务,节约您宝贵的时间和精力。(如有需要请添加文末微信)









