【导读】当贝叶斯、奥卡姆和香农一起给机器学习下定义,将统计学、信息理论和自然哲学的一些核心概念结合起来,我们便会会发现,可以对监督机器学习的基本限制和目标进行深刻而简洁的描述。
令人有点惊讶的是,在所有机器学习的流行词汇中,我们很少听到一个将统计学、信息理论和自然哲学的一些核心概念融合起来的短语。
而且,它不是一个只有机器学习博士和专家懂得的晦涩术语,对于任何有兴趣探索的人来说,它都具有精确且易于理解的含义,对于ML和数据科学的从业者来说,它具有实用的价值。
这个术语就是最小描述长度(Minimum Description Length)。
让我们剥茧抽丝,看看这个术语多么有用……
我们从托马斯·贝叶斯(Thomas Bayes)说起,顺便一提,他从未发表过关于如何做统计推理的想法,但后来却因“贝叶斯定理”而不朽。

Thomas Bayes
那是在18世纪下半叶,当时还没有一个数学科学的分支叫做“概率论”。人们知道概率论,是因为亚伯拉罕 · 棣莫弗(Abraham de Moievre)写的《机遇论》(Doctrine of Chances)一书。
1763年,贝叶斯的著作《机会问题的解法》(An Essay toward solving a Problem in the Doctrine of opportunities)被寄给英国皇家学会,但经过了他的朋友理查德·普莱斯(Richard Price)的编辑和修改,发表在伦敦皇家学会哲学汇刊。在那篇文章中,贝叶斯以一种相当繁复的方法描述了关于联合概率的简单定理,该定理引起了逆概率的计算,即贝叶斯定理。
自那以后,统计科学的两个派别——贝叶斯学派和频率学派(Frequentists)之间发生了许多争论。但为了回归本文的目的,让我们暂时忽略历史,集中于对贝叶斯推理的机制的简单解释。请看下面这个公式:
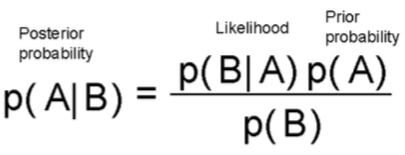
这个公式实际上告诉你,在看到数据/证据(可能性)之后更新你的信念(先验概率),并将更新后的信念程度赋予后验概率。你可以从一个信念开始,但每个数据点要么加强要么削弱这个信念,你会一直更新你的假设。
听起来十分简单而且直观是吧?很好。
不过,我在这段话的最后一句话里耍了个小花招。你注意了吗?我提到了一个词“假设”。
在统计推理的世界里,假设就是信念。这是一种关于过程本质(我们永远无法观察到)的信念,在一个随机变量的产生背后(我们可以观察或测量到随机变量,尽管可能有噪声)。在统计学中,它通常被称为概率分布。但在机器学习的背景下,它可以被认为是任何一套规则(或逻辑/过程),我们认为这些规则可以产生示例或训练数据,我们可以学习这个神秘过程的隐藏本质。
因此,让我们尝试用不同的符号重新定义贝叶斯定理——用与数据科学相关的符号。我们用D表示数据,用h表示假设,这意味着我们使用贝叶斯定理的公式来尝试确定数据来自什么假设,给定数据。我们把定理重新写成:
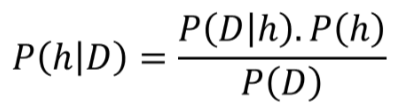
现在,一般来说,我们有一个很大的(通常是无限的)假设空间,也就是说,有许多假设可供选择。贝叶斯推理的本质是,我们想要检验数据以最大化一个假设的概率,这个假设最有可能产生观察数据(observed data)。我们一般想要确定P(h|D)的argmax,也就是想知道哪个h的情况下,观察到的D是最有可能的。为了达到这个目的,我们可以把这个项放到分母P(D)中,因为它不依赖于假设。这个方案就是最大后验概率估计(maximum a posteriori,MAP)。
现在,我们应用以下数学技巧:
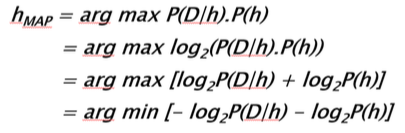
那些负对数为2的术语看起来很熟悉是不是......来自信息论(Information Theory)!
