
作者:霍华德
知乎:https://zhuanlan.zhihu.com/p/35321651
首先,要感谢机智又有漂亮女朋友的 @张子浩,听君一席话,胜读十年书。(前两天才知道子浩是我实验室亲师弟,2333)
今天,无意中想要看一看,每个学校各个专业毕业后的薪资水平,能找到各个学校的平均薪酬,也能找到各个专业的平均薪酬,可找不到每个学校按专业统计的薪酬数据。因此,这个问题就变成了:如图所示,已知道专业的平均薪酬和学校的平均薪酬,如何估计学校对应专业的平均薪酬?
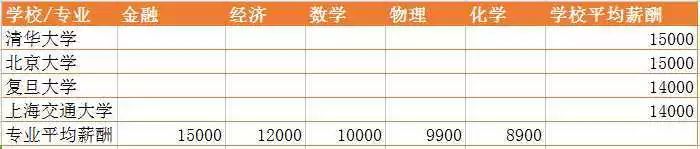 数据纯属虚构
数据纯属虚构最简单的思路就是高中数学,联立方程求解,可是题目中有20个未知数xi ,却仅有9个方程。约束条件不足,无法求出准确解。
可是就没办法了吗?NO~我们可以用神经网络的视角来思考这个问题。求平均可以看作是,权重wi固定为1/N(N为相应的维度)的神经网络。矩阵里的变量初始化,然后以神经网络的输出与平均值的均方误差作为损失函数,然后训练网络,让误差反向传播,则可给出满足该约束条件且使得损失函数最小的解。
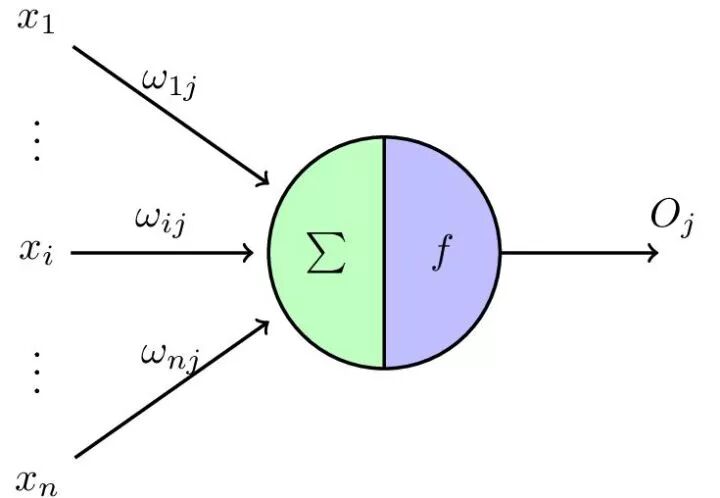
而专业和学校可以分别看作两个神经网络,而这个问题则可以转化为共享参数的两个神经网络的多任务的学习问题。
下面用一个玩具模型来阐述多任务学习。
假设我们一开始,知道正确答案:我们有3个学校,4个专业,分别的薪资用下面这个矩阵表示:
matrix = np.array([[15000, 12000, 10000, 8000],
[14000, 11000, 9000, 7000],
[13000, 10000, 8000, 6000]])
我们沿不同轴求平均值当作回归目标:
行平均: [11250, 10250, 9250]
列平均: [14000, 11000 ,9000 ,7000]
矩阵变量初始化,然后分别计算行的损失函数和列的损失函数,然后加在一起共同优化。下面是代码:
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import numpy as np
import torch
from torch.autograd import Variable
matrix = np.array([[15000, 12000, 10000, 8000],
[14000, 11000, 9000, 7000],
[13000, 10000, 8000, 6000]])
col_avg = np.mean(matrix, axis=0)
row_avg = np.mean(matrix, axis=1)
global_avg = np.mean(matrix)
# init x with random variable
x = np.ones([3, 4]) * global_avg
# make x varible
x_var = Variable(torch.FloatTensor(x), requires_grad=True)
optimizer = torch.optim.SGD([x_var], lr=0.1)
for train_step in range(500):
row_loss = 0
for i in range(x_var.size()[0]):
# print (x_var[i,:])
x_row_avg = torch.mean(x_var[i, :])
row_loss += (x_row_avg - row_avg[i]) ** 2
row_loss = row_loss / x_var.size()[0]
col_loss = 0
for j in range(x_var.size()[1]):
# print (x_var[i,:])
x_col_avg = torch.mean(x_var[:, j])
col_loss += (x_col_avg - col_avg[j]) ** 2
col_loss = col_loss / x_var.size()[1]
total_loss = col_loss + row_loss
if train_step % 10 == 0:
print(total_loss.data.numpy()[0])
optimizer.zero_grad() # 清空上一步的残余更新参数值
total_loss.backward() # 误差反向传播, 计算参数更新值
optimizer.step()
print(x_var)
用SGD训练五百轮后,参数就已经非常接近正确答案了:
Variable containing:
14998.9463 11999.6104 10000.0537 8000.4980
13999.1533 10999.8330 9000.2881 7000.7261
12999.3818 10000.0547 8000.5024 6000.9580
[torch.FloatTensor of size 3x4]
一个看似和神经网络完全无关的问题,通过合理的分析和转化,变成一个神经网络问题,从而得到解决。机器学习实在是太酷炫了!
机器学习不止是调参,更是一种认识世界的方式!
推荐阅读:
如何在知乎上做到“有效学习”?
【学术福利】Pytorch的tensorboard食谱帮你可视化误差结果
通俗易懂讲解感知机(三)--收敛性证明与对偶形式以及python代码讲解












