异常情况下的数据丢失问题将极大地影响业务的可用性,尤其在一些核心场景的数据恢复过程更是耗时耗力。在业务支持上我们亟需一种方案,当数据库在发生故障既要保证数据一致性也要减少切换时间,尽可能减少甚至彻底免除人工的介入。
小红书数据库团队提出一种基于Binlog Server的数据一致性解决方案,通过提升半同步复制性能,加速日志传输,在故障时可无侵入现有数据库架构地实现自动补数据,保证数据一致性。现推出的自研 Binlog Server 与 ORC 高可用方案,经过实践已证明可做到:1)使用极少的资源(1C1G)即可将复制速度提升至300MB/s+,实现了复制性能翻倍;2)优化了故障切换效率,按照一致性优先原则使用Binlog Server为新主库补数据,有效降低运维成本和业务风险,实现数据库快速数据恢复。目前该方案已经100%部署于小红书半同步复制集群,在多次切换中为新主库补数据,守护了核心数据库的安全。
2017年 GitLab 数据库工程师误操作,导致18个小时的服务中断并且部分数据永久性丢失,丢失数据影响了大约 5000 个客户和 700 个项目。
2022年某云厂商部分区域 RDS 服务不可用,影响了业务大约 3+小时。
2023年某云数据库出现了自动清理数据的 Bug,导致部分用户的最新数据删除且不可恢复。
2023年 Digital Ocean 托管的部分数据库异常切换,导致部分用户永久丢失 2-5 分钟数据。
核心场景的数据库一旦出现了数据丢失,会极大的影响了业务的可用性。因此,数据库的高可用性和一致性始终是核心业务系统的关键诉求。比如,DBA 同学也刚刚经历了这样惊心动魄的一幕:
💥 某天,数据库 P0 告警突发,核心集群主库宕机!XX同学需要立即与上下游业务紧急联动,定位到数据丢失并完成数据修正。经过一个小时的“救火”操作后,业务才逐渐恢复正常。这一“救火”场景出现,既消耗了大量的人力成本,也影响了系统整体稳定性。因此,亟需一种方案,当数据库在发生故障切换下也能自动保障数据一致性和完整性,彻底免除人工介入。
在展开方案介绍之前,我们先来了解 2 个知识:
🙋 什么是 RPO=0?RPO=0 意味着在任何切换或灾难发生后,数据一条都不丢! 如果实现了 RPO=0,当数据库发生宕机时,新的数据库能够100% 自动补齐所有数据,上下游业务不用再担心数据修复事务,极大降低运维压力和业务风险,在高可用里面实现了数据恢复的闭环。
🙋 业内主流OLTP数据库如何实现 RPO=0?业内主流方案主要分为以下三种:
MySQL 复制分为异步复制和半同步复制,其中半同步复制要求从库至少有一台复制成功响应,这样保证至少一台从库保存了日志数据。所以半同步复制的速度决定了主库写入速度的上限。但社区半同步实现复杂,其复制速度较慢,影响了主库写入速度。Facebook方案使用 Binlog Server 加快半同步复制速度,从而提升了主库写入性能,让更多的场景可以使用半同步复制。如果复制延迟太大(网络或者CPU耗尽等场景下),复制会出现自动降级,从半同步复制退化为异步复制,被称为半同步退化,半同步退化将影响数据一致性(本质是一种异步复制场景)。
基于方案复杂性和稳定性考虑,我们对比后决定采用 Binlog Server 方案,来实现小红书 MySQL 的 RPO=0,并满足以下条件:
将半同步复制速度翻倍,Binlog复制速度提升到 300MB/s+;
对现有 MySQL 架构和复制方案无侵入;
无缝支持现有 MySQL 高可用架构的切换方案。
相对于社区MySQL半同步+开源ORC高可用组件,自研Binlog Server+自研ORC高可用在半同步复制速度、轻量化部署、数据一致性优先和运维便捷性等场景进行优化,保证 RPO=0。
得益于Binlog Server性能的提升,当出现写入大压力的场景时,Binlog Server可以跟上主库写入速度,并且在故障场景下为新主库提供日志数据。
