GPU和FPGA如何帮助执行数据密集型任务,例如操作,分析和机器学习,以及有哪些选择?
应用程序和基础架构在逐步发展。这是人工智能再生的时代,基础设施既可以使人工智能应用程序理解世界,也可以不断发展以更好地满足需求。
通常情况下,我们已经设想了为AI应用程序提供动力的新基础架构,并且在它完全成熟之前给出了名称 ------ Infrastructure 3.0。我们也开始探索堆栈中多方面组成部分,包括哪些明显的、不那么明显的,以及其他部分。
为了易于阐述,本文将聚焦“具有许多计算核心和高带宽内存的专用硬件”,简称AI芯片。我们来看看这些AI芯片如何在数据库和分析以及机器学习(ML)方面使以数据为中心的任务受益。
让我们从GPU和FPGA来开启这篇文章的介绍。
GPU
图形处理单元(GPU)已经存在了一段时间。最初设计是用于满足快速渲染的需求,主要用于游戏行业,GPU的架构已被证明能够与机器学习良好匹配。
GPU的并行处理,这也是CPU可以做的事情,但与通用CPU相反,GPU的专业性使它们能够跟上摩尔定律的速度继续发展。Nvidia是GPU领域的主要参与者,最近宣布了一套基于Turing架构的新GPU。
为避免淘汰,新的Nvidia GPU实际上带来了图形渲染的改进。但是,更重要的是,为了契合需求,他们收集了Tensor Cores,这是该公司专门的机器学习架构,并介绍了NGX。NGX是一种技术,正如Nvidia所说,它将人工智能引入图形管道:“NGX技术带来了诸如采用标准摄像机输入和创建超级慢动作等功能,就像你使用一个价值10万美元以上的专用摄像机那样。”
人们一般不会对通用机器学习(ML)感兴趣,但新Nvidia卡的功能肯定能引起人们的关注。然而,它的价格也反映了产品的高端品质,从2.5K到10K美元不等。
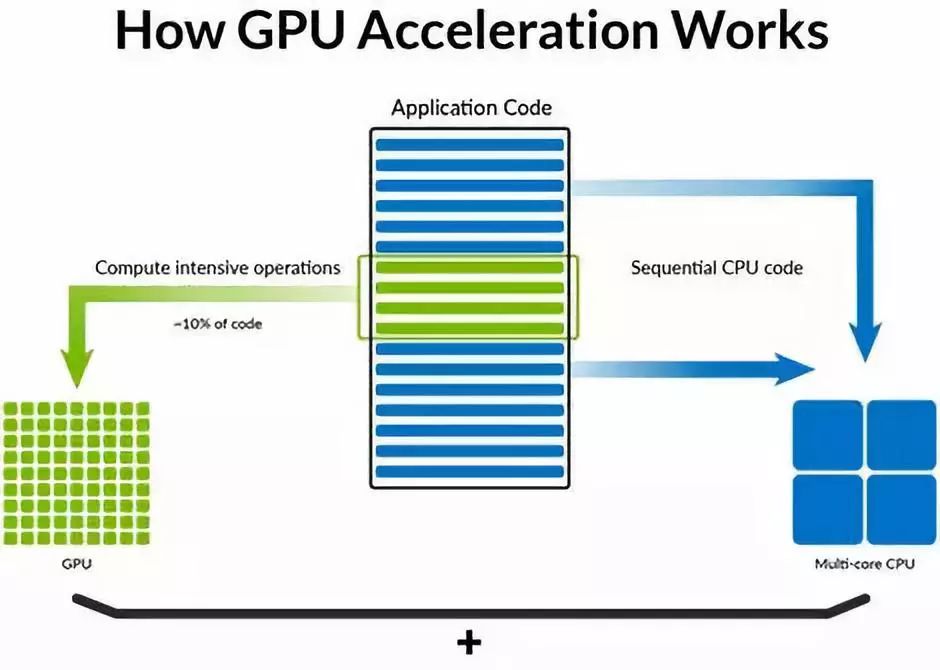
GPU可以极大地加速工作负载,这些工作负载可以分解,并行执行,与CPU协同工作。图片:SQream。
但是,利用GPU,不仅需要硬件架构 ---- 它还需要软件。对于Nvidia来说,这是有利的竞争因素,而对于像AMD这样的竞争者来说却显然不利。Nvidia在使用GPU进行机器学习应用方面遥遥领先的原因在于使用GPU所需的库(CUDA和cuDNN)。
AMD虽然也有一个可以与AMD GPU一起使用的替代软件层,称为OpenCL,但它的成熟度和支持程序与Nvidia的库尚有差距。AMD正在努力迎头赶上,它也在硬件方面展开布局。
为了从AI芯片中受益,AMD所需的投资超出了硬件。迫切需要一个位于这些芯片之上的软件层,以优化在其上运行的代码。没有它,它们几乎无法使用。但是,这也需要使用者学习如何使用这一层。
上面,我们已经提到GPU如何成为ML工作负载的首选AI芯片。最受欢迎的ML库支持GPU - Caffe,CNTK,DeepLearning4j,H2O,MXnet,PyTorch,SciKit和TensorFlow等。除了需要了解每个库的细节之外,通常还需要构建GPU环境。
