当前,AIGC的可控生成好发顶会正成为诸多多模态生成研究者的共识。
顶会录用的关键是 “新颖性”,而可控生成的技术栈仍处于快速迭代期,存在大量未被挖掘的创新点。
比如下面的几个可创新方向。目前还存在大量可发顶会的工作可做。
| | |
|---|
| KG based+VideoTransformer长视频动态场景生成 | |
| | |
| | |
| | |
| | |
对这个方向感兴趣的同学,我给大家准备了这份学习资料。包括该方向必读的论文、可复现代码、仿真环境、开源数据集等。需要的同学可按下面的方式获取。

扫码添加小助理,回复“可控生成”
免费获取全部论文+开源代码+数据集+仿真环境

1. Rombach et al. High-Resolution Image Synthesis with Latent Diffusion Models(CVPR 2022)
方法:将扩散模型(DM)迁移至预训练自编码器的 latent 空间,平衡复杂度降低与细节保留,首次实现高分辨率图像合成的效率与质量双赢。
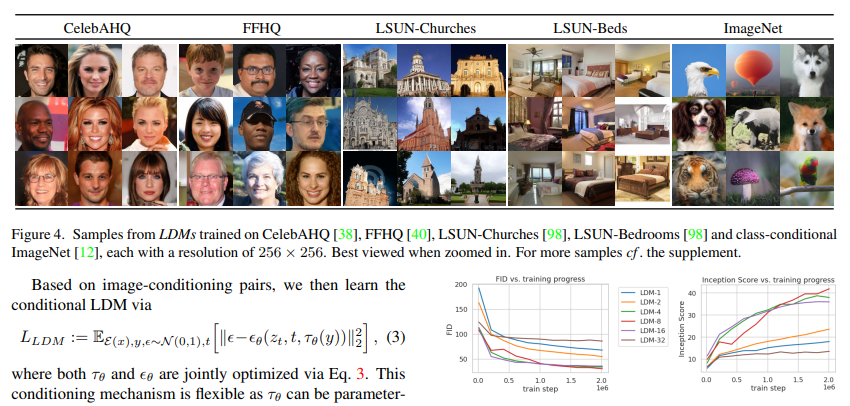
创新点:
- 提出 latent 扩散模型(LDMs),避开像素空间训练的高计算成本,大幅减少训练和推理的 GPU 资源消耗。
- 引入交叉注意力机制,支持文本、边界框等多模态条件输入,灵活适配图像修复、文本到图像生成、超分辨率等任务。
- 采用两阶段训练模式,预训练自编码器可复用,无需为不同任务重复训练基础模块,提升模型通用性。
2. Radford et al. Learning Transferable Visual Models from Natural Language Supervision(CLIP, ICML 2021)
方法:通过对比学习实现语言 - 图像跨模态预训练,突破传统视觉模型依赖标注数据的局限,达成高效零样本迁移。
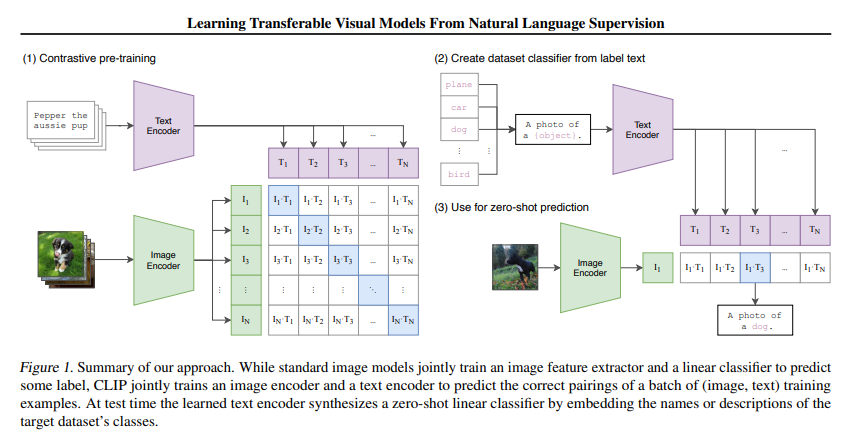
创新点:
- 构建含 4 亿对(图像 - 文本)的大规模数据集,以 “预测图像与文本是否配对” 为预训练任务,学习统一的多模态嵌入空间。
- 支持零样本迁移至 30 余种计算机视觉任务,无需任务特定训练数据,在 ImageNet 上匹配 ResNet50 精度。
- 模型鲁棒性显著提升,对自然分布偏移的适应能力远超传统监督训练模型,且视觉编码器(ResNet/ViT)与文本编码器协同优化,兼顾表征能力与迁移灵活性。
3. Li et al. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models(ICML 2023)
方法:提出 “冻结预训练模型 + 轻量桥接模块” 的预训练框架,高效融合冻结图像编码器(如 CLIP)与大语言模型(LLM),解锁复杂跨模态任务能力。
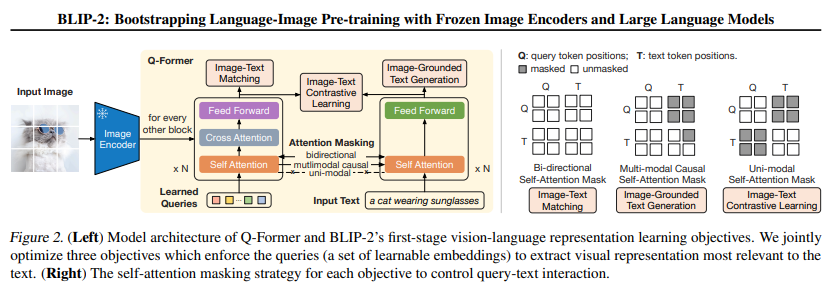
创新点:
- 设计 Querying Transformer 作为桥接模块,无需微调冻结的图像编码器和 LLM,仅训练中间模块即可实现模态对齐,降低计算成本。
- 采用两阶段预训练:第一阶段学习图像 - 文本对齐,第二阶段通过指令微调适配下游任务,兼顾基础表征与任务适配性。
- 首次让冻结 LLM 具备视觉理解能力,在图像描述、视觉问答(VQA)、跨模态对话等任务中实现 state-of-the-art 性能,且迁移性强。
扫码添加小助理,回复“可控生成”
免费获取全部论文+开源代码+数据集+仿真环境
4. Ho et al. Denoising Diffusion Probabilistic Models(DDPM, NeurIPS 2020)
方法:提出基于去噪自编码器堆叠的扩散概率模型,解决生成模型的模式崩溃问题,为后续扩散模型的发展奠定基础。