当前线上采用了同城异可用区 Binlog Server 部署形式,也就是在 MySQL 集群内部署一个同城、不同机房、半同步连接的 Binlog Server 实例,如下图所示:
这样做的目的是为了提升 MySQL 故障恢复的“数据 0 丢失”半径 ,确保在发生机房级故障时,ORC 的切换机制依然能够保证数据的一致性。Binlog Server 的性能显著优于普通从库,在小事务压测条件下,其写入速度可达 300MB/s,且资源消耗极低。凭借高吞吐、低资源消耗的优势,Binlog Server 完全可以部署于异地机房,大幅提升系统在机房级故障下的数据恢复能力,实现 0 数据丢失的主库故障切换。
1.3 切换效果验证
得益于 Binlog Server 的高吞吐能力,以及半同步复制特性,可以确保 Binlog Server 中的数据始终保持最新。即使遇到如机房断网等严重故障场景,结合 ORC 的选主策略,可以实现 MySQL 故障切换过程中数据 0 丢失。
目前 Binlog Server 配合 ORC 的数据一致性方案已经开始灰度,线上已经覆盖到半同步核心集群,半同步集群覆盖比例达到100%。
下面的案例的切换效果如下,详细展示了切换过程中Binlog Server作为临时主库给下游补充数据。
首先关注一下影响主从延迟的原因。下图是MySQL主从复制的完整的数据链路图。绿色框表示执行线程,黄色框表示实例(主库/从库)的Binlog,因为Binlog Event中带有时间戳,所以主从延迟表示为从库的Binlog时间 - 主库的Binlog时间。红色的框为Relaylog,可以理解为从库来不及处理的数据的临时在磁盘存储的文件。紫色为每个worker thread对应的处理队列(内存结构)。
从图中可以看到,整个复制链路经历的环节特别多,任何一个环节速度跟不上都会造成主从延迟比较大。其中IO Thread和Dispatch Thread之间的干扰会降低半同步复制速度(包括不限于共享Mutex锁,IO串行化,共享复制位点信息等),如果IO线程处理速度慢将影响Master节点对业务响应的速度。复制速度慢一直是MySQL社区存在的问题,否则也不会有各种Binlog Server方案。
在MySQL不满足需求的情况下,参考调研市场上已有的Binlog Server,总结各个方案的优缺点。
根据行业的调研和数据库现状,从上面的部署来看,Facebook Binlog Server方案是最合适的,其功能丰富,和现有系统能兼容。但其实现未开源,将按照其设计思路设计自研Binlog Server。
功能:支持半同步,提供RPO=0的方案;支持级联架构,在主从切换时为从库补充Binlog数据;
性能:半同步复制时提供更高复制速度,相对于主库无丢失;
运维:支持MySQL管理命令,无需外部系统改造;轻量化部署,1C1G资源即可满足需求;
稳定性:支持crash recovery,保证数据一致性;
兼容性:兼容MySQL 生态的各种解析工具,无需单独开发。
Binlog Server架构与其基本数据流和控制流基本如下图所示。下图所示为级联架构(对Binlog Server来说最复杂的场景),同时支持Master和Slave分别作为上下游,表现类似一个MySQL实例。其中绿色线表示Binlog Server控制流,主要是从Admin管理员发送的管控SQL,在SQL解析器处理后,在Manage模块进行处理,可以对MasterSession(和主库的连接),SlaveSession(和下游从库的连接),Binlog(本地存储文件)进行管理。红色线就是数据流,主要是存放主库发送来的Binlog数据,存储在本地并通过SlaveSession向下游发送。具体模块将一一展开介绍。
下面介绍3.1-3.5节为各个模块实现细节,3.6节将介绍Binlog Server和ORC配合主从切换。