让我们进入克劳德·香农(Claude Shannon)的世界吧!
如果要描述克劳德·香农的天才和奇特的一生,长篇大论也说不完。香农几乎是单枪匹马地奠定了信息论的基础,引领我们进入了现代高速通信和信息交流的时代。
香农在MIT电子工程系完成的硕士论文被誉为20世纪最重要的硕士论文:在这篇论文中,22岁的香农展示了如何使用继电器和开关的电子电路实现19世纪数学家乔治布尔(George Boole)的逻辑代数。数字计算机设计的最基本的特征——将“真”和“假”、“0”和“1”表示为打开或关闭的开关,以及使用电子逻辑门来做决策和执行算术——可以追溯到香农论文中的见解。
但这还不是他最伟大的成就。
1941年,香农去了贝尔实验室,在那里他从事战争事务,包括密码学。他还研究信息和通信背后的原始理论。1948年,贝尔实验室研究期刊发表了他的研究,也就是划时代的题为“通信的一个数学理论”论文。
香农将信息源产生的信息量(例如,信息中的信息量)通过一个类似于物理学中热力学熵的公式得到。用最基本的术语来说,香农的信息熵就是编码信息所需的二进制数字的数量。对于概率为p的信息或事件,它的最特殊(即最紧凑)编码将需要-log2(p)比特。
而这正是在贝叶斯定理中的最大后验表达式中出现的那些术语的本质!
因此,我们可以说,在贝叶斯推理的世界中,最可能的假设取决于两个术语,它们引起长度感(sense of length),而不是最小长度。

那么长度的概念是什么呢?
奥卡姆的威廉(William of Ockham,约1287-1347)是一位英国圣方济会修士和神学家,也是一位有影响力的中世纪哲学家。他作为一个伟大的逻辑学家而享有盛名,名声来自他的被称为奥卡姆剃刀的格言。剃刀一词指的是通过“剔除”不必要的假设或分割两个相似的结论来区分两个假设。
奥卡姆剃刀的原文是“如无必要勿增实体”。用统计学的话说,我们必须努力用最简单的假设来解释所有数据。
其他杰出人物响应了类似的原则。
牛顿说:“解释自然界的一切,应该追求使用最少的原理。”
罗素说:“只要有可能,用已知实体的结构去替代未知实体的推论。”
人们总是喜欢更短的假设。
那么我们需要一个关于假设的长度的例子吗?
下面哪个决策树的长度更小?A还是B?
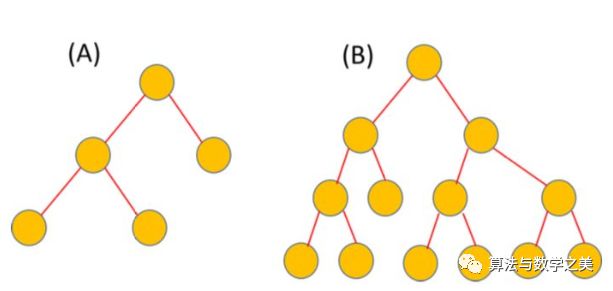
即使没有一个对假设的“长度”的精确定义,我相信你肯定会认为左边的树(A)看起来更小或更短。当然,你是对的。因此,更短的假设就是,它要么自由参数更少,要么决策边界更不复杂,或者这些属性的某种组合可以表示它的简洁性。
那么Length(D | h)是什么?
给定假设是数据的长度。这是什么意思?
直观地说,它与假设的正确性或表示能力有关。给定一个假设,它支配着数据的“推断”能力。如果假设很好地生成了数据,并且我们可以无错误地测量数据,那么我们就根本不需要数据。
想想牛顿的运动定律。
牛顿运动定律第一次出现在《自然哲学的数学原理》上时,它们并没有任何严格的数学证明。它们不是定理。它们很像基于对自然物体运动的观察而做出的假设。但是它们对数据的描述非常好。因此它们就变成了物理定律。
这就是为什么你不需要记住所有可能的加速度数字,你只需要相信一个简洁的假设,即F=ma,并相信所有你需要的数字都可以在必要时从这个假设中计算出来。它使得Length(D | h) 非常小。
但是如果数据与假设有很大的偏差,那么你需要对这些偏差是什么,它们可能的解释是什么等进行详细描述。
因此,Length(D | h)简洁地表达了“数据与给定假设的匹配程度”这个概念。
实质上,它是错误分类(misclassication)或错误率( error rate)的概念。对于一个完美的假设,它是很短的,在极限情况下它为零。对于一个不能完美匹配数据的假设,它往往很长。
而且,存在着权衡。
如果你用奥卡姆剃刀刮掉你的假设,你很可能会得到一个简单的模型,一个无法获得所有数据的模型。因此,你必须提供更多的数据以获得更好的一致性。另一方面,如果你创建了一个复杂的(长的)假设,你可能可以很好地处理你的训练数据,但这实际上可能不是正确的假设,因为它违背了MAP 原则,即假设熵是小的。

因此,贝叶斯推理告诉我们,最好的假设就是最小化两个项之和:假设的长度和错误率。
这句话几乎涵盖了所有(有监督)机器学习。
想想它的结果:
线性模型的模型复杂度——选择多项式的程度,如何减少平方和残差。
神经网络架构的选择——如何不公开训练数据,达到良好的验证精度,并且减少分类错误。
支持向量机正则化和kernel选择——软边界与硬边界之间的平衡,即用决策边界非线性来平衡精度
我们真正得出的结论是什么?
我们从最小描述长度(MDL)原理的分析中得出什么结论?
这是否一劳永逸地证明了短的假设就是最好的?
没有。
MDL表明,如果选择假设的表示(representation)使得h的大小为-log2 P(h),并且如果异常(错误)的表示被选择,那么给定h的D的编码长度等于-log2 P(D | h),然后MDL原则产生MAP假设。
然而,为了表明我们有这样一个表示,我们必须知道所有先验概率P(h),以及P(D | h)。没有理由相信MDL假设相对于假设和错误/错误分类的任意编码应该是首选。
对于实际的机器学习,人类设计者有时可能更容易指定一种表示来获取关于假设的相对概率的知识,而不是完全指定每个假设的概率。
这就是知识表示和领域专业知识变得无比重要的地方。它使(通常)无限大的假设空间变小,并引导我们走向一组高度可能的假设,我们可以对其进行最优编码,并努力找到其中的一组MAP假设。
一个奇妙的事实是,如此简单的一套数学操作就能在概率论的基本特征之上产生对监督机器学习的基本限制和目标的如此深刻而简洁的描述。对这些问题的简明阐述,读者可以参考来自CMU的一篇博士论文《机器学习为何有效》(Why Machine Learning Works)。
原文链接:
https://towardsdatascience.com/when-bayes-ockham-and-shannon-come-together-to-define-machine-learning-96422729a1ad
Why Machine Learning Works:
http://www.cs.cmu.edu/~gmontane/montanez_dissertation.pdf
∑编辑 | Gemini
来源 | 新智元
更多精彩:
☞ 哈尔莫斯:怎样做数学研究
☞ 扎克伯格2017年哈佛大学毕业演讲
☞ 线性代数在组合数学中的应用
☞ 你见过真的菲利普曲线吗?
☞ 支持向量机(SVM)的故事是这样子的
☞ 深度神经网络中的数学,对你来说会不会太难?
☞ 编程需要知道多少数学知识?
☞ 陈省身——什么是几何学
☞ 模式识别研究的回顾与展望
☞ 曲面论
☞
自然底数e的意义是什么?
☞ 如何向5岁小孩解释什么是支持向量机(SVM)?
☞ 华裔天才数学家陶哲轩自述
☞ 代数,分析,几何与拓扑,现代数学的三大方法论

算法数学之美微信公众号欢迎赐稿
稿件涉及数学、物理、算法、计算机、编程等相关领域,经采用我们将奉上稿酬。
投稿邮箱:math_alg@163.com









