

作者 | 丁彦军
昨天还幻想海边别墅的年轻人,今天可能开始对房租绝望了。
8 月初,有网友在“水木论坛”发帖控诉长租公寓加价抢房引起关注。据说,一名业主打算出租自己位于天通苑的三居室,预期租金 7500 元/月,结果被二方中介互相抬价,硬生生抬到了 10800。
过去一个月,全国热点城市的房租如脱缰野马。一线的房租同比涨了近 20%。一夜醒来,无产青年连一块立锥之地都悬了。
从 2018 下半年开始,租金海啸汹汹来袭,资本狂欢,官方默然,房东纠结,租客尖叫。
这不是一方的过错,而更像是一场全社会的“集体谋杀作品”。最令人不安的是,过去房地产的那套玩法和上涨逻辑,今天正在转移到房租上。
房租暴涨的不只是北京。有数据显示,7 月份北京、上海、广州、深圳、天津、武汉、重庆、南京、杭州和成都十大城市租金环比均有所上涨。其中北京、上海、深圳的租金涨幅最猛,北京 7 月份房租同比上涨 3.1%,有小区甚至涨幅超过 30%。
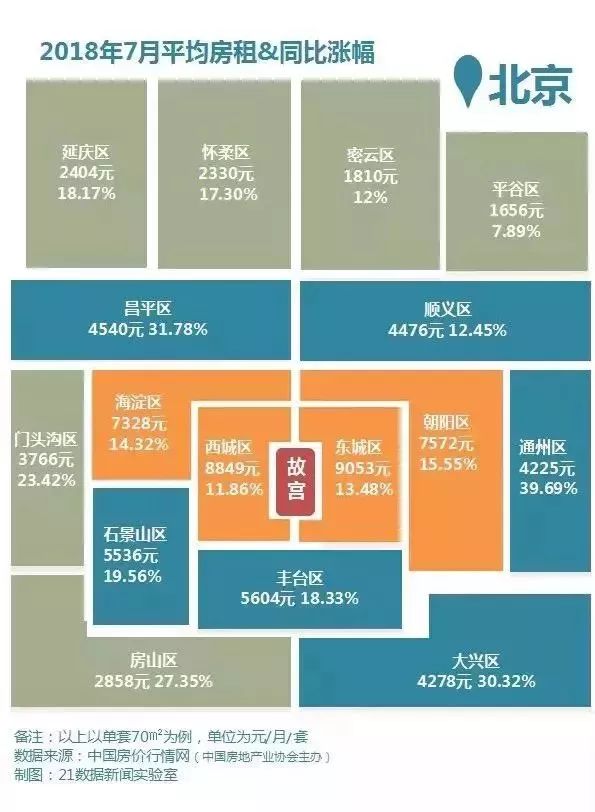
图自“21 世纪经济报道”《最新房租数据出炉,你一个月要交多少钱?(附房租地图)》一文
接下来,笔者通过 Python 获取某网数万条北京租房数据,给大家说说真实的房租情况。
还是老规矩,老套路(是不是有股熟悉的味道),笔者常用的三部曲:数据获取、数据清洗预览、数据分析可视化,与你一起探究最近房租的状况。

数据获取
笔者今天就把目前市场占有率最高的房屋中介公司为目标,来获取北京、上海两大城市的租房信息。
目标链接:https://bj.lianjia.com/zufang/
整体思路是:
post 代码之前简单讲一下这里用到的几个爬虫 Python 包:
详细代码如下:
import requests
import time
import re
from lxml import etree
def get_areas(url):
print('start grabing areas')
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
resposne = requests.get(url, headers=headers)
content = etree.HTML(resposne.text)
areas = content.xpath("//dd[@data-index = '0']//div[@class='option-list']/a/text()")
areas_link = content.xpath("//dd[@data-index = '0']//div[@class='option-list']/a/@href")
for i in range(1,len(areas)):
area = areas[i]
area_link = areas_link[i]
link = 'https://bj.lianjia.com' + area_link
print("开始抓取页面")
get_pages(area, link)
def get_pages(area,area_link):
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
resposne = requests.get(area_link, headers=headers)
pages = int(re.findall("page-data=\'{\"totalPage\":(\d+),\"curPage\"", resposne.text)[0])
print("这个区域有" + str(pages) + "页")
for page in range(1,pages+1):
url = 'https://bj.lianjia.com/zufang/dongcheng/pg' + str(page)