为了满足上面的数据流程,需要支持如下协议的解析&处理:
BinlogServer->Master,Slave->BinlogServer进行认证、连接和状态获取SQL
Admin->BinlogServer管理线程的认证和连接
Admin->BinlogServer发送的COM命令
BinlogServer->Admin发送的ResultSet
Master->BinlogServer, BinlogServer->Slave发送的Event格式
这里需要按照MySQL协议规定的注册、握手、COM格式、ResultSet格式以及EVENT格式处理, 对于协议的发送将复用MySQL Client的库,但是协议解析和数据包封装需要Binlog Server处理。以Binlog为例,其基本格式如下图所示,需要分别对Header和Footer处理,提取各个字段。
为了方便ORC进行管理,对现有的运维系统和高可用系统无侵入。需要Binlog Server支持SQL语法,可以减少周围系统的开发和适配成本。在这里我们制作了一个语法解析器支持特定SQL类型。联调和部署时遇到新SQL支持,十分方便进行新语法的支持。
这里无法采用MySQL解析器,因为MySQL的词法解析部分全部自行编写,而不是采用FLEX(全局变量,不支持多线程并发),以提升SQL解析性能,从而支持每秒几十万次的SQL解析速度,缺点就是代码非常复杂,难以将所需功能进行剥离。但是Binlog Server的SQL语法只是用来做运维管控,没有对高并发的需求,所以在FLEX词法解析过程即使串行化,依然有几千次的解析速度,完全满足管控SQL需求。可以使用AI写bison和flex文件语法解析器文件,效果非常好。
如下图所示,当输入的字符串经过词法解析器(取出token)和语法解析器(获得语法树),就可以提取需要的语法树信息。
从整个SQL执行视角来看,SQL执行分为三个阶段:
语法解析阶段
SQL命令执行阶段
SQL结果输出阶段
支持 start slave 和 stop slave 等运维命令,保持slave的启停方式和MySQL一致。以start salve为例,下面展示了 SQL 解析和执行过程,首先会建立一个新 session 和 MySQL 客户端保持联系,然后用户发出 start slave 命令,按照COM_QUERY进行解析。在自定义语法解析器中,将start slave 标记为 SQLCOM_START_SLAVE,然后执行 节点注册过程(详细过程见下一节),最终返回结果集。
Binlog Server支持级联架构,既可以作为Slave节点从上游接收并保存Binlog,也可以作为Master向下游发送Binlog。因此其必须具有双向注册能力,需要遵守MySQL节点注册的规范,模拟作为从库或者主库进行注册。
和异步复制相比,半同步发送Binlog过程有变化,这将影响BinlogServer处理的过程。如下图所示,Master节点生成了Binlog文件(由一个个Event构成),在发送Event时,会在每个Event前添加Header。每个Header由2字节构成,第一字节为0xEF(Magic Number)用于校验,第二字节为0x1/0x0,用于指示从库是否发送ACK。当数据发送到BinlogServer以后,会先处理Header信息,确定是否需要发送ACK,如果需要发送,就将MasterLog位点信息发送给主库。主库收到ACK后确认这些数据已经在下游持久化,即可在主库InnoDB进行提交(AFTER_SYNC模式)。
这里需要注意一点,如果ACK信息丢了,后面的ACK确认的位点会自动包含前面的位点,这样保证发送过程不至于中断。
Binlog文件管理主要分为两部分,第一是Binlog文件管理;第二是Crash时的数据一致性。
