大家好,我是君哥。
MySQL 的 Redo Log 和 Binlog 是两种完全不同、但又紧密协同的日志机制。理解这两种日志,对理解 MySQL 的事务机制有重要帮助。今天来聊一聊这两种日志。
1.概念回顾
1.1 两阶段提交
我们知道,分布式事务一般都是使用两阶段提交达到最终一致。比如下图一个购买商品的案例,用户下订单后,订单服务保存订单,账户服务扣减金额,库存服务扣减库存。这三个服务通过两阶段提交,先 prepare,然后 commit 最终实现事务一致性。
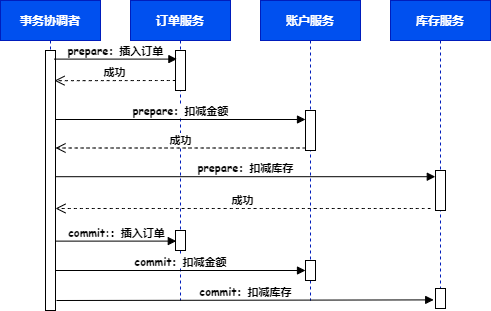
1.2 事务提交
我们再来看一下 MySQL 的逻辑架构,看下图:
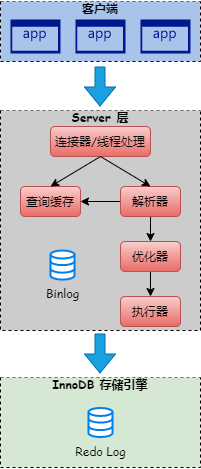
在 MySQL 逻辑架构中,执行器负责执行具体的
SQL,跟存储引擎进行交互。
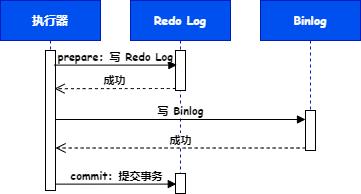
执行器就是两阶段提交的“事务协调者”,事务执行过程如下图:
假如我们要执行一条 SQL:
update t set a=10 where id=5;
这个 SQL 的执行过程如下:
执行器先从存储引擎拿到 id=5 这一行数据,然后把这一行数据的字段 a 改成 10,再把这行修改后的数据写入存储引擎。
prepare 阶段:存储引擎将这行新数据写入内存,同时将这行数据的更新操作记录到 Redo Log ,但不提交事务,然后给执行器返回成功。此时 Redo Log 处于 prepare 状态。
执行器为这行数据的更新操作生成 Binlog 并写入磁盘,当然,是否刷盘要根据 sync_binlog 配置来决定。
commit 阶段:执行器通知存储引擎提交事务,存储引擎把刚刚写入的 Redo Log 改成提交 commit 状态,完成事务提交。
2.Redo Log
2.1 介绍
从前面介绍可以看到,Redo Log 是存储引擎层控制的日志,事实上,Redo Log 是 InnoDB 存储引擎特有的日志,它是一个物理日志, 记录了在某个数据页上做了哪些修改,主要用于崩溃恢复。
Redo Log 的刷盘机制通过下面参数来控制:
innodb_flush_log_at_trx_commit
0:事务提交时,Redo Log 不会被立刻被写入磁盘,而是存在缓存中(Redo Log Buffer),InnoDB 后台日志线程每秒将日志从缓冲区写入文件系统缓存(Page Cache),然后调用 fsync 落盘。优点是减少了 I/O 操作,提升了性能,缺点是如果 MySQL 服务挂了,或者操作系统宕机,可能丢失 1s 的数据。
1:默认值。事务提交时,Redo Log 立即写入 Page Cache,并调用 fsync 保存磁盘,优点是系统宕机时丢失数据风险小,缺点是磁盘 I/O 操作频繁,影响性能。
2:事务提交时,Redo Log 被直接写入到 Page Cache,然后依赖操作系统的刷盘机制将 Page Cache 中的日志写入磁盘,优点是性能好,如果 MySQL 服务挂了,并不会导致数据丢失,只有操作系统宕机,Page Cache 未刷盘的数据才会丢失。
2.2 写日志
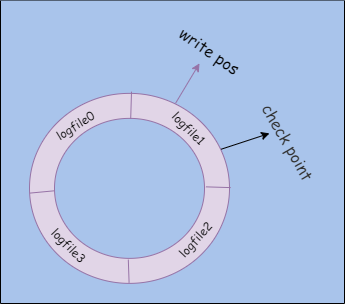
在写数据时,Redo Log 是循环写,空间大小固定,写满后会覆盖掉前面的日志。
Redo Log 采用固定大小的文件组,比如下图文件组配置了 4 个文件,每个文件大小相同,写满一个后接着写下一个,全部写满后就清除一部分前面的日志,继续写入。write pos 控制当前写入的位置,check point 控制可以写入的最后位置,如果两个点重合了,那就需要清除部分日志,让 check point 后移。