print("开始抓取" + str(page) +"的信息")
get_house_info(area,url)
def get_house_info(area, url):
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
time.sleep(2)
try:
resposne = requests.get(url, headers=headers)
content = etree.HTML(resposne.text)
info=[]
for i in range(30):
title = content.xpath("//div[@class='where']/a/span/text()")[i]
room_type = content.xpath("//div[@class='where']/span[1]/span/text()")[i]
square = re.findall("(\d+)",content.xpath("//div[@class='where']/span[2]/text()")[i])[0]
position = content.xpath("//div[@class='where']/span[3]/text()")[i].replace(" ", "")
try:
detail_place = re.findall("([\u4E00-\u9FA5]+)租房", content.xpath("//div[@class='other']/div/a/text()")[i])[0]
except Exception as e:
detail_place = ""
floor =re.findall("([\u4E00-\u9FA5]+)\(", content.xpath("//div[@class='other']/div/text()[1]")[i])[0]
total_floor = re.findall("(\d+)",content.xpath("//div[@class='other']/div/text()[1]")[i])[0]
try:
house_year = re.findall("(\d+)",content.xpath("//div[@class='other']/div/text()[2]")[i])[0]
except Exception as e:
house_year = ""
price = content.xpath("//div[@class='col-3']/div/span/text()")[i]
with open('链家北京租房.txt','a',encoding='utf-8') as f:
f.write(area + ',' + title + ',' + room_type + ',' + square + ',' +position+
','+ detail_place+','+floor+','+total_floor+','+price+','+house_year+'\n')
print('writing work has done!continue the next page')
except Exception as e:
print( 'ooops! connecting error, retrying.....')
time.sleep(20)
return get_house_info(area, url)
def main():
print('start!')
url = 'https://bj.lianjia.com/zufang'
get_areas(url)
if __name__ == '__main__':
main()

数据清洗预览
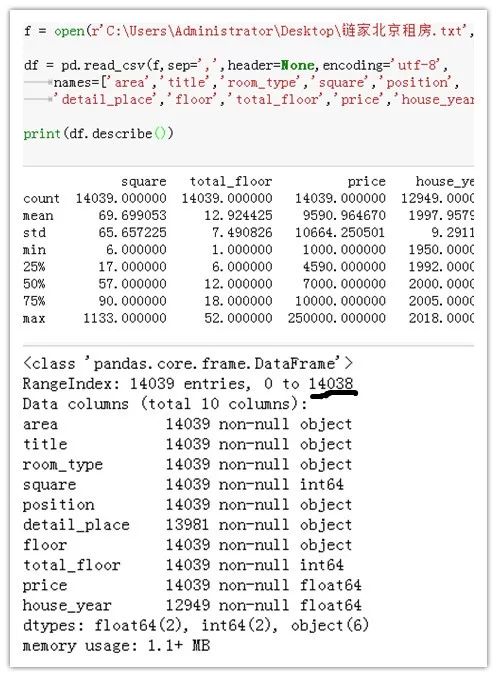