文件管理:参考MySQL Binlog设计,使用索引文件记录Binlog元数据信息。所以采用索引文件+数据文件结合的方式记录。
数据一致性:Crash Safe重点强调宕机场景(非预期场景),但是对于预期内的关机也保持了一致性。
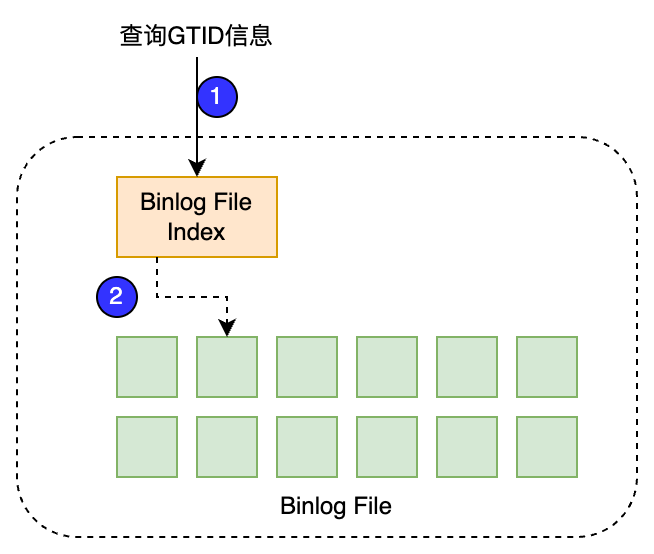
为了保证Binlog索引文件和数据文件的一致性,参考MySQL修改Binlog的方式。变动时先修改Binlog索引文件,创建新的临时文件,然后再修改Binlog数据文件,最后将临时的索引文件覆盖写为正式的索引文件。这个过程中如果出现了宕机等场景,那么根据临时文件和Binlog文件是否修改,决定该操作是提交还是回滚,从而保证了数据的一致性。
当主库宕机时,希望最终选举出来一个同机房的新主库为业务提供服务。但是同机房的从库不一定是数据最多的从库。因此需要增加补数据的环节,如下图所示。
高可用组件ORC在数据切换的时候,会分为两个阶段进行。
1M:根据GTID最大原则选出第一轮备选主库,开始补数据。这一轮没有偏好,尽量选择GTID最长的作为Master来给所有节点补数据。
2M:根据同机房 & GTID最长选择第二轮主库,作为新的Master。这一轮存在偏好,例如选择和老主库在同一个机房的Slave作为新主库。
主库故障和恢复流程简化过程上图所示。部署形态上采用Master挂载2个半同步的BinlogServer以保证数据不丢失,Master同时挂载若干个异步复制的Slave节点。
如果主库宕机(不可恢复),如图2所示:
ORC 1M阶段,将选择两个Binlog Server中GTID最长的一个作为临时Master,给其他所有节点补数据。这一轮选举大概率是同机房的Binlog Server。如果同机房Slave和Binlog Server GTID相同(写入量很小,所有机器数据没有延迟), ORC选择没有偏好,能将GTID补上即可。
ORC 2M阶段,同机房的Slave将作为新的主库,将其他所有的节点挂载到新主库上。
经过ORC 2M阶段,数据库集群即可对外提供服务。同时在本机房内,异步补充一台新从库。
新从库补充完毕后,整体的部署将和故障前完全一致。
在这个过程中,Binlog Server的添加不会对ORC选举额外造成负担。因为1M选择时,仍然按照GTID最长原则。所以Binlog Server提供足够高的性能后,ORC会自然选择到Binlog Server。只是在2M选择的时候,需要排除Binlog Server作为新的备选主库即可。
Binlog Server是一个消耗资源极少的轻量化Binlog 存储节点(1C1G即可)。除了提供一致性解决方案以外,未来也可以在其他使用Binlog的场景中发挥作用。
在从库扩容、库表拆分的场景中使用Binlog Server补充Binlog数据;
Binlog Server支持标准MySQL协议,DTS、Canel等可以从Binlog Server拉取数据,降低主库压力;
Binlog Server后端使用S3(配合S3FS)作为存储,将节省Binlog保存成本,保持更长时间的Binlog数据。
张凡凡
小红书关系型数据库研发工程师,主要负责小红书关系型数据库内核研发。
周旭峰
小红书关系型数据库研发工程师,主要负责小红书关系型数据库高可用系统研发。
NoSQL数据库研发工程师/研发专家 (KV/Redis/KVCache等方向)
分布式数据库研发工程师/专家-存储&数据库 (图/表/向量/多模数据库等方向)
分布式存储研发工程师/研发专家 (块/文件/对象/存储底座等方向)
以上岗位点击链接即可直达投递入口~
也欢迎感兴趣的朋友投递简历至:
REDtech@xiaohongshu.com
并抄送至下方邮箱以获得最快速响应:
linzi@xiaohongshu.com