至于普通的数据操作和分析 -----GPU数据库方面,已经开发出一类新的数据库系统,其目标是利用GPU并行性,将现成硬件的优势带入主流应用程序开发。这个领域可以选择BlazingDB,Brytlyt,Kinetica,MapD,PG-Strom和SQream。
FPGA
现场可编程门阵列(FPGA)并不是新的产品----自80年代起就存在。它们背后的主要思想是,与其他芯片相反,可以按需重新配置。读者可能更想知道这是如何实现的,如何更专业化,以及有什么用处。
FPGA可以简单地被认为是包含低级芯片基础的电路板,例如AND和OR门。通常使用硬件描述语言(HDL)指定FPGA配置。使用此HDL,可以以符合特定任务或应用程序要求的方式配置基础架构,实质上是模仿特定应用集成电路(ASIC)。
由于必须通过HDL为每个不同的应用程序重新编程,芯片听起来很复杂。因此,软件层至关重要。根据Tirias Research首席分析师Jim McGregor的说法,“构建FPGA的工具集有些古老。Nvidia在使用GPU时很好地利用了CUDA语言。利用FPGA,仍然是一种有效构建算法的黑马。”

英特尔非常重视FPGA,可能是为了弥补其在GPU中落后的局势。但FPGA软件层还没有GPU那样成熟。图像:英特尔
但上面这种情况正在悄然发生改变。最初是英特尔对FPGA表示了兴趣,收购了Altera(关键的FPGA制造商之一)。这可能是英特尔推进AI芯片世界的战略,这一点在与GPU竞争中处于劣势之后将变得越来越重要。但是,抛开复杂性,FPGA有竞争力吗?
英特尔最近发布了针对NVIDIA Titan X Pascal GPU在两代英特尔FPGA(英特尔Arria10和英特尔Stratix 10)上评估新兴深度学习(DL)算法的研究成果。这项研究的要点是,当使用紧凑数据类型与完整32位浮点数据(FP32)时,英特尔Stratix 10 FPGA优于GPU。
这意味着只要使用低精度数据类型,英特尔的FPGA就可以与GPU竞争。听起来很糟糕,但它实际上是DL的新兴趋势。理由是简化计算,同时保持可比较的准确性。
将FPGA用于机器学习(ML)有光明前景。然而,今天,发展并不是那么顺利。在验证McGregor的声明时,似乎没有一个支持FPGA的ML库开箱即用。目前正在开展使用TensorFlow实现FPGA的工作,但除此之外几乎没有什么其他工具。
然而,在数据操作和分析方面,情况有所不同。最近,英特尔展示了其与FPGA加速分析合作的一些合作伙伴。 Swarm64看有望为PostgreSQL,MariaDB和MySQL加速12次。另外,rENIAC可以提供Cassandra的13倍加速版本,以及Algo-Logic及其定制键值存储。
在云端和本地部署中抉择
选用何种新兴技术很难抉择,硬件也不例外。项目研发中,是应该构建自己的基础架构,还是使用云?是应该等到产品变得更加成熟再使用,还是立即使用产品,成为早期采用者而受益?是选择GPU,还是FPGA?是选择哪个GPU或FPGA供应商?
