点击上方“AI时间”,关注并设为星标
加入人工智能技术社区!
源 | 开源最前线
机器学习是我们这个时代最具变革性的技术,它具有从太空探索到财务,医学和科学的巨大应用。据估计,未来对机器学习专家的需求将会不断增加,今年估计增长约60%。
最重要的是,该行业在过去几年中经历了巨大的变革。以前,要成为一名机器学习专家,你需要有一个博士学位(或一些高学历),但现在已经不是这样了。由于大型科技公司如Alphabet(谷歌母公司),IBM,微软等公司的参与,现在任何人都可以更轻松地开始机器学习。
这不,YouTube上的大咖Siraj Raval就发起了一个挑战赛:#100DaysOfMLCode。
什么是#100DaysOfMLCode?

这是向机器学习开发人员(专家或新手)发出的挑战,要求在接下来的100天内每天至少花一小时学习和构建机器学习模型。内容有易到难,由此也可以看得出博主Avik-Jain的用心良苦。了解更多挑战赛详情,可访问其官方GitHub地址:https://github.com/llSourcell/100_Days_of_ML_Code
其中一名叫Avik Jain的机器学习爱好者,创建了一个100-Days-Of-ML-Code的项目,很快引起了大家的注意,截至今日,该项目已经获得了 11570 个「star」以及 1993 个「fork」(GitHub地址:https://github.com/Avik-Jain/100-Days-Of-ML-Code)。
更不可思议的是,他还创建了该项目的中文版(中文版地址:https://github.com/Avik-Jain/100-Days-of-ML-Code-Chinese-Version)
从他的GitHub主页可以看到他共创建了6个项目:
目前作者的100天计划,已经进行到第54天,已有的内容包括:
有监督学习
● 数据预处理
● 简单线性回归
● 多元线性回归
● 逻辑回归
● k近邻法(k-NN)
● 支持向量机(SVM)
● 决策树
● 随机森林
无监督学习
● K-均值聚类
● 层次聚类
这里我们通过介绍第一天的数据预处理来深入了解下这个项目
数据预处理

第1步:导入库
import
numpy as np
import pandas as pd
第2步:导入数据集
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[ : , :-1].values
Y = dataset.iloc[ : , 3].values
第3步:处理丢失数据
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0)
imputer = imputer.fit(X[ : , 1:3])
X[ : , 1:3] = imputer.transform(X[ : , 1:3])
第4步:解析分类数据
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])
创建虚拟变量
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
第5步:拆分数据集为训练集合和测试集合
from sklearn.cross_validation import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)
第6步:特征量化
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.fit_transform(X_test)
通过6步完成数据预处理。此例子中用到的数据地址:https://github.com/Avik-Jain/100-Days-Of-ML-Code/blob/master/datasets/Data.csv
可以看出他每天的计划都包含一张学习图片,操作补流程、相应的代码,以及用到的数据
简单线性回归 | 第2天

多元线性回归 | 第3天

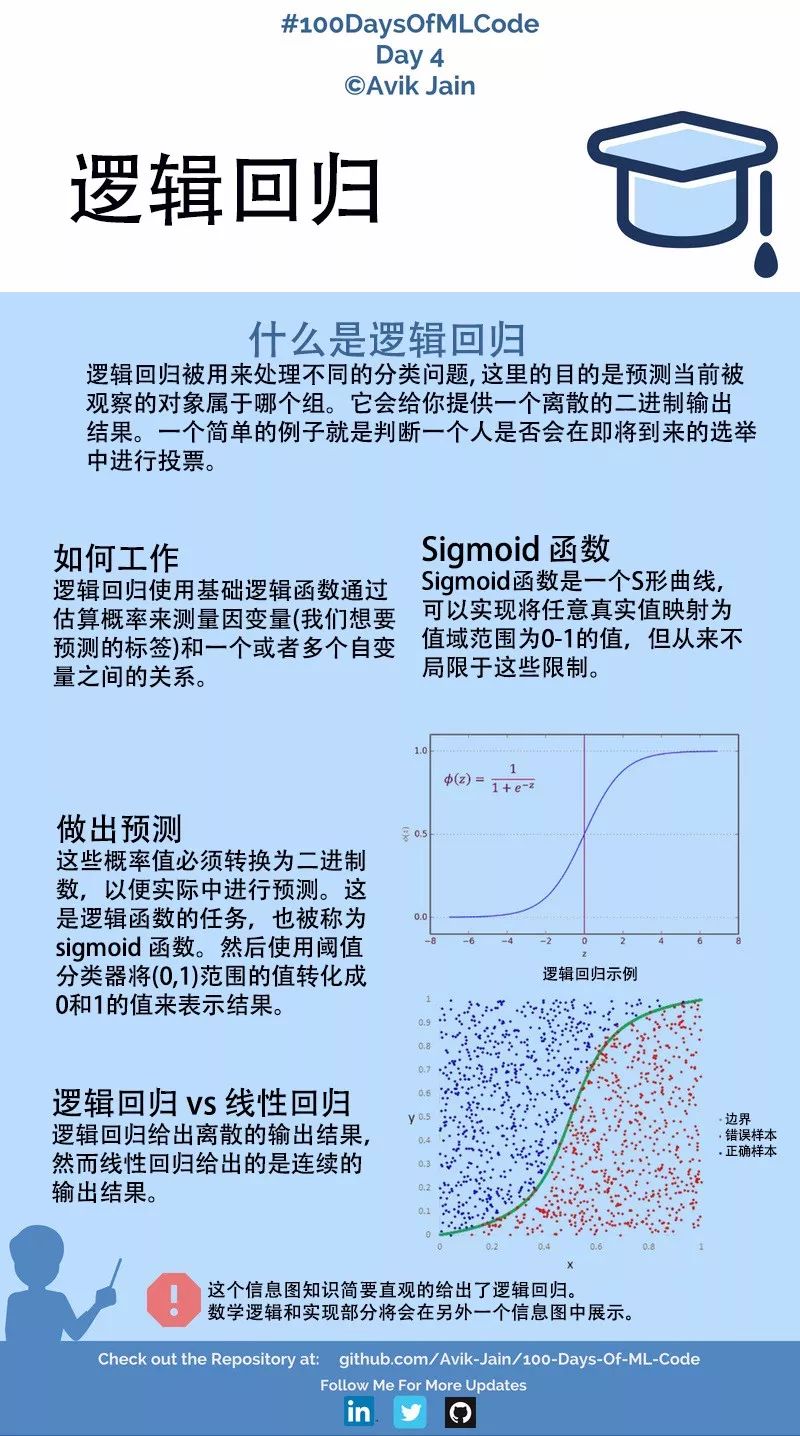
逻辑回归 | 第4天
-END-
转载声明:本文由「开源最前线」整理自https://theinfogrid.com/tech/machine-learning/100daysofmlcode-join-the-challenge-and-learn-machine-learning/、GitHub详情页。












