
字符串是计算机编程中表示文本数据的一种数据类型。它是由字符组成的序列,可以包含字母、数字、标点符号和其他特殊字符。
一、字符串的转义符
转义有两层含义:
将一些普通符号赋予特殊功能,比如\n,\t等
将一些特殊符号变为普通符号,比如\",\\等
以下是一些常见的转义字符及其含义:
\n:换行符,表示在字符串中创建一个新行。
\t:制表符,表示在字符串中插入一个水平制表符(Tab)。
\b:退格字符,b代表backspace,可以把一个退格符看成一个backspace键
\":双引号,用于在字符串中包含双引号字符。
\':单引号,用于在字符串中包含单引号字符。
\\:反斜杠,用于在字符串中包含反斜杠字符本身。
s1 = 'D:\Program Files\nancy\table\back\Python 3.8\python.exe'print(s1)""" D:\Program Files ancy ablack\Python 3.8\python.exe"""
s2 = 'D:\Program Files\\nancy\\table\\back\Python 3.8\python.exe'print(s2)
s3 = r'D:\Program Files\nancy\table\back\Python 3.8\python.exe'print(s3)
s4 = "i'm \"yuan!\""s5 = 'i\'m "yuan!"'print(s4) print(s5)
二、格式化输出
格式化输出是一种将变量值和其他文本组合成特定格式的字符串的技术。它允许我们以可读性更好的方式将数据插入到字符串中,并指定其显示的样式和布局。
在Python中,有多种方法可以进行格式化输出,其中最常用的方式是使用字符串的 f-strings(格式化字符串字面值)。
2.1、%占位符
name = "yuan"age = 18height = 185
s = """ 员工信息: 姓名:%s 年龄:%s 身高: %s""" % (name, age, height)print(s)""" 员工信息: 姓名:yuan 年龄:18 身高: 185"""
在这个示例中,我们使用 %s 占位符将变量 name 的值插入到字符串 "Hello, %s!" 中,然后通过 % 运算符进行格式化。在执行格式化时,% 运算符的左侧是字符串模板,右侧是要按顺序插入的值。
2.2、f-string格式--【推荐使用】
格式化字符串字面值(Formatted String Literal,或称为 f-string)来进行格式化输出。适用于 Python 3.6 及以上版本
name = "yuan"age = 18height = 185.123456s = f"姓名:{name:?^15},年龄:{age:<20},身高:{height:<20.5} "print(s)
name = "abcdefg"age = 45height = 155.123456s = f"姓名:{name:-^15},年龄:{age:<20},身高:{height:<20.5} "print(s)"""汇总总结: s = f"姓名:{name:?^15},年龄:{age:<20},身高:{height:<20.5} 姓名:{name:15} 宽度是15个字符,字符串默认是左对齐,数字默认是右对齐 身高:{height:.5} 默认不增加宽度,只增加精度,只显示前5个有效数字 身高:{height:20.5} 宽度是20,精度是5 宽度.精度
年龄:{age:<20},身高:{height:<20.5} 宽度为20的左对齐, < 左对齐
"""
name = "yuan"age = 18height = 185
s = f""" 员工信息: 姓名:{name} 年龄:{age} 虚岁:{age + 1} 身高: {height} 其他:{1 + 1 > 2} 其他:{type(1 + 1 > 2)}"""print(s)""" 员工信息: 姓名:yuan 年龄:18 虚岁:19 身高: 185 其他:False 其他:"""
宽度与精度
格式描述符形式为:width[.precision]。
填充与对齐
格式描述符形式为:[pad]alignWidth[.precision]。
虽然 %s 是一种用于字符串格式化的方式,但自从 Python 3.6 版本起,推荐使用格式化字符串字面值(f-string)或 .format() 方法来进行字符串格式化,因为它们提供了更简洁和直观的语法。
三、字符串序列操作
3.1、索引和切片
