在简单学习了Python爬虫之后,我的下一个目标就是网易云音乐。因为本人平时就是用它听的歌,也喜欢看歌里的评论,所以本文就来爬一爬网易云音乐的评论吧!

首先是找到目标网页并分析网页结构,具体如下:
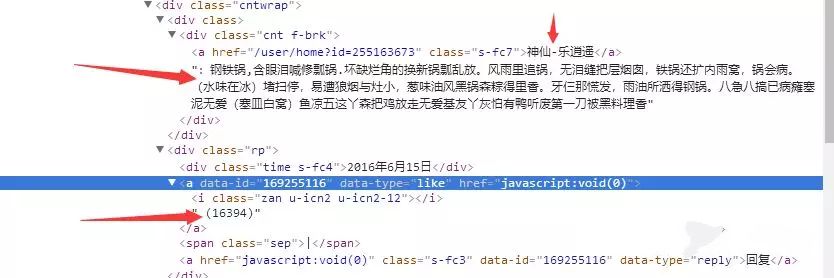
上面的三个箭头就是要找的数据,分别是评论用户、评论和点赞数,都可以用正则表达式找到。接下来用开发者工具继续找下一页的数据,这时候会遇到一个问题,点击下一页的时候网页URL没有变,即说明该网页是动态加载,所以就不能在当前网页找数据了,而应该在XHR文件里找,所以点入Network,再点击下一页,果然有我们想要的。
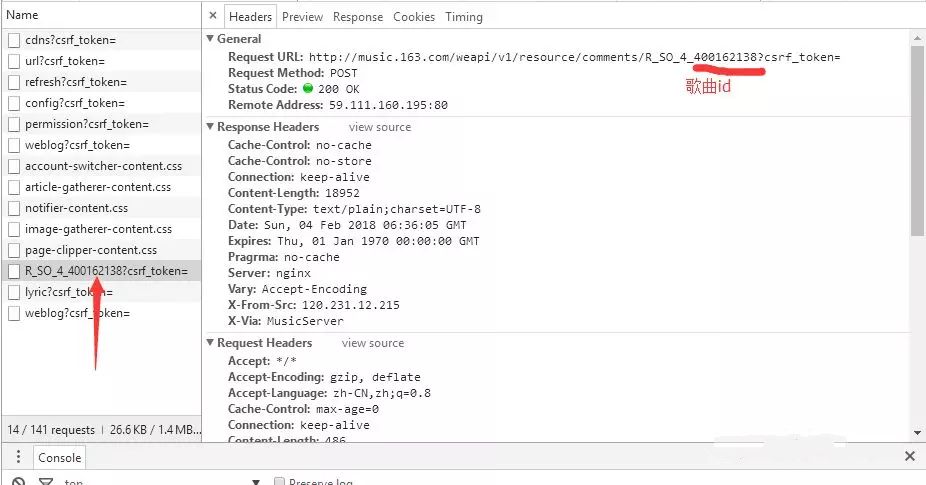
看到这里,就可以兴奋地去敲代码了。
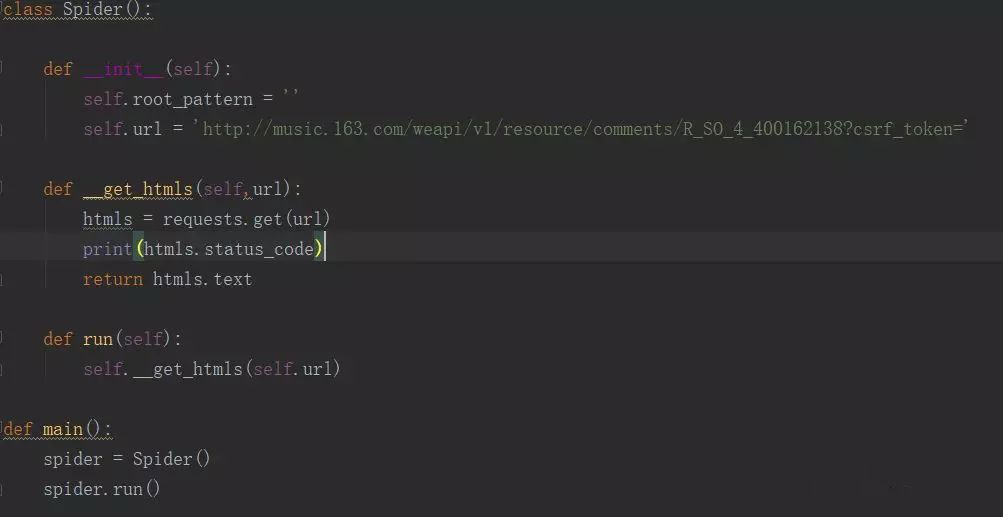
