前言
有些小伙伴在工作中可能遇到过数据库查询慢的问题,特别是模糊查询和复杂聚合查询,这时候引入ES(Elasticsearch)作为搜索引擎是个不错的选择。
今天我们来聊聊MySQL同步到ES(Elasticsearch)的5种常见方案。
希望对你会有所帮助。
一、为什么需要MySQL同步到ES?
在我们深入讨论方案之前,先明确一下为什么需要将MySQL数据同步到ES:
- 全文搜索能力:ES提供强大的全文搜索功能,远超MySQL的LIKE查询。
- 复杂聚合分析:ES支持复杂的聚合查询,适合大数据分析。
先来看一下整体的同步架构图:

接下来,我们详细分析每种方案的实现原理和优缺点。
二、方案一:双写方案
双写方案是最直接的同步方式,即在业务代码中同时向MySQL和ES写入数据。
示例代码:
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Transactional
public void addUser(User user) {
// 写入MySQL
userMapper.insert(user);
// 写入Elasticsearch
IndexQuery indexQuery = new IndexQueryBuilder()
.withObject(user)
.withId(user.getId().toString())
.build();
elasticsearchTemplate.index(indexQuery);
}
@Transactional
public void updateUser(User user) {
// 更新MySQL
userMapper.updateById(user);
// 更新Elasticsearch
IndexRequest request = new IndexRequest("user_index")
.id(user.getId().toString())
.source(JSON.toJSONString(user), XContentType.JSON);
elasticsearchTemplate.getClient().index(request, RequestOptions.DEFAULT);
}
}
优缺点分析
优点:
缺点:
适用场景
适合数据量不大,对实时性要求高,且能够接受一定数据不一致的业务场景。
三、方案二:定时任务方案
定时任务方案通过定期扫描MySQL数据变化来同步到ES。
示例代码:
@Component
public class UserSyncTask {
@Autowired
private UserMapper userMapper;
@Autowired
private UserESRepository userESRepository;
// 每5分钟执行一次
@Scheduled(fixedRate = 5 * 60 * 1000)
public void syncUserToES() {
// 查询最近更新的数据
Date lastSyncTime = getLastSyncTime();
List updatedUsers = userMapper.selectUpdatedAfter(lastSyncTime);
// 同步到ES
for (User user : updatedUsers) {
userESRepository.save(user);
}
// 更新最后同步时间
updateLastSyncTime(new Date());
}
// 获取最后同步时间
private Date getLastSyncTime() {
// 从数据库或Redis中获取
// ...
}
}
数据更新追踪策略
为了提高同步效率,通常需要设计良好的数据变更追踪机制:
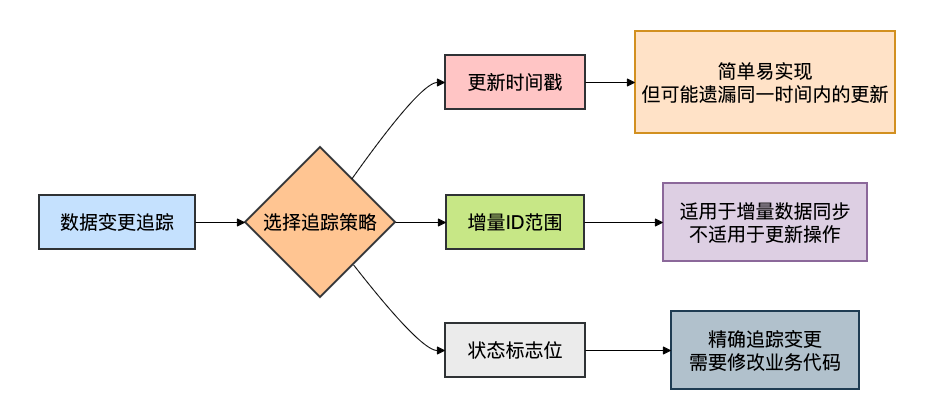
优缺点分析
优点:
缺点:
适用场景
适合对实时性要求不高,数据变更不频繁的场景。
四、方案三:Binlog同步方案
Binlog是MySQL的二进制日志,记录了所有数据变更操作。
通过解析Binlog可以实现数据同步。
示例代码:
public class BinlogSyncService {
public void startSync() {
BinaryLogClient client = new BinaryLogClient("localhost", 3306, "username", "password");