在编程中,索引(Index)和切片(Slice)是用于访问和操作序列(如字符串、列表、元组等)中元素的常用操作。
字符串属于序列类型,所谓序列,指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通过每个值所在位置的编号(称为索引)访问它们。
索引用于通过指定位置来访问序列中的单个元素。在大多数编程语言中,索引通常从0开始,表示序列中的第一个元素,然后依次递增。而负索引从 -1 开始,表示序列中的最后一个元素。使用方括号 [] 来访问特定索引位置的元素。
切片用于从序列中获取一定范围的子序列。它通过指定起始索引和结束索引来选择需要的子序列。切片操作使用方括号 [],并在方括号内使用 start:stop:step 的形式。注意,start的元素可以获取到,stop的元素获取不到,最后一个元素是[stop-1]对应的元素。
s = "hello yuan"
print(s[6], type(s[6])) # y "y"print(s[0]) # hprint(s[-1]) # n
print(s[0:5]) # hello 左闭右开print(s[6:9]) # yuaprint(s[6:10]) # yuan 不建议,因为已经超出了索引的范围print(s[6:11]) # yuan 不建议,因为已经超出了索引的范围print(s[6:]) # yuan 缺省 默认取到最后print(s[:5]) # hello 缺省 默认从头开始print(s[:]) # hello yuan 缺省 从头取到尾print(s[6:9]) # yuaprint(s[-4:-1]) # yua 负数也是从-4 到-1 而不是 -1到 -4print(s[6:-1]) # yua
s = "heoll yuan"print(s[::1]) # hello yuan step=1: 从左向右一个个取print(s[::2]) # hloya step=2: 从左向右 两个取一个print(s[::3]) # hlyn step=3: 从左向右 三个取一个print(s[::-1]) # nauy olleh step=-1: 从右向左一个个取 【字符串反转】print(s[::-2]) # nu le step=-1: 从右向左 两个取一个
print(s[0:3]) # helprint(s[3:0]) # 从低到高,需保证步长为正,从高到底,需保证步长为负 因为默认步数为正,所以输出为空,取不到任何字符print(s[3:0:-1]) # lle 从索引为3开始到索引为0 但不包含0 从高到底,步长必须为负数print(s[-2:-4:-1]) # au 从索引为-2开始到索引为-4 但不包含-4
3.2、其它操作
s1 = "yuan"
s1 = "rain"print(s1) s1 = "Rain"
s = "hello yuan"print(len(s)) print(s[-1]) print(s[len(s) - 1]) print(len([1, 2, 3])) print(len({"k1": "v1"})) # 1
s1 = "hello"s2 = "yuan"print(1 + 2) print(s1 + " " + s2)
name_str = ""name1 = "rain"name_str += " "+name1
name2 = "eric"name_str += " "+name2
name3 = "yuan"name_str += " "+name3print(name_str)
print("*" * 10)
print("rain" in "rain eric yuan") print("rai" in "rain eric yuan") print("rains" in "rain eric yuan") print("rains" not in "rain eric yuan")
if "rain" in "rain eric yuan": print("奖励他") else: print("惩罚他")
if "rain" not in "rain eric yuan": print("奖励他")else: print("惩罚他")
四、字符串内置方法
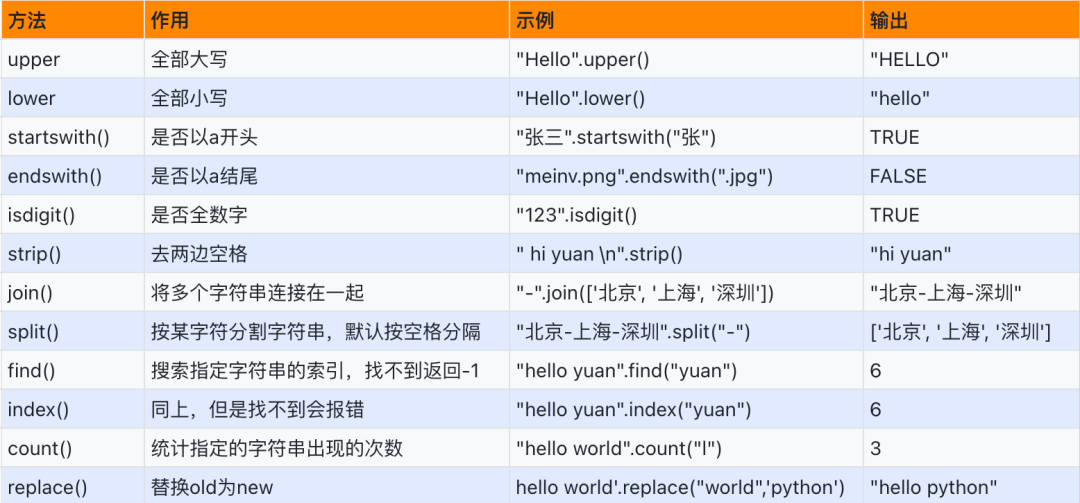
s = "Yuan"s2 = s.upper() print(s) print(s2) s3 = s.lower()print(s) print(s3) print("Hello World".upper()) print("Hello World".lower())