点击运行,却没有得到任何返还结果,这是为何?它的状态码是200,明显请求已成功,却没有东西返回。再去Network仔细看看这个网页,可以看到它是个Post请求,也看到了需要Post两个参数params和ensSecKey。

很明显,这个密密麻麻的数字和字母应该是被加密了,不过可以复制下来看看有没有用。接下来看下它的Response,因为是Json而不是Html结构的,所以现在需要用到Json库来进行解析。
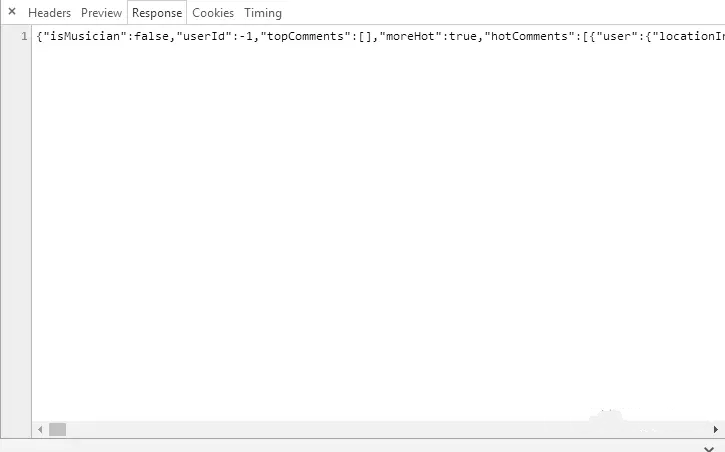
现在开始敲代码吧,先把上面的两个参数复制过来看看:
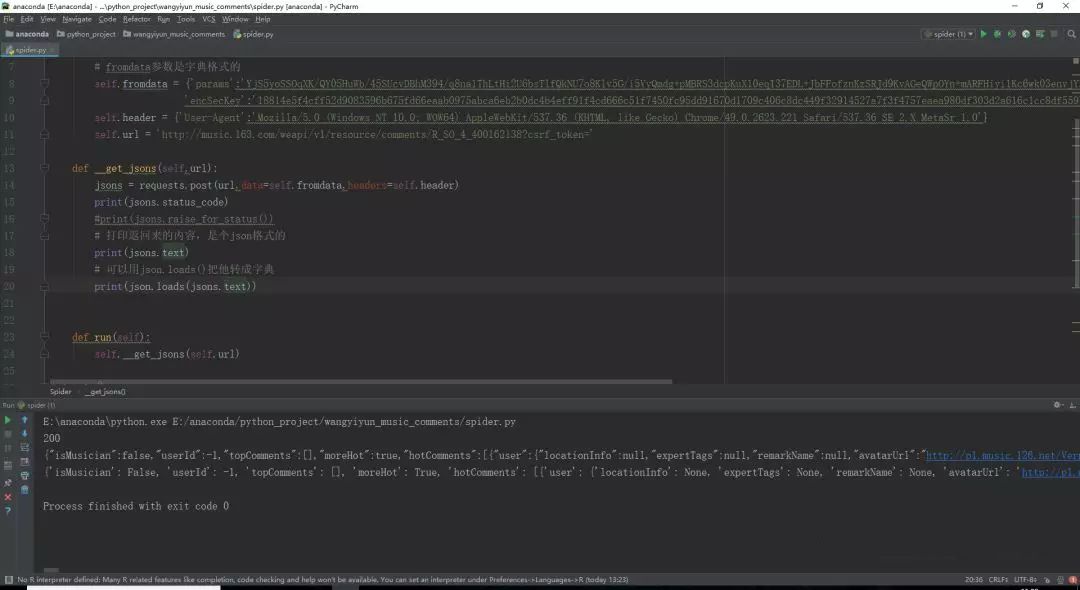
现在把每条评论的评论用户、点赞数和评论获取出来:
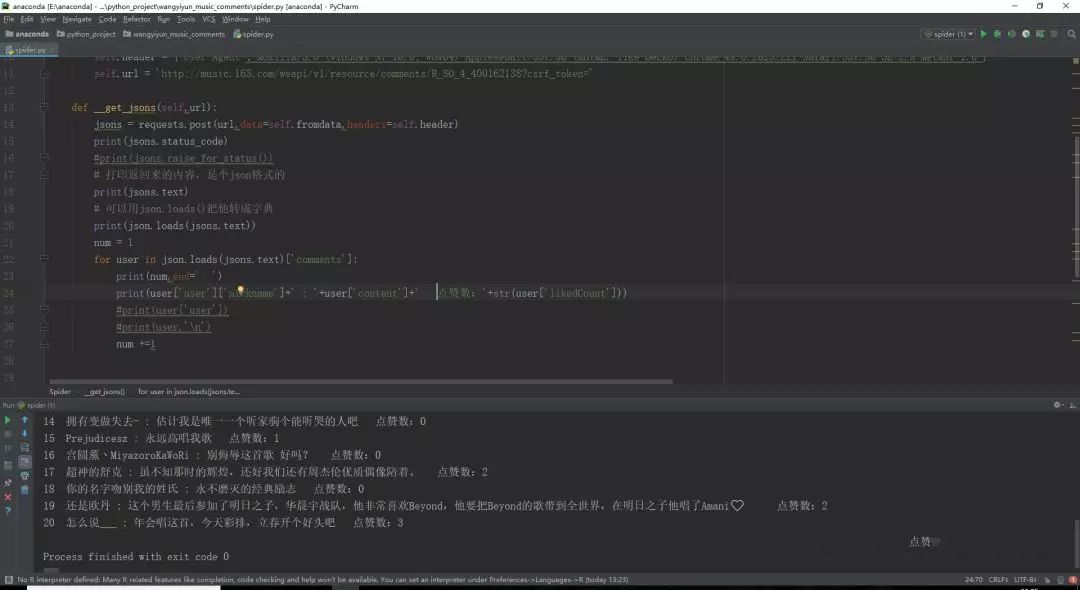
可以看到,利用json.loads()方法把数据转成Python格式里的字典后就可以把想要的数据取出来了。但是,下一页怎样取?总不能每次都复制粘贴那两个参数吧?那唯一的方法就是不爬了?