例如,当与ZDNet的贡献者和分析师Tony Baer讨论GPU数据库时,Baer认为他们没有未来。这是因为,根据Baer的说法,GPU的经济性使得只有云提供商能够大规模地积累和使用它,因此,GPU数据库供应商最终都会成为基于云的数据库提供者。
目前,一项此类收购,即巴西的Blazegraph收购,已经发生。虽然这确实有意义,但这不是唯一可行的方案。如果我们谈论收购,那么非云数据库供应商可能会购买GPU数据库,而这些供应商希望将这些功能带到他们的产品中。
一些GPU数据库供应商也有可能进入他们自己的行列。与现有企业相比,GPU数据库似乎不太成熟,但10年前许多NoSQL解决方案也是如此。 GPU数据库在日常运营和分析上有选择优势,但问题是替换现有系统支出的成本是否超出了性能的提升需求。
另一方面,Swarm64和rENIAC是FPGA产品,它们承诺尽可能保持您现有的基础架构不受影响,特别是在Swarm64的情况下。虽然它们的成熟度仍然是一个悬而未决的问题,但“简单地”将硬件添加到现有数据库并从中获得更好的性能的想法听起来很好。
就GPU与FPGA问题而言,GPU似乎拥有更广泛和更成熟的生态系统,但FPGA提供了卓越的灵活性。还有人建议FPGA可以提供更好的性能/功耗比,并且未来的GPU可能无法跟上低精度数据类型,因为它们必须重新设计以支持这一点。

哪一个最适合您 - GPU或FPGA?云还是本地部署?
就选择GPU或FPGA供应商而言,与选择云或本地部署这个问题交织在一起。 GPU,Azure,Google Cloud都提供GPU,所有这些GPU都使用Nvidia作为其支持GPU的实例。另一方面,FPGA在AWS(由Xilinx提供支持的EC2 F1)和Azure(由英特尔提供支持的Project Brainwave)上提供,但不在Google Cloud上提供。
AWS似乎没有为F1提供ML特定的设施。 Microsoft允许用户部署经过培训的ML模型,但是关于如何在FPGA驱动的实例上训练此类模型的信息并不多。就其本身而言,谷歌正在重视其定制TPU芯片。
就GPU与FPGA问题而言,GPU似乎拥有更广泛和更成熟的生态系统,但FPGA提供了卓越的灵活性。也有人认为,FPGA可以提供更好的性能/功耗比,并且未来的GPU可能无法跟上低精度数据类型,因为它们必须进行重新设计以支持这一点。
关于百万美元的构建费用问题 - 如果你用云或建立自己的基础设施 - 答案可能取决于:
如果基础设施足够使用,投资购买和安装自己的基础设施是有意义的,但偶尔使用云似乎更合适。但对于大多数情况,这种基础构建可能更适合混合部署。
另外,需要特别说明的是:如果你有一个Hadoop集群,那么为它添加GPU或FPGA功能可能更有意义,因为Hadoop已经升级,能够支持这两个选项。
当然,我们在构建这个生态系统时,还没有涵盖所有可能的选项 ----- 这些都不是唯一的云部署方式,也不是唯一的可选AI芯片。这是一个有许多新兴参与者的新生领域,我们可以参照选择的有很多。
刘志红,17年IT从业经验。曾在NTT DATA,Oracle,中钞造币集团,中国电信云计算分公司从事云计算等关联IT研发工作。独立拥有软件著作权1件。目前就职于电子工业出版社。
相关阅读:
高端私有云项目交流群,欢迎加入!
所谓的「雾计算」需要小心谨慎
终于有人把云计算、大数据和人工智能讲明白了!
OpenStack 重新定义 边缘计算「附白皮书」
Gartner:2018 年 公有云IaaS魔力象限出炉,大量公司消失了。。。
OpenShift 3.9 重磅发布!多项新功能「附48页PPT」
云计算趋势:RightScale 2018 年云状况调查报告「附下载」