数据共 14038 条,10 个维度,由上图可看出北京房源均价为 9590 元/月,中位数为 7000。一半的房源价格在 7000 以下,所有房源的价格区间为[1000,250000],价格极差过大。

数据分析可视化
接下来,笔者将北京各区域、各路段、各楼盘房屋数量、均价分布放在同一张图上,更直观地来看待房租。
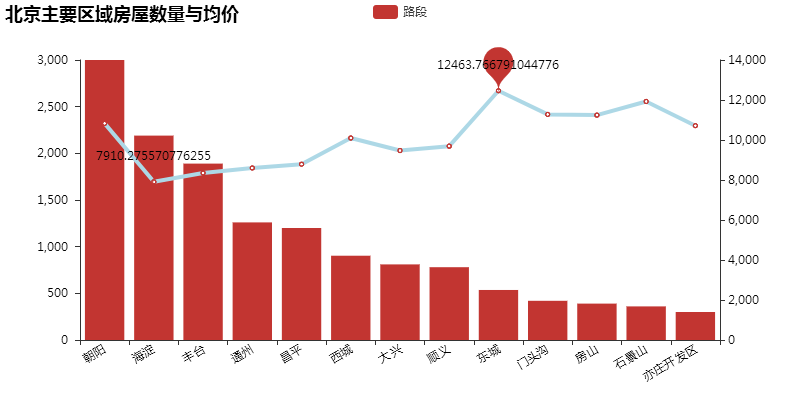
从图中可看出,最近,北京市各区域的房租均在 6000 元/月以上,其中最高区域为东城,均价达 12463 元/月。不过,由于房源信息过多过杂,房屋位置、面积、楼层、朝向等对价格均有较大影响,因此,价格这个维度需要进一步分析。
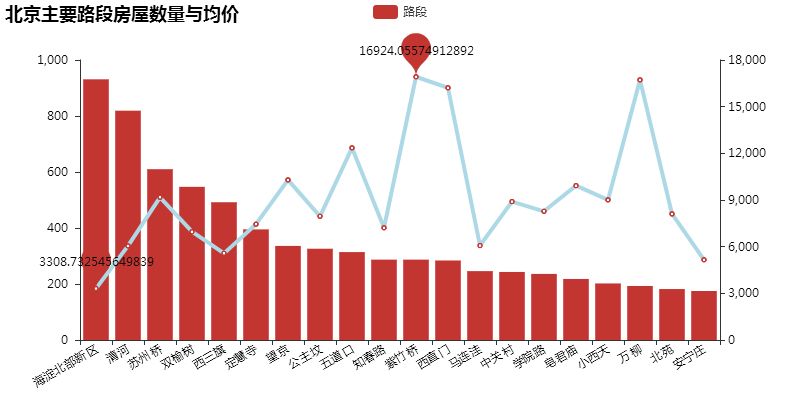
由上图可得,各路段的均价基本都在 6000 以上,其中海淀北部新区的房源数最多,但均价最低,为 3308 元/月,这或许与海淀北部生态科技新区作为高新技术产业的承载区、原始创新策源地的研发基地,以及科技园集聚区,目前已入驻华为、联想、百度、腾讯、IBM、Oracle 等近 2000 家国内外知名的科技创新型企业有关。另一方面,海淀紫竹桥的房价竟一起冲天,其附近以博物馆、体育场馆为特色,交通便利,配套设施完善,均价较高也是情理之中。
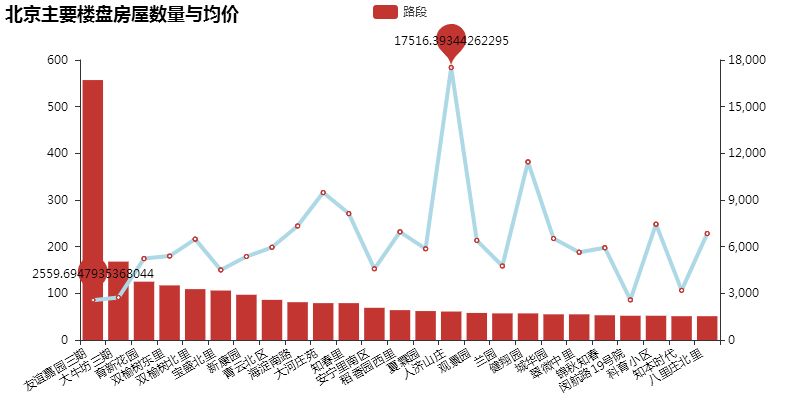
可以看出,不同楼盘的均价浮动很大,但都在 6000/月以上。最高的甚至达到 17516/月。由于每个楼盘户型差别较大,地理位置也较为分散,因此均价波动很大。每个楼盘具体情况还需具体分析。
附详情代码:
detail_place = df.groupby(['detail_place'])
house_com = detail_place['price'].agg(['mean','count'])
house_com.reset_index(inplace=True)
detail_place_main = house_com.sort_values('count',ascending=False)[0:20]
attr = detail_place_main['detail_place']
v1 = detail_place_main['count']
v2 = detail_place_main['mean']
line = Line("北京主要路段房租均价")
line.add("路段",attr,v2,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
mark_point=['min','max'],xaxis_interval=0,line_color='lightblue', line_width=4,mark_point_textcolor='black',mark_point_color='lightblue',
is_splitline_show=False)
bar = Bar("北京主要路段房屋数量")
bar.add("路段",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
xaxis_interval=0,is_splitline_show=False)
overlap = Overlap()
overlap.add(bar)
overlap.add(line,yaxis_index=1,is_add_yaxis=True)
overlap.render('北京路段_房屋均价分布图.html')
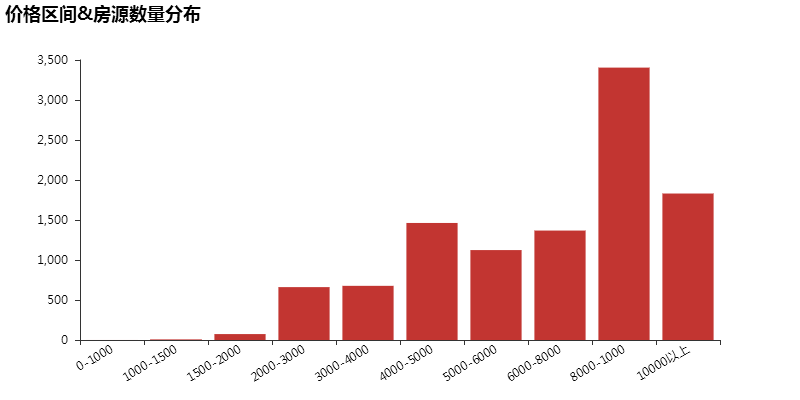
由上图可以看出,均价在 8000-10000 之间的房屋数量最多,同时 1500-2000 这个价位之间房屋数少的可怜。