name = "张三丰"print(name.startswith("张")) print(name.startswith("张三")) print(name.startswith("丰")) print(name.endswith("丰")) print(name.endswith("三丰")) img_url =
"https://tenfei03.cfp.cn/creative/vcg/800/new/VCG41N639526572.jpg"print(img_url.endswith(".jpg")) print(img_url.endswith(".png"))
s = "hello yuan"print(s.find("yuan")) print(s.index("yuan")) print(s.find("Yuan"))
name = input("姓名:")print(name) print(len(name)) ret = name.strip() print(ret) print(len(ret))
print("\nyuan\n") print("\nyuan\n".strip())
s = "##abcd#####"print(s.strip("#")) print(s.rstrip("#")) print(s.lstrip("#"))
print("apple".isdigit()) print("123".isdigit()) print("123元".isdigit()) print("123.45".isdigit())
age_str = input("age:::")
if age_str.isdigit(): age = int(age_str) print(age) else: print("非法输入!")
cities = "北京 哈尔冰 重庆 大连"ret = cities.split(" ")print(ret) print(len(ret))
ret = ['北京', '哈尔冰', '重庆', '大连']print(",".join(ret))
info = "yuan|19|185"ret = info.split("|")print(ret) print(ret[0]) print(ret[1]) print(ret[2])
cities = "北京 哈尔冰 重庆 大连"ret = cities.replace(" ", ",")print(cities) print(ret)
sentence = "PHP is the best language.PHP...PHP...PHP..."ret = sentence.replace("PHP", "JAVA")print(ret)
comments = "这个产品真棒!我非常喜欢。服务很差,不推荐购买。这个餐厅的食物质量太差了,味道不好。我对这次旅行的体验非常满意。这个电影真糟糕,剧情一团糟。这个景点真糟糕,再也不来了!"
ret = comments.replace("差", "***")print(ret)
ret2 = ret.replace("糟", "***")print(ret2)
ret3 = ret.replace("不推荐", "***")print(ret3)
ret = comments.replace("差", "***").replace("糟", "***").replace("不推荐", "***")print(ret)
sentence = "PHP is the best language.PHP...PHP...PHP..."print(sentence.count("PHP"))
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
整理出了一套系统的学习路线,这套资料涵盖了诸多学习内容:开发工具,基础视频教程,项目实战源码,51本电子书籍,100道练习题等。相信可以帮助大家在最短的时间内,能达到事半功倍效果,用来复习也是非常不错的。
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉Python学习视频合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。
资料获取方式:↓↓↓↓
1.关注下方公众号↓↓↓↓,在后台发送:“111” 即可免费领取