所以想要继续的话,就只能破解这两个参数了。那下面继续看Network,因为加密肯定要用JS进行加密的。
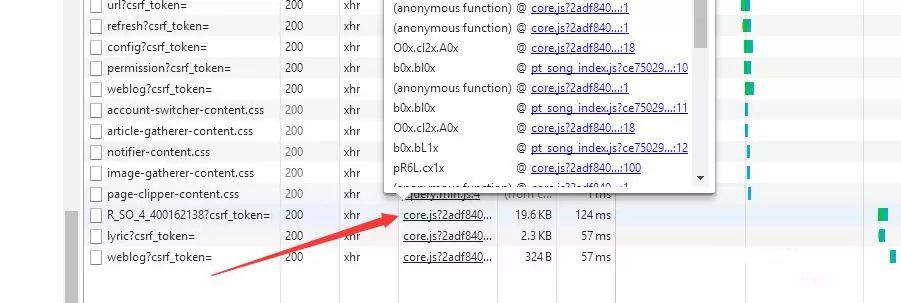
看到刚才那个网站的发起者是core.js,把它的文件下载下来慢慢研究。
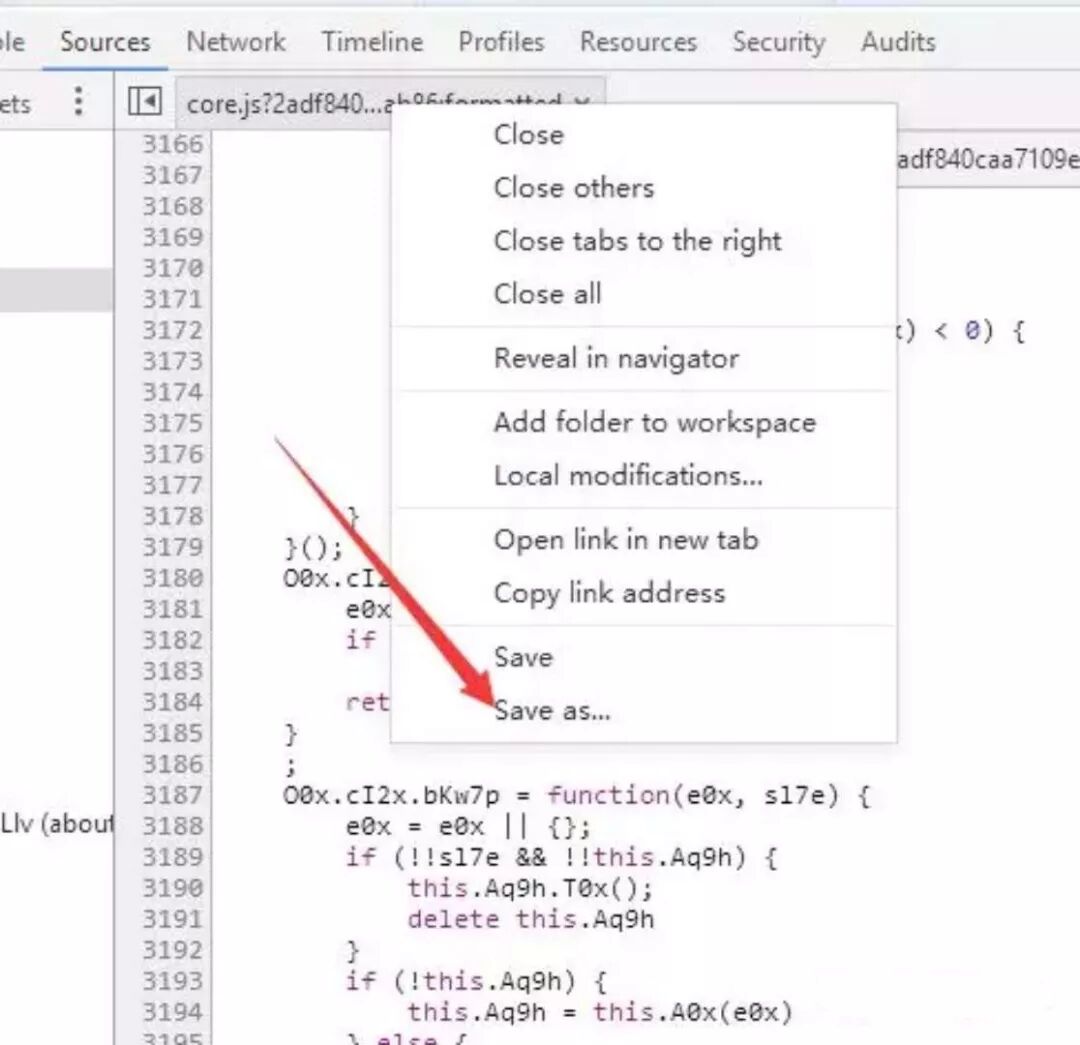
可以看到window.asrsea()方法有四个参数。先不去管这个函数,先看看它的四个参数是什么(这里没必要去研究那四个参数是怎样来的,只需要知道它们分别是什么)。那么可以加点代码让它显示出来,从而利用fiddler调试。
加入的代码如下:

可以分别获取上面的每一个参数,也把那个params获取看看,然后在fiddler上操作如下:
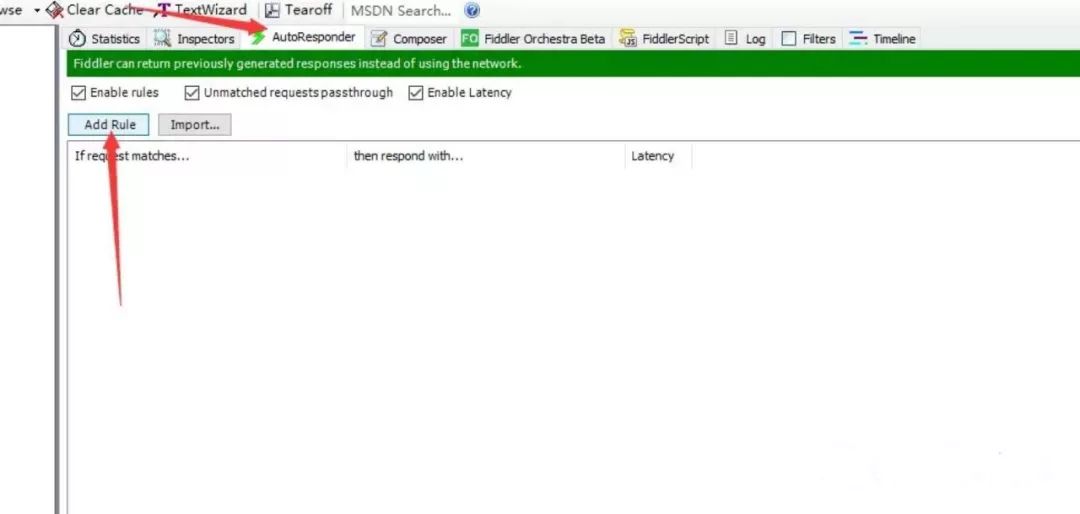