据北京市统计局的数据,2017 年全市居民月人均可支配收入为 4769 元。另据 58 同城和赶集网发布的报告,2017 年北京人均月租金为 2795 元。
北京租房者的房租收入比,惊人地接近 60%。很多人一半的收入,都花在了租房上,人生就这样被锁定在贫困线上。
统计数据也表明,北京租房人群收入整体偏低。47%的租房人,年薪在 10 万以下。在北京,能够负担得起每月 5000 元左右房租的群体,就算得上是中高收入人群。就这样,第一批 90 后扛过了离婚、秃头、出家和生育,终于还是倒在了房租面前。
附详情代码:
#房源价格区间分布图
price_info = df[['area', 'price']]
#对价格分区
bins = [0,1000,1500,2000,2500,3000,4000,5000,6000,8000,10000]
level = ['0-1000','1000-1500', '1500-2000', '2000-3000', '3000-4000', '4000-5000', '5000-6000', '6000-8000', '8000-1000','10000以上']
price_stage = pd.cut(price_info['price'], bins = bins,labels = level).value_counts().sort_index()
attr = price_stage.index
v1 = price_stage.values
bar = Bar("价格区间&房源数量分布")
bar.add("",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
xaxis_interval=0,is_splitline_show=False)
overlap = Overlap()
overlap.add(bar)
overlap.render('价格区间&房源数量分布.html')
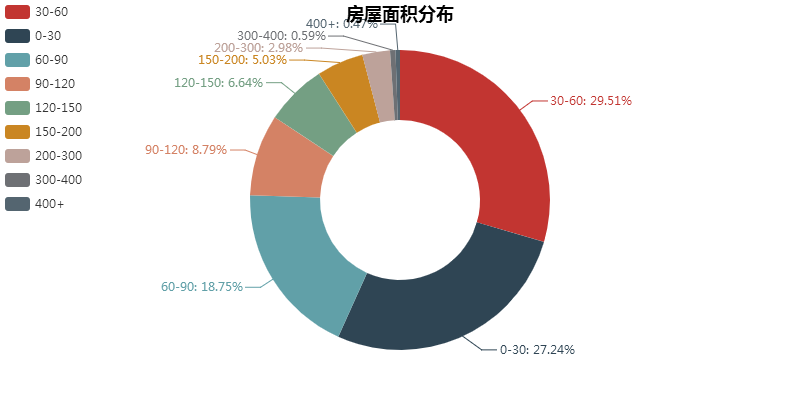
上图可以看出,80%的房源面积集中在 0-90 平方米之间,也符合租客单租与合租情况,大面积的房屋很少。
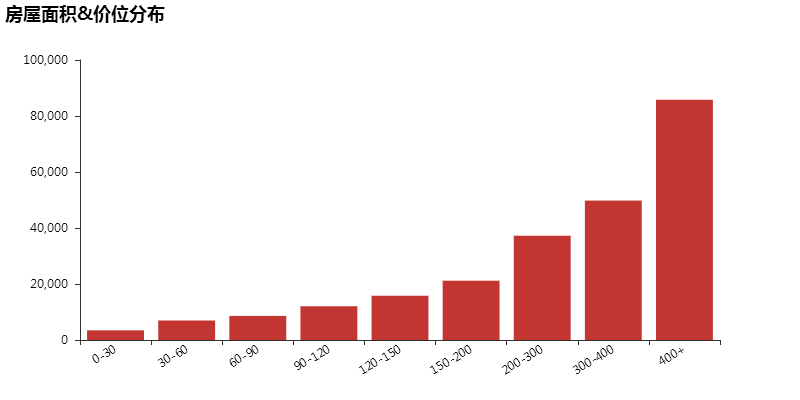
面积&租金分布呈阶梯性,比较符合常理。租房主力军就是上班族了,一般对房子面积要求较低,基本集中在 30 平。
附详情代码:
#房屋面积分布
bins =[0,30,60,90
,120,150,200,300,400,700]
level = ['0-30', '30-60', '60-90', '90-120', '120-150', '150-200', '200-300','300-400','400+']
df['square_level'] = pd.cut(df['square'],bins = bins,labels = level)
df_digit= df[['area', 'room_type', 'square', 'position', 'total_floor', 'floor', 'house_year', 'price', 'square_level']]
s = df_digit['square_level'].value_counts()
attr = s.index
v1 = s.values
pie = Pie("房屋面积分布",title_pos='center')
pie.add(
"",
attr,
v1,
radius=[40, 75],
label_text_color=None,
is_label_show=True,
legend_orient="vertical",
legend_pos="left",
)
overlap = Overlap()
overlap.add(pie)