创新点:
- 定义 “逐步加噪 - 逐步去噪” 的马尔可夫链过程,通过优化变分下界目标,让模型学习数据分布的生成过程。
- 采用参数共享的 UNet 架构作为去噪网络,无需数十亿参数即可建模复杂自然图像分布,避免 autoregressive 模型的序列采样局限。
- 首次证明扩散模型在图像生成、修复、上色等任务中的有效性,且训练稳定,无 GAN 类模型的对抗训练不稳定性问题。
5. Dan Kondratyuk et al. VideoPoet: A Large Language Model for Zero-Shot Video Generation(arXiv 2023)
方法:基于 LLM 架构实现多模态视频生成,突破扩散模型主导的视频生成范式,支持零样本任务迁移与长视频合成。
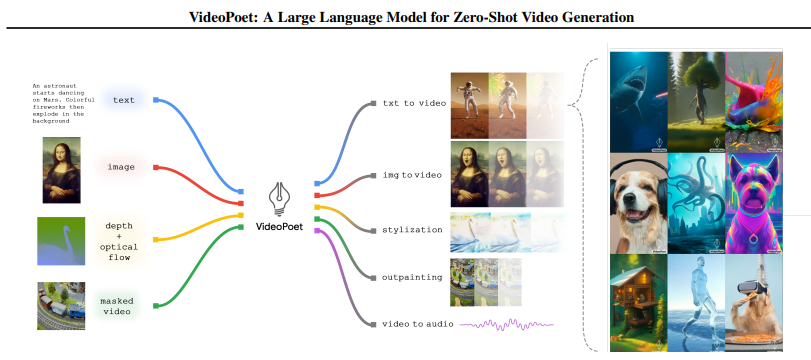
创新点:
- 采用 “模态令牌化 + 统一词汇表” 设计,将图像、视频、音频转换为离散令牌,适配解码器 - only Transformer 架构。
- 两阶段训练:预训练阶段融合多模态生成目标(文本到视频、图像到视频、音频到视频等),任务适配阶段微调特定任务性能,兼顾通用性与专业性。
- 支持零样本视频编辑、风格迁移、长视频 autoregressive 扩展(最长 10 秒),且运动逼真度和时间一致性优于主流扩散类视频模型。
扫码添加小助理,回复“可控生成”
免费获取全部论文+开源代码+数据集+仿真环境