client.registerEventListener(new BinaryLogClient.EventListener() {
@Override
public void onEvent(Event event) {
EventData eventData = event.getData();
if (eventData instanceof WriteRowsEventData) {
// 插入操作
WriteRowsEventData writeData = (WriteRowsEventData) eventData;
processInsertEvent(writeData);
} elseif (eventData instanceof UpdateRowsEventData) {
// 更新操作
UpdateRowsEventData updateData = (UpdateRowsEventData) eventData;
processUpdateEvent(updateData);
} elseif (eventData instanceof DeleteRowsEventData) {
// 删除操作
DeleteRowsEventData deleteData = (DeleteRowsEventData) eventData;
processDeleteEvent(deleteData);
}
}
});
client.connect();
}
private void processInsertEvent(WriteRowsEventData eventData) {
// 处理插入事件,同步到ES
for (Serializable[] row : eventData.getRows()) {
User user = convertRowToUser(row);
syncToElasticsearch(user, "insert");
}
}
private void syncToElasticsearch(User user, String operation) {
// 同步到ES的实现
// ...
}
}
优缺点分析
优点:
缺点:
适用场景
适合对实时性要求高,数据量大的场景。
五、方案四:Canal方案
Canal是阿里巴巴开源的MySQL Binlog增量订阅&消费组件,简化了Binlog同步的复杂性。
示例代码:
# canal.properties 配置
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=username
canal.instance.dbPassword=password
canal.instance.connectionCharset=UTF-8
canal.instance.filter.regex
=.*\\..*
public class CanalClientExample {
public static void main(String[] args) {
// 创建Canal连接
CanalConnector connector = CanalConnectors.newSingleConnector(
new InetSocketAddress("127.0.0.1", 11111), "example", "", "");
try {
connector.connect();
connector.subscribe(".*\\..*");
while (true) {
Message message = connector.getWithoutAck(100);
long batchId = message.getId();
if (batchId != -1 && !message.getEntries().isEmpty()) {
processEntries(message.getEntries());
connector.ack(batchId); // 提交确认
}
Thread.sleep(1000);
}
} finally {
connector.disconnect();
}
}
private static void processEntries(List entries) {
for (CanalEntry.Entry entry : entries) {
if (entry.getEntryType() == CanalEntry.EntryType.ROWDATA) {
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) {