overlap.render('房屋面积分布.html')
#房屋面积&价位分布
bins =[0,30,60,90,120,150,200,300,400,700]
level = ['0-30', '30-60', '60-90', '90-120', '120-150', '150-200'
, '200-300','300-400','400+']
df['square_level'] = pd.cut(df['square'],bins = bins,labels = level)
df_digit= df[['area', 'room_type', 'square', 'position', 'total_floor', 'floor', 'house_year', 'price', 'square_level']]
square = df_digit[['square_level','price']]
prices = square.groupby('square_level').mean().reset_index()
amount = square.groupby('square_level').count().reset_index()
attr = prices['square_level']
v1 = prices['price']
pie = Bar("房屋面积&价位分布布")
pie.add("", attr, v1, is_label_show=True)
pie.render()
bar = Bar("房屋面积&价位分布")
bar.add("",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
xaxis_interval=0,is_splitline_show=False)
overlap = Overlap()
overlap.add(bar)
overlap.render('房屋面积&价位分布.html')
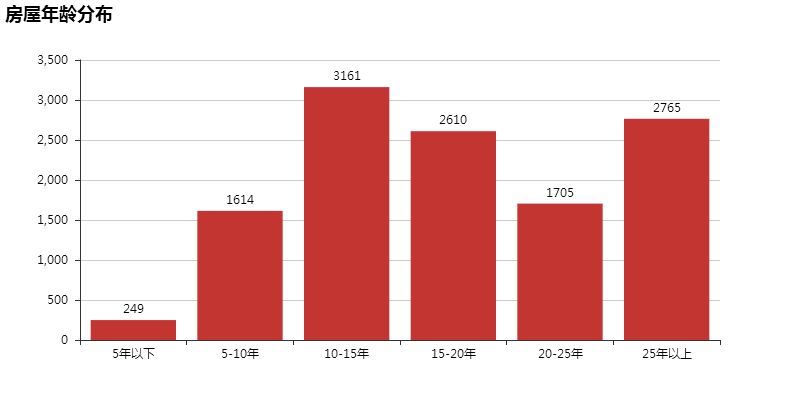
由上图看出,房屋年龄大多集中在 10-20 年、25 年以上,而 5 年以下的不到 2%;不过,别看这些都是老房子,最近房租变得这么猖狂?原因其中之一就是资本圈地。

这条网贴立马点燃了大众的情绪:“好啊,原来是这些长租平台烧钱圈地,一心只想要垄断市场房源,哄抬租金,企图赚取暴利差价!”

后记
拿自如举例,表面上看跟中介公司没啥两样,收了各种散盘,然后集中装修、出租、管理,因为运营成本和住房质量提高,房租肯定有所上涨。
但更关键的事情在背后。自如把项目打包起来搞起了资产证券化,以租金收益权为基础资产做担保,投放到金融市场上发行国内首单租房市场消费分期类 ABS,让各路资金来认购,每年给大家搞点分红。
大量资本都在赌租房这个风口,而前期谁的规模越大、资源越多,以后的定价权就越大,利润空间就越不可想象。
这次笔者一共从链家网上爬取 14038 条数据,而那就是大概一周前,8 月 17 日北京住建委约谈了几家中介公司。最终的结果是自如、相寓和蛋壳承诺将拿出 12 万间房子投入市场其中,自如将拿出 8 万间(链家、自如、贝壳找房),他们的实际控制人是同一个人 —— 链家老板左晖。

也就是说,平常的时候,链家网+自如一共在网上待租的也就是 1 万多套房子,但是一被约谈他们就一口气拿出了 8 万套房子增援??怎么增?继续收房,让房源更加供不应求?
昨天买不起房,今天租不起房,如果连这样的生活也要因为市场的不规范而被逼迫、被夺走,真的会让人对一个城市失去希望。
声明:本文为作者投稿,版权归对方所有。作者独立观点,不代表 CSDN 立场。
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱(guorui@csdn.net)。