完成上面的设置后刷新网页就可以在console上面找到参数信息,如果没有的话这是因为你之前浏览该网页的时候它被缓存了下来,所以要清除缓存文件(在清除浏览器记录里面有)。
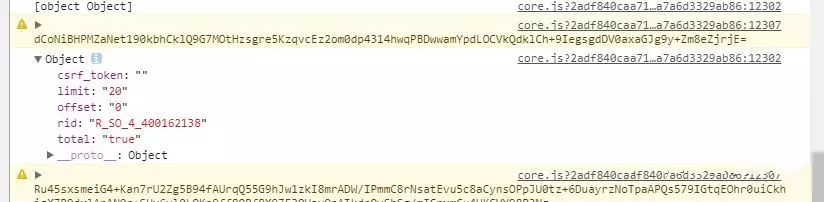
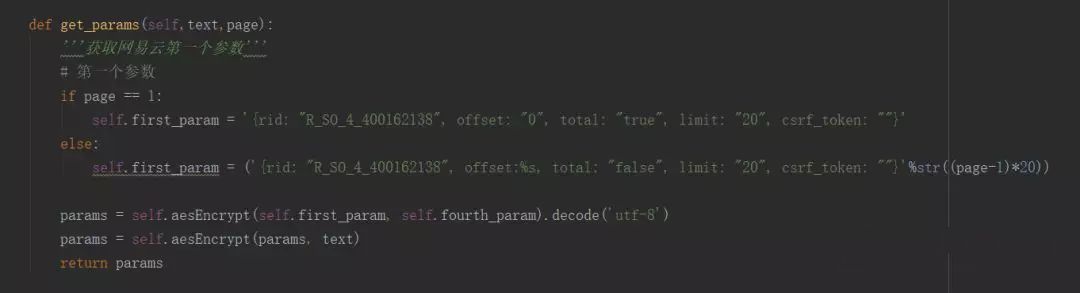
那个rid有本歌曲的id,明显是与评论有关的。我试着连翻几页后,发现offset就是评论偏移数,offset就是(页数-1)*20,total在第一页是true,在其他页是false。

到第二个参数为:010001。第三个参数为:00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7。第四个参数为:0CoJUm6Qyw8W8jud。

找到操作方法
接下来就要看window.asrsea()方法是什么操作的了,通过查找JS文件可以看到这个:

通过研究i是随机获取的十六个字符,而b函数是AES加密,其中偏移量为0102030405060708,模式为CBC。看回d函数,其中params连续两次加密,第一次加密时,文本为第一个参数,密钥为第四个参数;第二次加密时文本为第一次加密的值,密钥为随机数a。而encSeckey是一个RSA加密,它的公钥是第二个参数,模式是第三个参数,文本为那个随机字符串a。

开始敲代码
终于分析完了,下面开始敲代码。先来个获取第一页评论的代码,这是获取两个参数的类:
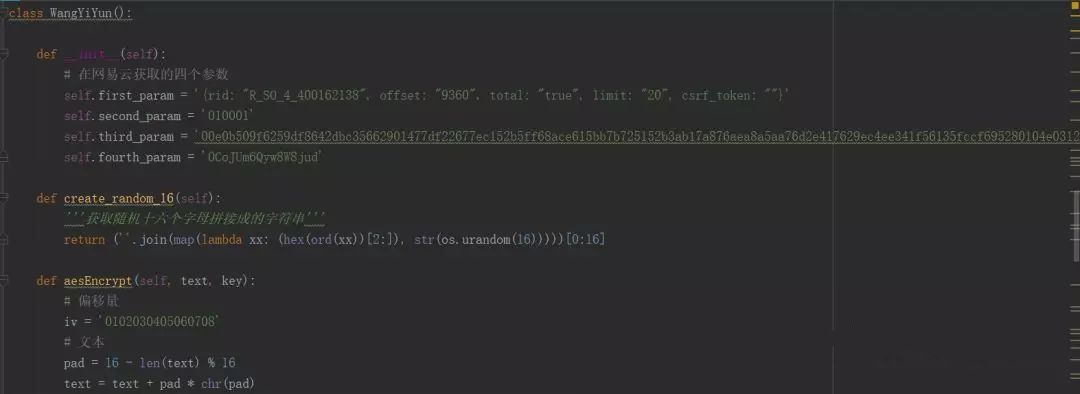
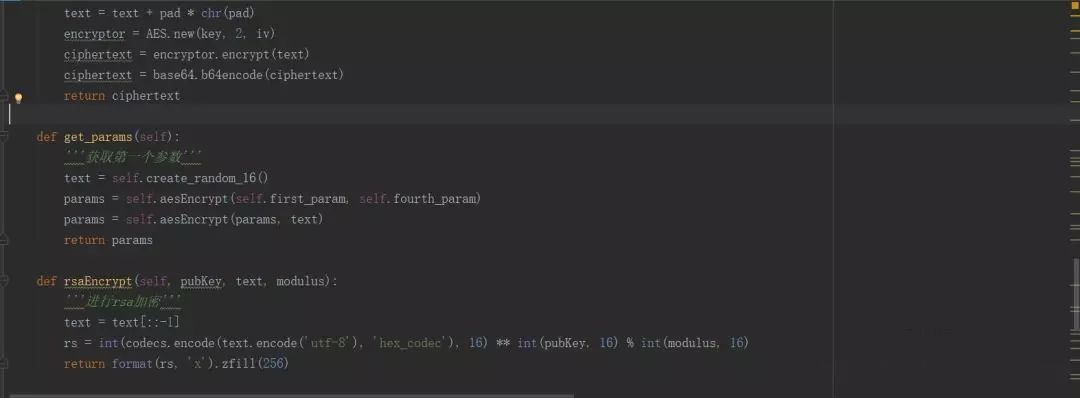
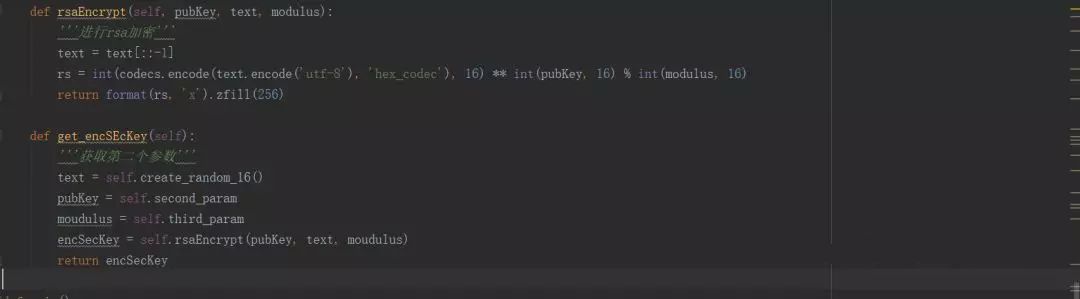
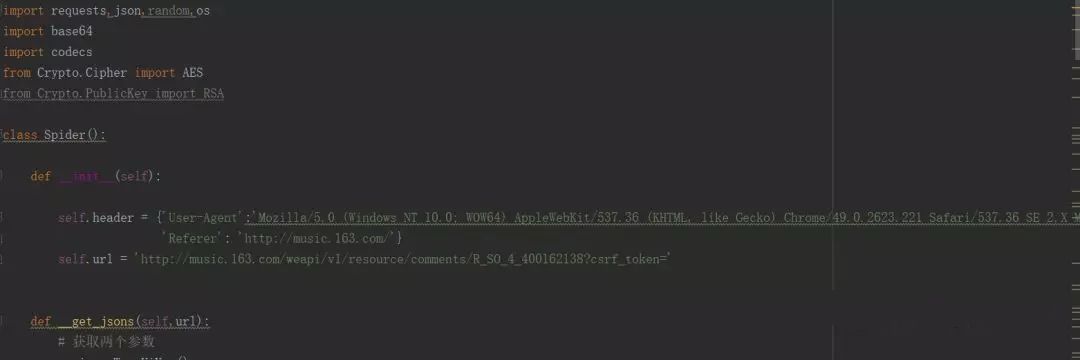
这是解析网易云音乐和获取评论的类:
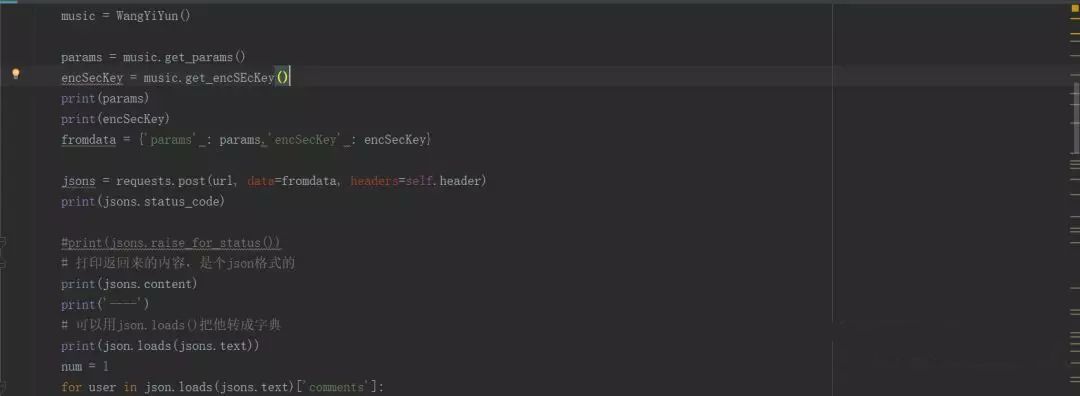
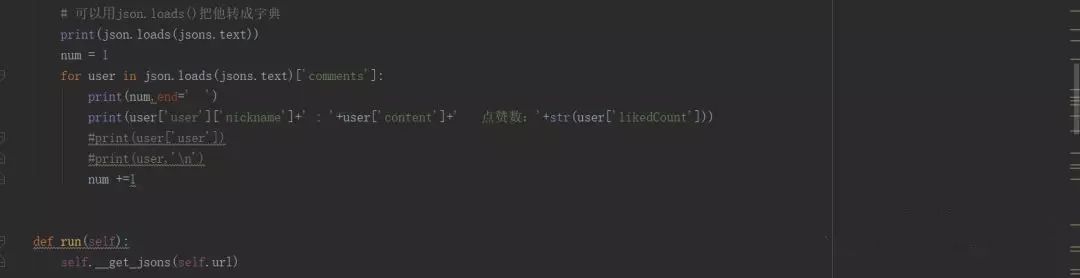
但是一点击运行,直接给我报了个错:TypeError: can't concat str to bytes。

原来是因为在第二次加密的时候,那个params是个byte类型,所以把它转成字符串类型就可以了:

再次点击运行,结果还是报错了:json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)。
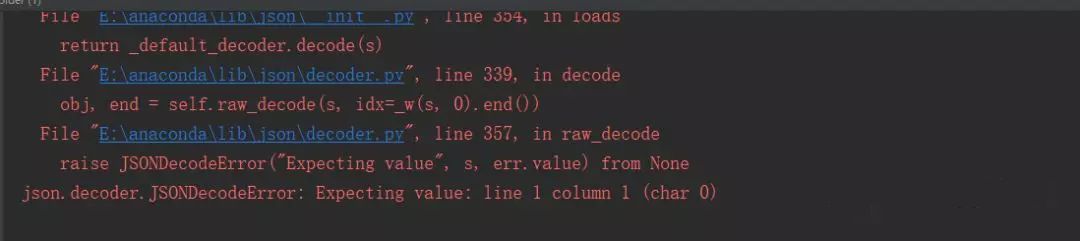
这个报错是因为我的Json解析错了,回头调试一看,网页返回的东西是空的,但它的状态码还是200。这是什么鬼?
接着我再试了把那两个参数的值直接复制和前面一样看看,结果运行成功,这就说明是我的加密过程错了。