3.缩放数据集
缩放数据集是确保变量被限制在给定范围内的过程,以确保数据不会分布在较大的区间。在本节中,我们通过将每个输入值除以数据集中的最大可能值,将自变量的值限制在。和1之间。通常,缩放输入数据集能够提高神经网络的性能表现。
from torch.utils.data import Dataset, DataLoader import torch import torch.nn as nn import numpy as np import matplotlib.pyplot as plt from torchvision import datasets
device = "cuda" if torch.cuda.is_available() else "cpu"
data_folder = './data/FMNIST'fmnist = datasets.FashionMNIST(data_folder, download=True, train=True)
tr_images = fmnist.data tr_targets = fmnist.targets
class FMNISTDataset(Dataset): def __init__(self, x, y):
x = x.float() / 255. x = x.view(-1, 28*28) self.x, self.y = x, y
def __getitem__(self, ix): """根据索引 ix 返回一个样本 (图像, 标签)""" x, y = self.x[ix], self.y[ix] return x.to(device), y.to(device)
def __len__(self): """返回数据集总样本数""" return len(self.x)
def get_data(): """创建数据集和 DataLoader,用于批量加载训练数据""" train = FMNISTDataset(tr_images, tr_targets) trn_dl = DataLoader(train, batch_size=32, shuffle=True) return trn_dl
from torch.optim import SGD
def get_model(): """定义模型结构、损失函数和优化器""" model = nn.Sequential( nn.Linear(28*28, 1000), nn.ReLU(), nn.Linear(1000, 10) ).to(device)
loss_fn = nn.CrossEntropyLoss() optimizer = SGD(model.parameters(), lr=1e-2
) return model, loss_fn, optimizer
def train_batch(x, y, model, optimizer, loss_fn): """在一个 batch 数据上执行一次训练步骤(前向传播、损失、反向传播、参数更新)""" model.train()
prediction = model(x)
batch_loss = loss_fn(prediction, y)
batch_loss.backward()
optimizer.step()
optimizer.zero_grad()
return batch_loss.item()
@torch.no_grad() def accuracy(x, y, model): """计算模型在输入 x 上的预测准确率(返回每个样本是否正确)""" model.eval()
prediction = model(x) max_values, argmaxes = prediction.max(-1)