if (rowChange.getEventType() == CanalEntry.EventType.INSERT) {
processInsert(rowData);
} elseif (rowChange.getEventType() == CanalEntry.EventType.UPDATE) {
processUpdate(rowData);
} elseif (rowChange.getEventType() == CanalEntry.EventType.DELETE) {
processDelete(rowData);
}
}
}
}
}
}
架构设计
Calan方案的架构如下:
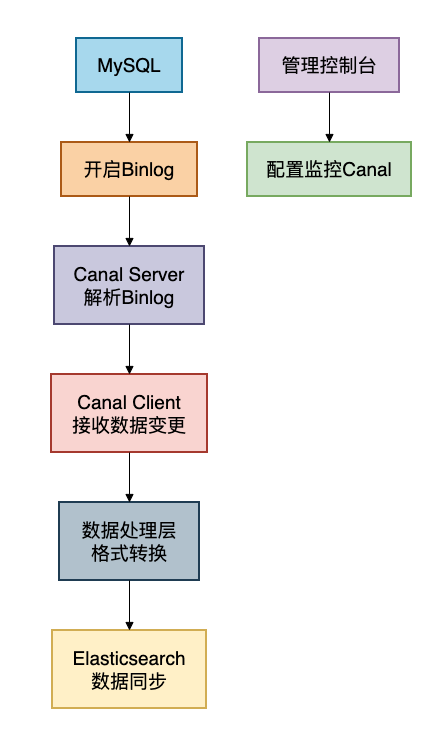
优缺点分析
优点:
缺点:
适用场景
适合大数据量、高实时性要求的场景,且有专门团队维护中间件。
六、方案五:MQ异步方案
MQ异步方案通过消息队列解耦MySQL和ES的同步过程,提高系统的可靠性和扩展性。
示例代码:
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private RabbitTemplate rabbitTemplate;
@Transactional
public void addUser(User user) {
// 写入MySQL
userMapper.insert(user);
// 发送消息到MQ
rabbitTemplate.convertAndSend("user.exchange", "user.add", user);
}
@Transactional
public void updateUser(User user) {
// 更新MySQL
userMapper.updateById(user);
// 发送消息到MQ
rabbitTemplate.convertAndSend("user.exchange", "user.update", user);
}
}
@Component
public class UserMQConsumer {
@Autowired
private UserESRepository userESRepository;
@RabbitListener(queues = "user.queue")
public void processUserAdd(User user) {
userESRepository.save(user);
}
@RabbitListener(queues = "user.queue")
public void
processUserUpdate(User user) {
userESRepository.save(user);
}
@RabbitListener(queues = "user.queue")
public void processUserDelete(Long userId) {
userESRepository.deleteById(userId);
}
}
消息队列选型对比
不同的消息队列产品有不同特点,下面是常见MQ的对比:
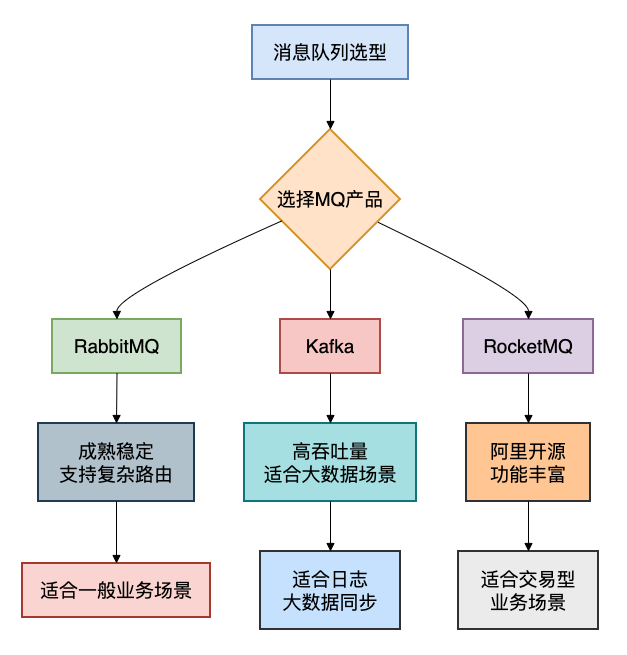
优缺点分析
优点:
缺点:
适用场景
适合大型分布式系统,对可靠性和扩展性要求高的场景。
七、5种方案对比
为了更直观地比较这5种方案,我们来看一个综合对比表格:
选择建议
有些小伙伴在工作中可能会纠结选择哪种方案,这里给出一些建议:
-
初创项目或小规模系统:可以选择双写方案或定时任务方案,实现简单。
- 中大型系统:建议使用Canal方案或MQ异步方案,保证系统的可靠性和扩展性。
- 大数据量高实时要求:Binlog方案或Canal方案是最佳选择。
- 已有MQ基础设施:优先考虑MQ异步方案,充分利用现有资源。
注意事项
无论选择哪种方案,都需要注意以下几点:
-
幂等性处理:同步过程需要保证幂等性,防止重复数据。
- 监控告警:建立完善的监控体系,及时发现同步延迟或失败。
- 数据校验:定期校验MySQL和ES中的数据一致性。
总结
MySQL同步到ES(Elasticsearch)是现代应用开发中常见的需求,选择合适的同步方案对系统性能和可靠性至关重要。
本文介绍了5种常见方案,各有优缺点,适用于不同场景。
在实际项目中,可能需要根据具体需求组合使用多种方案,或者对某种方案进行定制化改造。
重要的是要理解每种方案的原理和特点,才能做出合理的技术选型。
希望这篇文章对大家有所帮助,如果有任何问题或建议,欢迎在评论区留言讨论!