然后我就回去看了几遍,仍没有看出什么错误,后来我上网百度找到了这个知乎文章https://zhuanlan.zhihu.com/p/32069543,我把她的代码复制过来运行下,结果是可以的。我就继续看看我和她的区别,原来我在用那个16个随机字符的时候用错了,对两个参数给了两个不同的,但其实是需要给同一个的。看到这里,我就直接回去改了下,果然运行成功。效果如下:


获取每一页的评论
接着是获取每一页的评论。每一页与第一个参数的offset有关,其中的公式为offse=(页数-1)*20,total在第一页是true,在其他页是false。
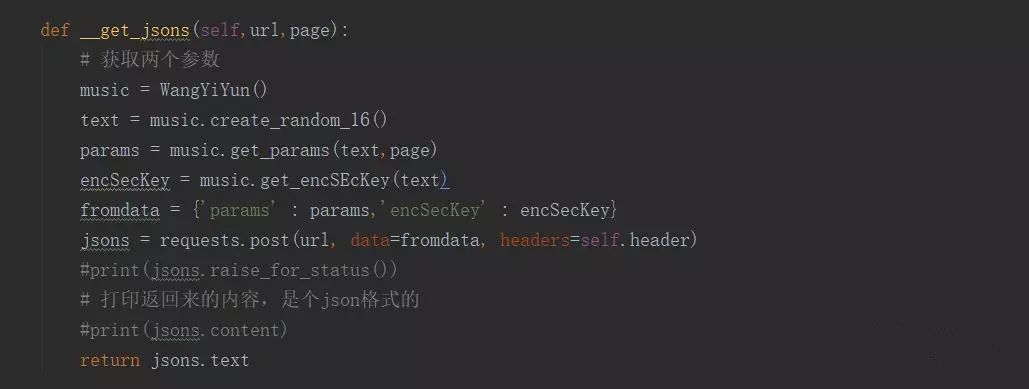
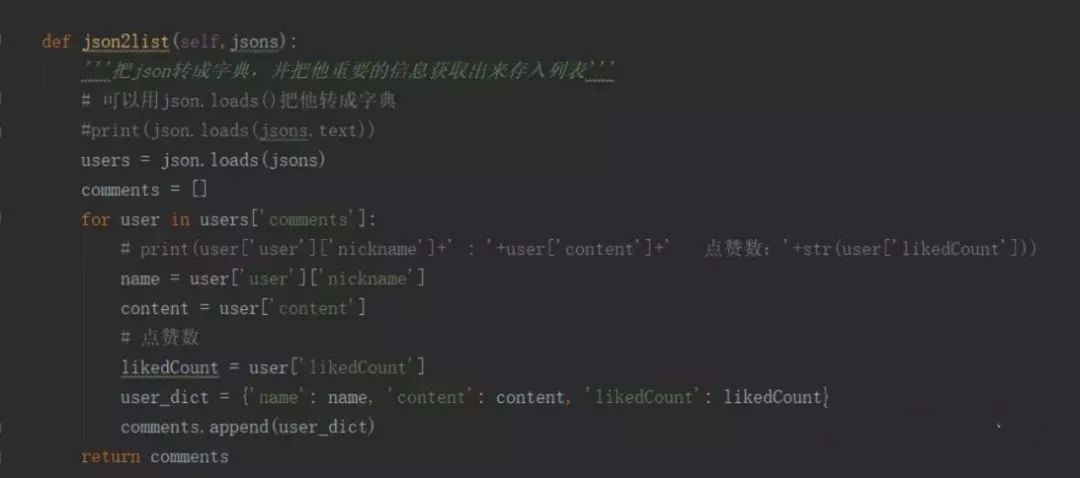
而写入数据库我用的是我在这篇文章中写到过的操作。由于篇幅过长,就不贴出来了,感兴趣的可以去看看。
接下来点运行就可以了,但是运行到第八页的时候出现了这个异常:
raise errorclass(errno, errval)
pymysql.err.InternalError: (1366, "Incorrect string value: '\xF0\x9F\x92\x94' for column 'content' at row 1")
原因是这条评论有个识别不了的表情。之后参考其他文章,修改了数据库的编码方式,注意还要自己修改下创建数据库时的编码方式才可以!
这是首页数据库效果:
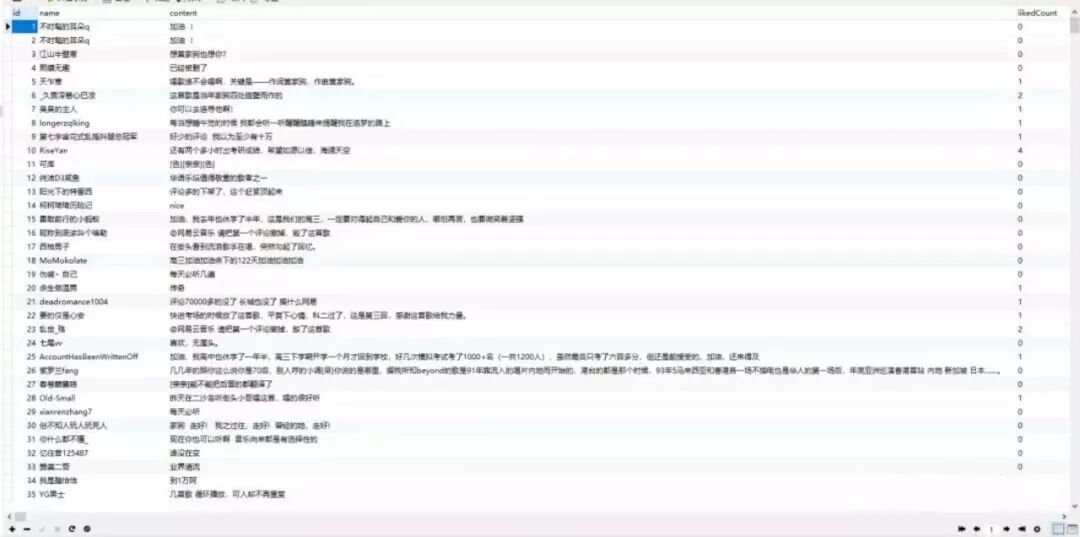
获取完成(家驹的歌评论这么少吗?不解):

作者:sergiojune,一个热爱折腾Python的学者。本文为作者投稿,首发于作者个人公众号日常学python,版权归对方所有。
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱(guorui@csdn.net)。