is_correct = argmaxes == y return is_correct.cpu().numpy().tolist()
@torch.no_grad()def val_loss(x, y, model, loss_fn): """计算模型在输入 x 上的损失值(用于验证,但不更新参数)""" prediction = model(x) val_loss = loss_fn(prediction, y) return val_loss.item()
trn_dl = get_data()model, loss_fn, optimizer = get_model()
losses, accuracies = [], []
for epoch in range(10): epoch_losses = [] for ix, batch in enumerate(iter(trn_dl)): x, y = batch batch_loss = train_batch(x, y, model, optimizer, loss_fn) epoch_losses.append(batch_loss) epoch_loss = np.array(epoch_losses).mean()
epoch_accuracies = [] for ix, batch in enumerate(iter(trn_dl)): x, y = batch is_correct = accuracy(x, y, model) epoch_accuracies.extend(is_correct) epoch_accuracy = np.mean(epoch_accuracies)
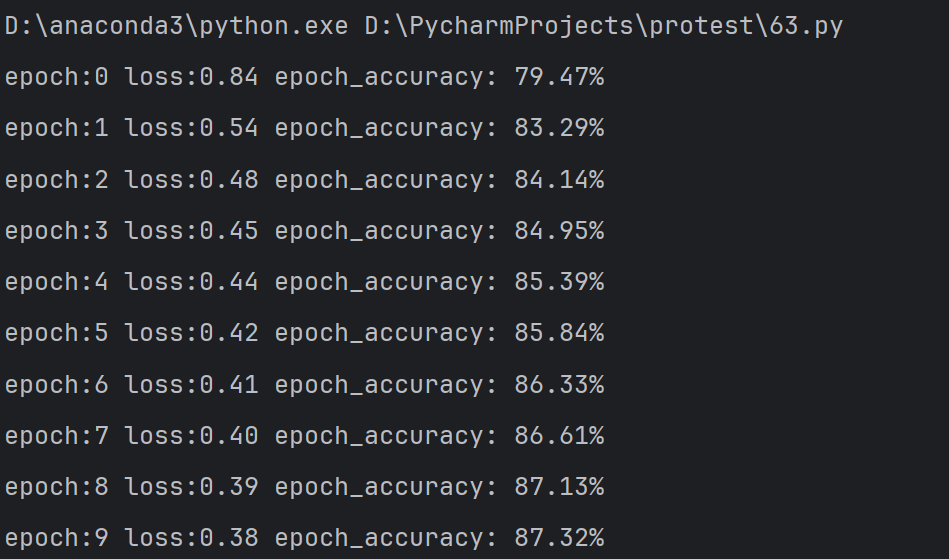
print(f"epoch:{epoch} loss:{epoch_loss:.2f} epoch_accuracy: {epoch_accuracy * 100:.2f}%")
losses.append(epoch_loss) accuracies.append(epoch_accuracy)
epochs = np.arange(10) + 1
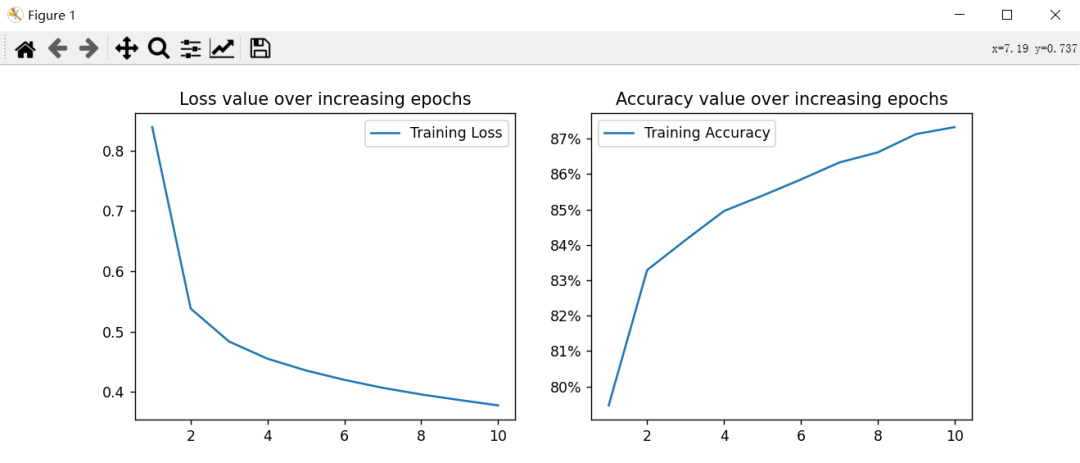
plt.figure(figsize=(20, 5))plt.subplot(121)
plt.title('Loss value over increasing epochs')plt.plot(epochs, losses, label='Training Loss')plt.legend()
plt.subplot(122)plt.title('Accuracy value over increasing epochs')plt.plot(epochs, accuracies, label='Training Accuracy')plt.gca().set_yticklabels(['{:.0f}%'.format(x*100) for x in plt.gca().get_yticks()])plt.legend()
plt.show()
相关:
PyTorch深度学习实战(6)——神经网络性能优化技术(b)
PyTorch深度学习实战(6)—神经网络性能优化技术(a)
PyTorch深度学习实战(5)—计算机视觉基础
PyTorch深度学习实战(4)--常用激活函数和损失函数详解
PyTorch深度学习实战(3)—使用PyTorch构建神经网络(b)
PyTorch深度学习实战(3)—使用PyTorch构建神经网络(a)
PyTorch深度学习实战(2)-PyTorch基础
示例:反向传播和梯度下降的计算过程
AI基础 | 前向传播
AI基础 | 反向传播








