
大家好!又到了每周一狗熊会的深度学习时间了。在上一讲中,小编和大家重点介绍了深度神经网络中普遍存在的梯度爆炸和梯度消失问题,对其形成原因和机制以及解决方法都进行了详细的讲述,并以此为基础对 LSTM 的网络架构和技术原理进行了深入讲解。这一讲小编将对 RNN 的重要应用方向——自然语言处理进行简单介绍,对自然语言模型和词汇表征进行讲解,并在此基础上,对基于统计描述的 SVD 词向量生成方法进行介绍。

我们之前讨论的 DNN 和 CNN 的各种分类、检测和分割神经网络,一直致力于如何让机器“看懂”图像,所以基于图像任务的领域也叫计算机视觉。我们本节要讨论的问题,是在于如何让计算机“懂得”人类语言,说起来也玄乎,人类语言千变万化,一个破机器它能懂我们说的话?小编到现在都还听不懂杭州话呢!虽说如此,但实际生活中大家已经不自觉的都在用到基于自然语言处理技术相关的产品和应用,比如说 siri 的语音交互、阿里的天猫精灵智能音箱、谷歌翻译等等,背后的实现技术基本上都是自然语言处理(Natural Language Processing, NLP)。
那究竟什么是自然语言处理呢?小编从教科书中找到比较完整的定义:自然语言处理主要研究使用计算机来处理、理解以及运用人类语言的各种理论和方法,属于人工智能的一个重要研究方向。正如图像图形学+深度学习成就了新的计算机视觉一样,传统的语言学+深度学习便成就了新的自然语言处理。随着互联网的快速发展,网络文本尤其是基于用户生成的文本也在爆炸性增长,传统的自然语言处理技术加上深度学习,使这些都使得自然语言处理有着更广阔的应用空间。
自然语言处理包括认知、理解、生成等部分。 自然语言认知和理解是让计算机把输入的语言变成有意思的符号和关系,然后根据目的再进行处理。所以简单来说,自然语言处理就是如何让计算机理解人类语言。为了达到这样的目的,我们需要在理论上基于数学和统计理论建立各种语言模型,然后通过计算机来实现这些语言模型。因为人类语言的多样性和复杂性,所以总体而言自然语言处理是一门极具挑战的学科和领域。
整个 NLP 是个庞大的技术体系,包含了很多研究方向和内容。简单概括一下,NLP 的研究方向主要包括:
机器翻译
信息检索
-
文档分类
问答系统
自动文摘
信息抽取
实体识别
文本挖掘
舆情分析
机器写作
语音识别
语音合成
......
可以说 NLP 是个非常庞杂的领域了,学习和应用起来都颇有难度。难度主要体现在语言场景、学习算法和语料等三个方面。语言场景是指人类语言的多样性、复杂性和歧义性;学习算法指的是 NLP 的数理模型一般都较为难懂,比如隐马尔可夫模型(HMM)、条件随机场(CRF)以及基于 RNN 的深度学习模型;语料的困难性指的是如何获取高质量的训练语料。
虽然进行一项自然语言处理任务很难,但随着深度学习的发展,我们也越来越容易构建起一个高效的自然语言模型。比如最近谷歌 AI 公开的一篇论文提出了新的语言表征模型 BERT,一举刷新了 11 项 NLP 任务的最优性能记录,号称最强 NLP 预训练模型。小编虽然还没有亲自试过,但也觉得随着深度学习的发展,计算机也会更好的理解我们的语言。
在谈词嵌入和词向量等词汇表征方法之前,我们先来看一下将 NLP 作为监督机器学习任务时该怎样进行描述。假设以一句话为例:"I want a glass of orange ____."。我们要通过这句话的其他单词来预测划横线部分的单词。这是一个典型的 NLP 问题,将其作为监督机器学习来看的话,模型的输入是上下文单词,输出是划横线的目标单词,或者说是目标单词的概率,我们需要一个语言模型来构建关于输入和输出之间的映射关系。应用到深度学习上,这个模型就是神经网络。
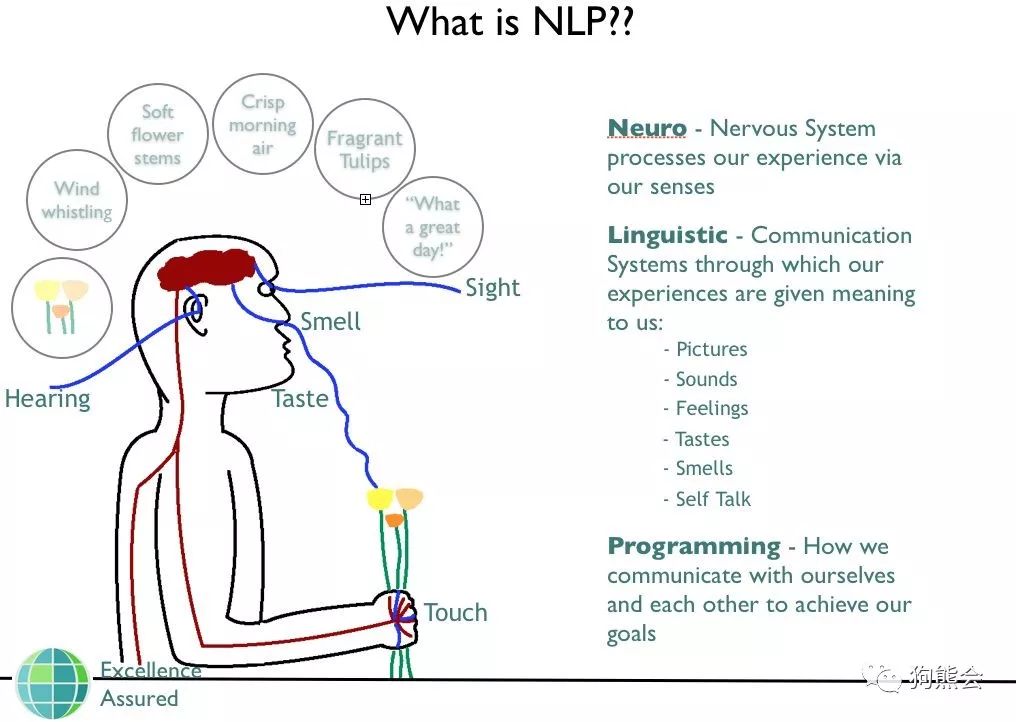
在 NLP 里面,最细粒度的表示就是词语,词语可以组成句子,句子再构成段落、篇章和文档。但是计算机并不认识这些词语,所以我们需要对以词汇为代表的自然语言进行数学上的表征。简单来说,我们需要将词汇转化为计算机可识别的数值形式,这种转化和表征方式目前主要有两种,一种是传统机器学习中的 one-hot 编码方式,另一种则是基于神经网络的词嵌入技术。
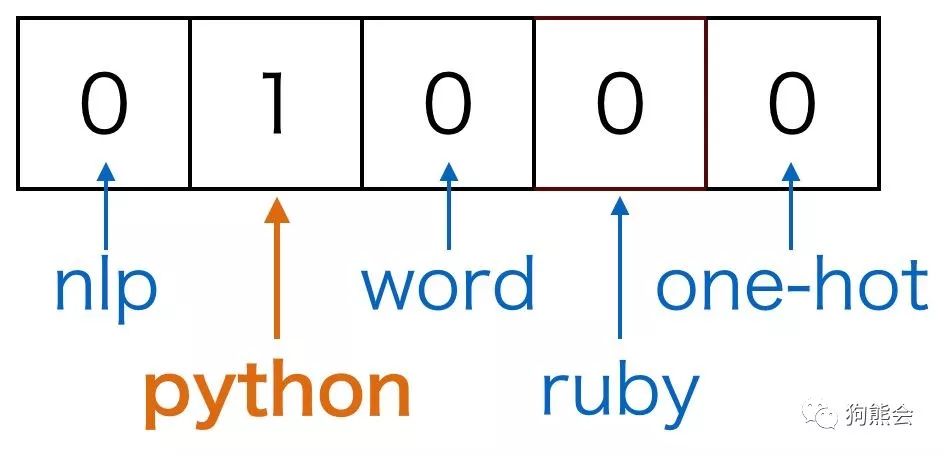
我们先来看词汇的 one-hot 编码方法。熟悉机器学习中分类变量的处理方法的同学对此一定很熟悉,无序的分类变量是不能直接硬编码为数字放入模型中的,因为模型会自动认为其数值之间存在可比性,通常对于分类变量我们需要进行 one-hot 编码。那么如何应用 one-hot 编码进行词汇表征呢?假设我们有一个包括 10000 个单词的词汇表,现在需要用 one-hot 方法来对每个单词进行编码。以上面那句 "I want a glass of orange ____." 为例,假设 I 在词汇表中排在第 3876 个,那么 I 这个单词的 one-hot 表示就是一个长度为 10000 的向量,这个向量在第 3876 的位置上为 1 ,其余位置为 0,其余单词同理,每个单词都是茫茫 0 海中的一个 1。大致如下图所示:
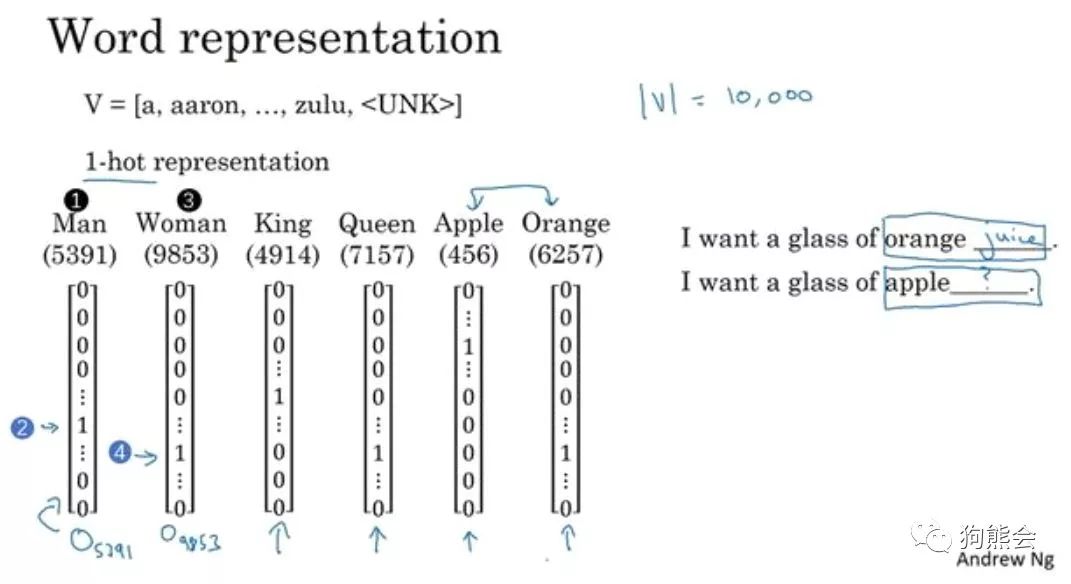
可见 one-hot 词汇表征方法最后形成的结果是一种稀疏编码结果,在深度学习应用于 NLP 任务之前,这种表征方法在传统的 NLP 模型中已经取得了很好的效果。但是这种表征方法有两个缺陷:一是容易造成维数灾难,10000 个单词的词汇表不算多,但对于百万级、千万级的词汇表简直无法忍受。第二个则在于这种表征方式不能很好的词汇与词汇之间的相似性,比如上述句子,如果我们已经学习到了 "I want a glass of orange juice.",但如果换成了 "I want a glass of apple ____.",模型仍然不会猜出目标词是 juice。因为基于 one-hot的表征方法使得算法并不知道 apple 和 orange 之间的相似性,这主要是因为任意两个向量之间的内积都为零,很难区分两个单词之间的差别和联系。所以进而我们有了第二种词汇表征方法。
第二种表征方法称之为词嵌入技术。词嵌入的基本想法就是将词汇表中的每个单词表示为一个普通向量,这个向量不像 one-hot 向量那样都是 0或者1,也没有 one-hot 向量那样长,大概就是很普通的向量,比如长这样:[-0.91, 2, 1.8, -.82, 0.65, ...]。这样的一种词汇表征方式就像是将词汇嵌入到了一种数学空间里面,所以叫做词嵌入。比如说大名鼎鼎的 word2vec 就是词嵌入技术的一种。
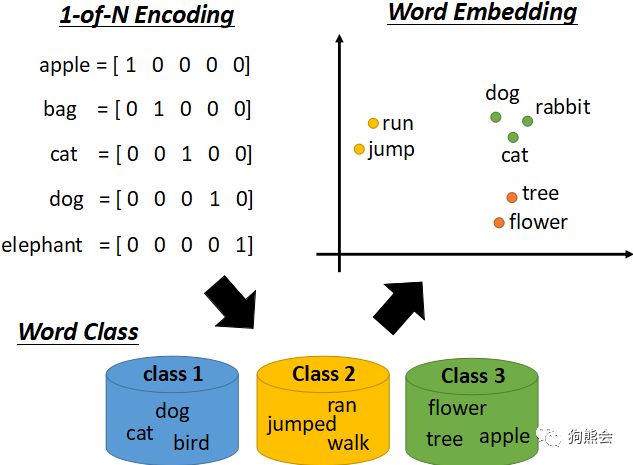
那么如何进行词嵌入呢?或者说我们如何才能将词汇表征成很普通的向量形式呢?这需要我们通过神经网络进行训练,训练得到的网络权重形成的向量就是我们最终需要的东西,这种向量也叫词向量,word2vec 就是其中的典型技术。word2vec 作为现代 NLP 的核心思想和技术之一,有着非常广泛的影响。word2vec 通常有两种语言模型,一种是根据中间词来预测上下文的 skip-gram 模型,另一种是根据上下文来预测中间词的 CBOW (连续词袋模型)。
3
词向量与语言模型
词汇表征的的直接结果便是词向量,除了最简单粗暴的 one-hot 向量之外,要使用其他方法将词汇表示成一个有效的词向量都要经过一些周折。无论是基于统计语言描述的方法还是基于神经网络等语言模型的方法,其基本思想都在于如何将词汇表示成与周围词汇存在关联的向量形式。本节先介绍一下基于统计语言描述的词向量生成方法——SVD 词向量,并做简单演示,下一讲小编再详细介绍基于神经网络模型的 word2vec 词向量生成技术。
既然词向量的本质在于降维,那么我们来回顾一下一些传统的数据降维技术,比如说 PCA 主成分法、SVD 奇异值分解法、t-SNE 降维法等等。关于三者降维的数学原理,小编这里不做展开,相信学过多元统计学的朋友一定都有所了解。而基于 SVD 分解的 SVD 词向量生成法便是小编要讲的一种基于统计描述的词向量生成方法。
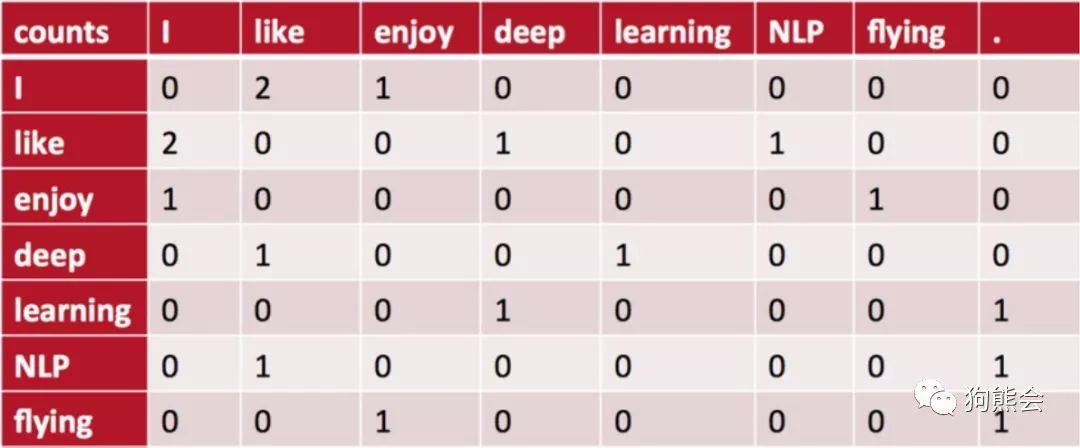
SVD 的原理不做细述,我们直接来看基于 SVD 生成词向量的范例。假设我们以下三个句子组成的语料库(该例子来自于CS224d自然语言处理课程)。
I like deep learning.
I like NLP.
I enjoy flying.
我们先来统计上述词汇的共现矩阵。所谓共现矩阵就是在指定大小窗内词汇之间的共现次数,以当前词周边共现词次数作为当前词的向量。上述词汇构成的共现矩阵如下图所示:
对该共现矩阵进行 SVD 分解即可得到 SVD 词向量,分解示意图和具体实现代码如下:
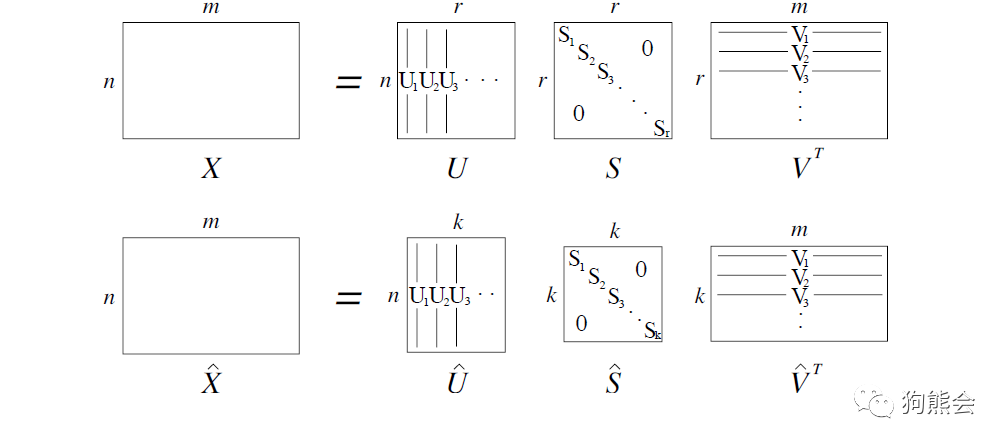
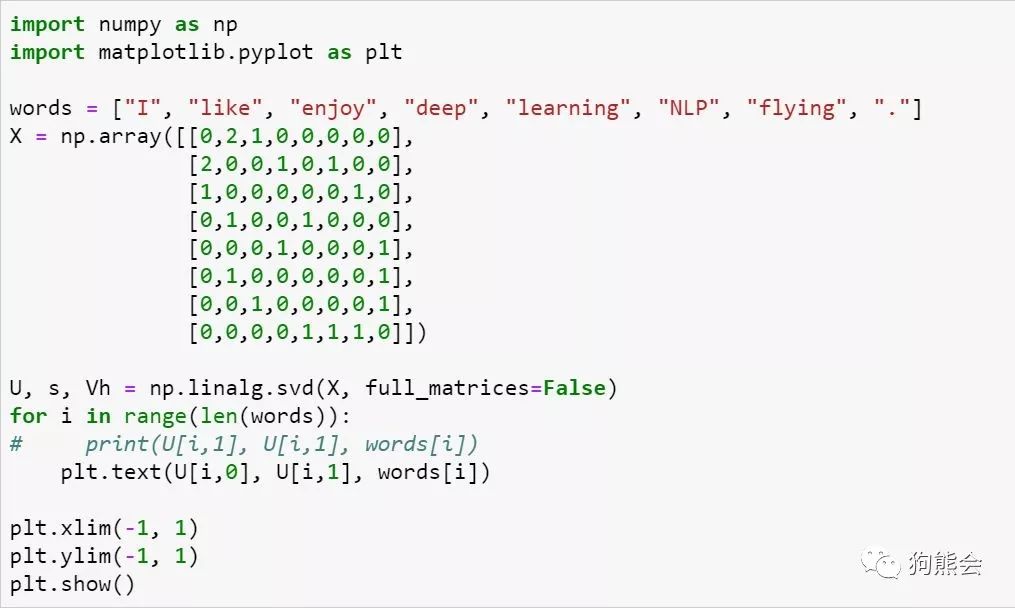
上述代码中的 U 便是经过 SVD 分解后得到的词向量,对分解后的词向量进行可视化展示,可以看到经过 SVD 降维后,一些语义相近的词被聚到了一起。
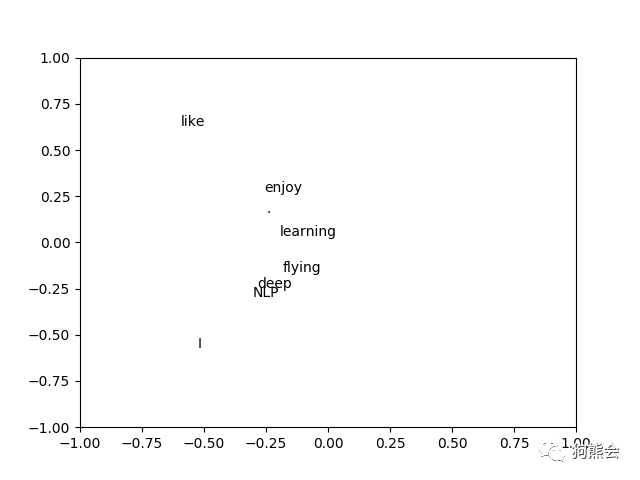
再来看基于语言模型的词向量生成方法。所谓语言模型,简单来说就是把一些词语组成一句话来判断这句话是不是人话。语言模型是自然语言处理的核心概念之一。举个简单的例子,比如我们使用有道机器翻译,机器在将中文转换为英文的过程中会有若干的候选结果项,它会使用语言模型来挑选一个尽量靠谱的结果呈现给你,这便是语言模型的关键之处。
假设给定一个包含 T 个词语的字符串 s,这个 s 看起来是自然语言的概率可表示为 P(w1,w2,...,wt),其中 w1 到 wt 依次表示这句话中各个词语。语言模型有个简单的概率推论,即:
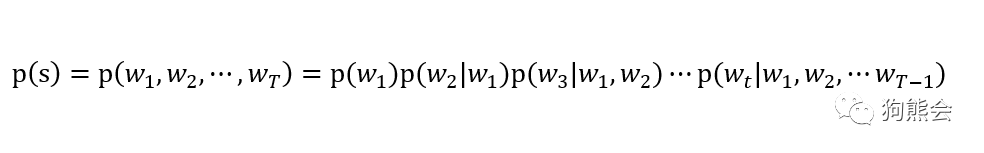
上式的条件概率表示的意思是当一句话的第一个词确定之后,看后面的词在前面的词出现的情况下出现的概念。写成太长的一串不好看,于是我们有了更简洁的写法:
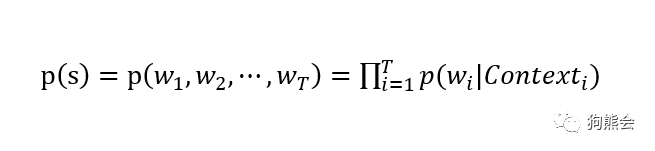
其中 Contexti 表示上下文词。我们可以用这个式子解释任意的自然语言模型,根据对上式的不同解释,我们也产生了两种语言模型:一种是基于概率统计语言描述的语言模型,比如说著名的 N-Gram和 N-Pos 模型,关于这两种模型的细节小编这里不详细展开,感兴趣的读者可自行查找资料。另一种则是利用函数来拟合上述概率模型,将语言模型当作是一种监督学习模型来求解,因而上式又有了如下表达式:
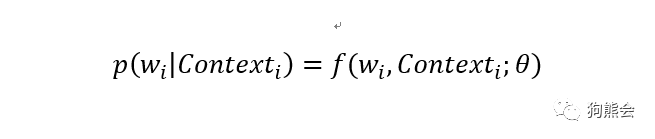
基于深度学习的自然语言处理便是求解上式的一种典型方法,再比如下一讲要讲到的 word2vec 模型,也是一种基于神经网络的语言模型。以上便是语言模型的相关解释。
以上便是本讲的主要内容。
在本节内容中,小编和大家重点介绍了自然语言处理的知识体系和任务,对自然语言模型和词汇表征有了基本的了解,并在此基础上,对基于统计语言描述的SVD词向量生成方法进行了介绍。在下一讲中,小编将深入介绍基于神经网络生成的 word2vec 词向量生成方法。
【参考资料】
deeplearningai.com
http://cs224d.stanford.edu/
https://zhuanlan.zhihu.com/p/26306795
word2vec Parameter Learning Explained
Efficient Estimation of Word Representations in Vector Space
https://www.cnblogs.com/peghoty/p/3857839.html
作者简介
鲁伟,狗熊会人才计划一期学员。目前在杭州某软件公司从事数据分析和深度学习相关的研究工作,研究方向为贝叶斯统计、计算机视觉和迁移学习。

识别二维码,查看作者更多精彩文章
狗熊会双十一大促活动开始了,
详情戳这里了解,
点击“阅读原文”购买!
识别下方二维码成为狗熊会会员!
友情提示:
个人会员不提供数据、代码,
视频only!
个人会员网址:http://teach.xiong99.com.cn












