机器学习中最值得问的一个问题是,到底需要多少数据才可以得到一个较好的模型?从理论角度,有Probably approximately correct (PAC) learning theory来描述在何种情况下,可以得到一个近似正确的模型。但从实用角度看,PAC的使用范围还是比较局限的。
所以今天我们主要想讨论一个问题:到底如何定义有效数据量。
数据的粒度可以理解为数据的细分程度,或者具体程度。举个简单例子,我们想预测股票的走势,那么我们可以得到以下历史数据:
每秒钟的交易数据
每分钟的交易数据
...
每年的交易数据
换成另一个场景,如果我们打算对一个句子进行截断,“我今天真高兴”,那么结果可以是:
我 | 今 | 天 | 真 | 高 | 兴
我今 | 今天 | 天真 | 真高 | 高兴
我今天 | 天真高 | 高兴X
随着细分程度的改变,那么数据量也有明显的变化。数据的粒度越细,数据量越大。一般来说,我们追求尽量细分的数据,因为可以通过聚合(aggregation)来实现从具体数据到宏观数据的还原,但反之则不可得。
但是不是数据越具体越好?不一定,过于具体的数据缺失了特征,有效的特征仅在某个特定的粒度才存在。打个比方,人是由原子、分子、细胞、组织、器官构成,但在分子层面我们不一定能分辨它是人,只有到达一定的粒度才可以。因此,数据收集的第一个重点是搞清楚,在什么粒度可以解决我们的问题,而不是盲目的收集一大堆数据,或者收集过于抽象的数据。
机器学习中对于数据的表达一般是 n*m的矩阵,n代表样本的数量,一行(row)数据代表一个独立数据。
而m代表特征变量(attribute/feature/variable)的数量,一列(column)数据代表某个特征在所有样本上的数值。比如下图就代表了一个 4*2(n=4,m=2)的矩阵,即总共有4条数据,每个数据有2个特征。

人们讨论数据量,往往讨论的是n,也就是有多少条数据。但这个是不准确的,因为更加适合的评估应该是n/m,也就是样本量除以特征数,原因很简单。如果你只有100条数据,但只有2个特征。如果用线性函数来拟合,相当于给你100个点来拟合到二次函数上,这个数据量一般来说是比较充裕的。但还是100个数据点,每个数据的特征数是200,那么很明显你的数据是不够的,过拟合的风险极高。
所以谈论数据量,不能光说有多少条数据n,一定也要考虑数据的特征数m。
前文所有的讨论都建立在一个标准上,那就是我们选择的数据是有效的。从两个方向理解:
数据间的重复性低:

数据的有效性:此处的有效性指的是你的变量对于解决问题有帮助,而不是完全无关或者关联性极低的数据。不要小看无关数据,几乎无处不在。拿我常举的例子来说:
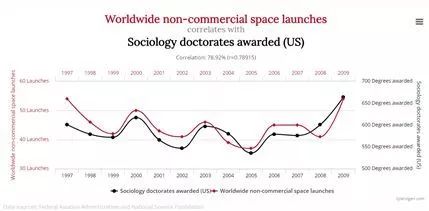 图1. 全球非商业性空间飞船发射数量与美国社会学博士毕业数量之间的关系[1]
图1. 全球非商业性空间飞船发射数量与美国社会学博士毕业数量之间的关系[1]承接上一个部分,数据比模型更重要,数据重要性 >> 模型重要性。机器学习模型的表现高度依赖于数据量 [2],选择对的模型只是其次,因为巧妇难为无米之炊。
但数据不是越多越好,随机数据中也可能因为巧合而存在某种关联。Freedman在1989年做过的模拟实验 [3]中发现,即使数据全是由噪音构成,在适当的处理后,也能发现数据中显著的相关性:a. 6个特征显著 b. 对回归的做F-test的p值远小于0.05,即回归存在统计学意义
以此为例,大量数据不代表一定有显著的意义,即使相关性检验也不能证明这一点。一般来说,需要先确认数据的来源性,其次要确认显著的特征是否正常,最后需要反复试验来验证。最重要的是,要依据人为经验选取可能有关的数据,这建立在对问题的深入理解上。更多相关的讨论可以参考 微调:你实践中学到的最重要的机器学习经验是什么?。
一般来说,在大数据量小特征数时,简单模型如逻辑回归+正则即可。在小数据量多特征下,集成的树模型(如随机森林和xgboost)往往优于神经网络。随着数据量增大,两者表现趋于接近,随着数据量继续上升,神经网络的优势会逐步体现。
随着数据量上升,对模型能力的要求增加而过拟合的风险降低,神经网络的优势终于有了用武之地而集成学习的优势降低。我在微调:怎么理解决策树、xgboost能处理缺失值?而有的模型(svm)对缺失值比较敏感呢? 曾经总结过一些根据数据量选择模型的经验:
所以说到底,依然不存在定式,而依赖于经验和理解,供大家参考。
写这篇的文章的起因是来自 @刘文龙和 @陈小一关于机器学习在水环境中应用时数据量的讨论(详见他们的知乎想法)。此处也特别感谢 @张馨宇
在评论区关于信噪比的讨论,这对于衡量数据质量也很重要。
[1] http://tylervigen.com/spurious-correlations
[2] Halevy, A., Norvig, P. and Pereira, F., 2009. The unreasonable effectiveness of data. IEEE Intelligent Systems, 24(2), pp.8-12.
[3] Freedman, L.S. and Pee, D., 1989. Return to a note on screening regression equations. The American Statistician, 43(4), pp.279-282.
作者:微调
知乎专栏:数据说 阅读原文即可关注
推荐阅读:
推荐几个高质量技术公众号!
【学术福利】Pytorch的tensorboard食谱帮你可视化误差结果
通俗易懂讲解感知机(三)--收敛性证明与对偶形式以及python代码讲解

知乎:忆臻