2.3 Redo Log 使用场景
崩溃恢复
这是 Redo Log 最根本的用途。它确保了数据库宕机后,已提交事务的数据不会丢失。Redo Log 基于 WAL (Write-Ahead Logging) 原则,即先写日志,再写磁盘。事务提交时,先将修改内容的记录到 Redo Log,MySQL 宕机重启后,利用 Redo Log 做崩溃恢复。恢复过程如下。
首先,InnoDB 会检查数据页的 LSN (日志序列号),并与 Redo Log 中的 LSN 对比。Redo Log 上 LSN 比数据页大的就是需要重做的数据。
接着,InnoDB 会扫描 Redo Log 中要恢复的日志,如果日志状态是 COMMIT,则直接重做。如果日志状态是 PREPARE,则还要去检查对应的 Binlog,如果该事务的 Binlog 存在且完整,说明事务已经提交成功,应该重做。如果该事务的 Binlog 不存在或不完整,说明事务应该回滚,Redo Log 日志不进行重做。
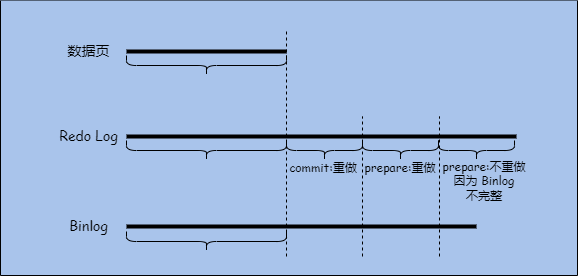
通过这个机制,确保了 Redo Log 和 Binlog 的逻辑一致性:只要 Binlog 写成功了,数据就一定能够被恢复;如果 Binlog 没写成功,说明事务应该被回滚,数据无需恢复。
优化性能
通过将数据文件随机写磁盘转换为 Redo Log 顺序写磁盘,大大提升了事务执行效率和数据库整体吞吐量。
3.Binlog
3.1介绍
Binlog 是 MySQL Server 层的日志,所有引擎都可以使用。它是一个逻辑日志,记录的是数据逻辑的变化(比如插入一条数据),用于主从复制和故障恢复。
跟 Redo Log 写日志方式不同的是, Binlog 是追加写,写满一个文件后切换到下一个文件写。
3.2 刷盘时机
MySQL 中 sync_binlog 参数定义了将 Binlog 内容从内存缓冲区同步到磁盘的频率。
- 0:MySQL 不会主动将 Binlog 内容同步到磁盘,完全依赖文件系统刷盘机制来落盘。这种方式磁盘 I/O 操作较少,性能最好,但存在数据丢失的风险。
- 1:每次事务提交时,都会将 Binlog 内容同步到磁盘。这种方式丢失数据的风险较小,但因为磁盘 I/O 操作多,容易影响数据库性能。
- N(N>1):每 N 个事务提交后,才会将 Binlog 内容同步到磁盘。这种方式是前两种方式的折中,既考虑了一定的性能,也兼顾了数据的安全性。
3.3 Binlog 使用场景
主从复制
这是 Binlog 最重要的用途。在主从架构中,Master 节点将自己的 Binlog 发送给 Slave 节点,Slave 通过重放 Binlog 中的 SQL 语句,实现数据同步。
点播恢复
因为 Binlog
完整记录了对数据库的所有更改操作,它可以通过重放来恢复某一个时间段的全部数据。在实际工作中,有时我们需要恢复数据库到某一个历史时间点的状态,这时我们可以找出这个时间点之前最近的一个全量备份,用这个全量备份恢复到一个空数据库,然后找出全量备份时间点到目标时间点之间所有 Binlog 文件并进行回放。这样就实现了精确的时间点恢复。这对于修复误操作(如误删表、误更新)非常有用。
总结
Redo Log 保存在 InnoDB 中,用于保证宕机后数据不丢,是 MySQL 支持数据库事务的基础。Binlog 保存在 MySQL server 层,用于主从同步或点播恢复。
两者分工明确但又紧密协作,共同保障了 MySQL 数据安全和高可用性。
为了让两个日志区别更清晰,总结下表:









