

大家好!又到了每周一狗熊会的深度学习时间了。在上一讲中,小编给大家演示了如何利用 TensorFlow 根据原始文本训练一个词向量模型,以及如何根据给定的词向量模型做一些简单的自然语言分析。本节将继续介绍自然语言处理中其他的一些模型,今天要介绍的模型就是一款经典的 RNN 模型——seq2seq,以及著名的注意力模型,最后小编会在这些理论的基础上给出一个基于seq2seq和注意力模型的机器翻译实例。

所谓 seq2seq 模型,翻译过来也就是序列对序列的模型,在前面 RNN 的几种类型内容中我们已经了解到了 seq2seq 本质上是一种多对多(N vs M)RNN 模型,也就是输入序列和输出序列不等长的 RNN 模型。也正是因为 seq2seq 的这个特性,使得其有着广泛的应用场景,比如神经机器翻译、文本摘要、语音识别、文本生成、AI写诗等等。
先简单来图解一下 seq2seq 模型,刚刚说了 seq2seq 针对的是输入输出序列不等长的情况,对于这种情况,seq2seq 的做法是先将输入序列编码成一个上下文向量 c,如下图所示:
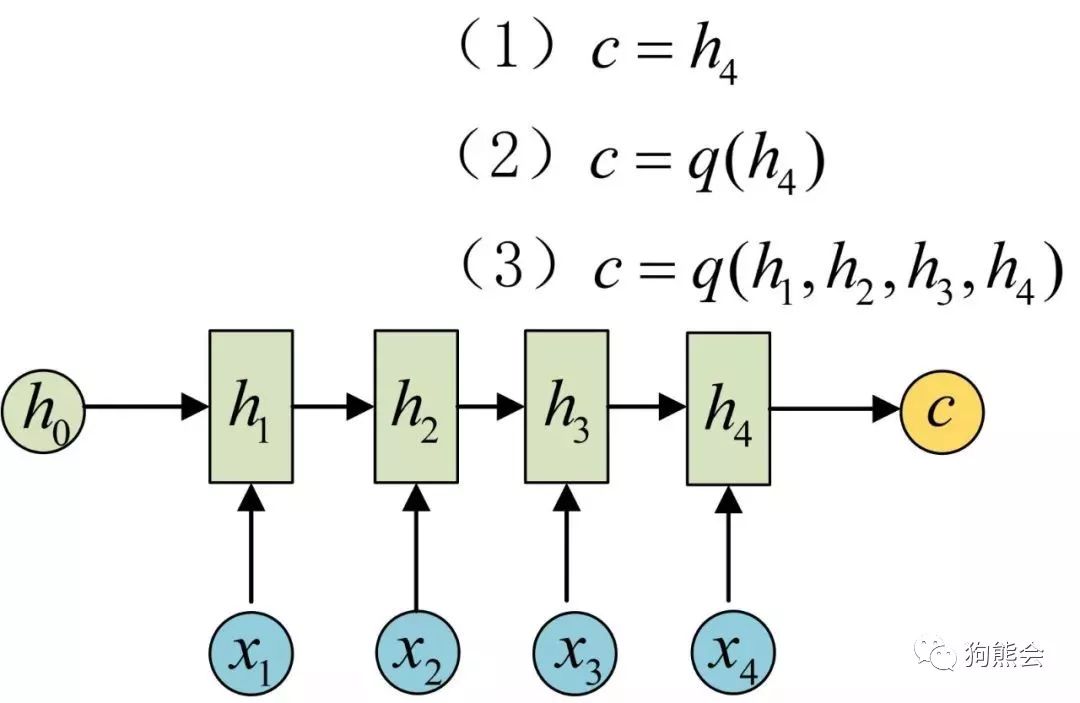
N VS M 编码 (图片选自何之源知乎专栏)
https://zhuanlan.zhihu.com/p/28054589
如上图所示,我们可以通过对最后一个隐变量以 c 进行赋值,然后展开来写。编码完成后我们再用一个 RNN 对 c 的结果进行解码,简而言之就是将 c 作为初始状态的隐变量输入到解码网络,如下图所示:
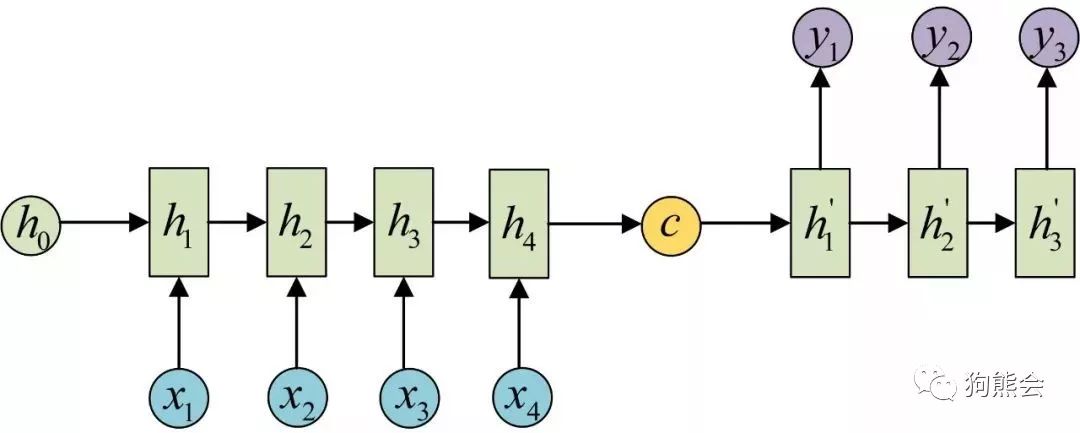
N VS M 解码 (图片选自何之源知乎专栏)
https://zhuanlan.zhihu.com/p/28054589
seq2seq 模型最早是在2013年由cho等人提出一种 RNN 模型,主要的应用目的就是机器翻译。

最早的编码解码结构:
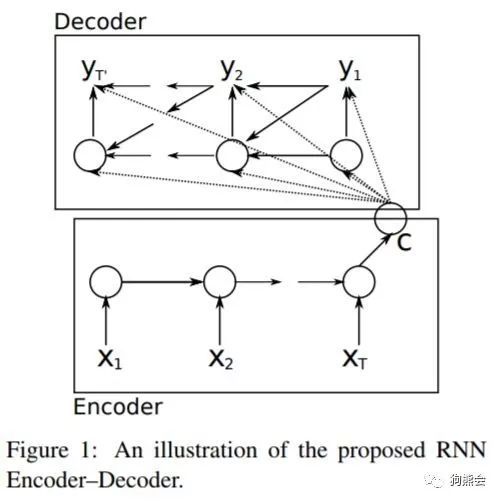
除了上面这篇文章之外,奠定 seq2seq 理论的还有一干谷歌大佬们的这篇论文:

关于 seq2seq 的数学细节这里不做更多讲述,感兴趣的朋友可以认真研读上述两篇论文。
seq2seq 模型虽然强大,但如果仅仅是单一使用的话,效果会大打折扣。本小节小编要介绍的注意力模型就是基于编码-解码框架下的一种模拟人类注意力直觉的一种模型。
人脑的注意力机制本质上是一种注意力资源分配的模型,比如说我们在阅读一篇论文的时候,在某个特定时刻注意力肯定只会在某一行文字描述,在看到一张图片时,我们的注意力肯定会聚焦于某一局部。随着我们的目光移动,我们的注意力肯定又聚焦到另外一行文字,另外一个图像局部。所以,对于一篇论文、一张图片,在任意一时刻我们的注意力分布是不一样的。这便是著名的注意力机制模型的由来。早在计算机视觉目标检测相关的内容学习时,我们就提到过注意力机制的思想,目标检测中的 Fast R-CNN 利用 RoI(兴趣区域)来更好的执行检测任务,其中 RoI 便是注意力模型在计算机视觉上的应用。
注意力模型的使用更多是在自然语言处理领域,在机器翻译等序列模型应用上有着更为广泛的应用。在自然语言处理中,注意力模型通常是应用在经典的 Encoder-Decoder 框架下的,也就是 RNN 中著名的 N vs M 模型,seq2seq 模型正是一种典型的 Encoder-Decoder 框架。
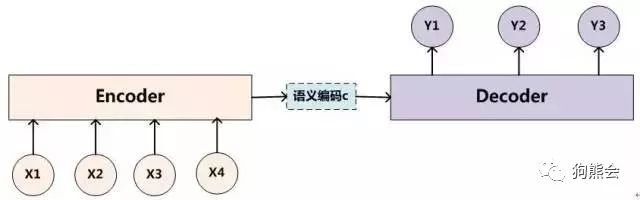
Encoder-Decoder 作为一种通用框架,在具体的自然语言处理任务上还不够精细化。换句话说,单纯的Encoder-Decoder 框架并不能有效的聚焦到输入目标上,这使得像 seq2seq 的模型在独自使用时并不能发挥最大功效。比如说在上图中,编码器将输入编码成上下文变量 C,在解码时每一个输出 Y 都会不加区分的使用这个 C 进行解码。而注意力模型要做的事就是根据序列的每个时间步将编码器编码为不同 C,在解码时,结合每个不同的 C 进行解码输出,这样得到的结果会更加准确。
统一编码为 C:
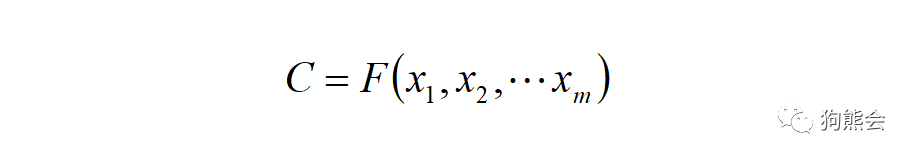
使用统一的 C 进行解码:
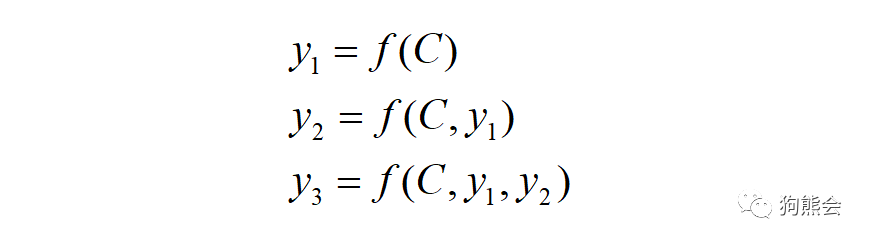
在应用了注意力模型之后,每个输入会被独立编码,解码时就会有各自对应的 c 进行解码,而不是简单的一刀切:
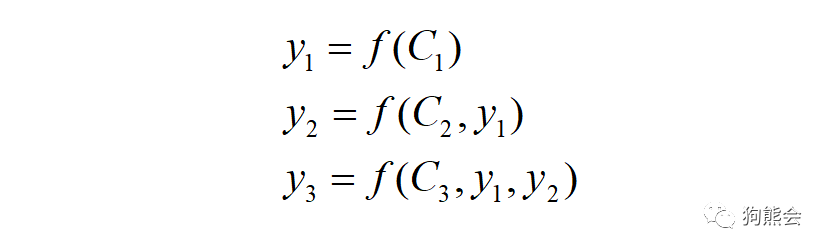
相应的,原先的 Encoder-Decoder 框架在引入了注意力机制后就变成了如下结构:
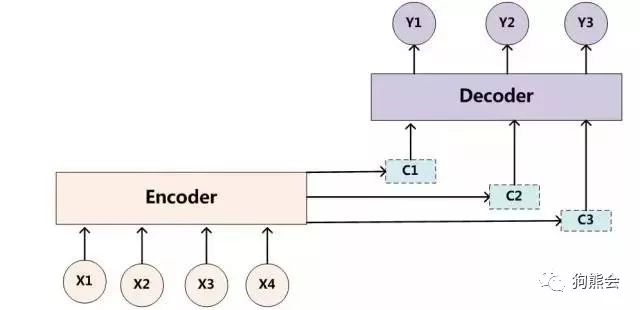
以上是注意力模型的图示,下面我们再来看如何注意力模型如何用公式来描述。公式描述如下:

简单的注意力模型通常有以上三个公式来描述:1)计算注意力得分 2)进行标准化处理 3)结合注意力得分和隐状态值计算上下文状态 C 。其中 u 为解码中某一时间步的状态值,也就是匹配当前任务的特征向量,vi 是编码中第 i 个时间步的状态值,a() 为计算 u 和 vi 的函数。a()通常可以取以下形式:
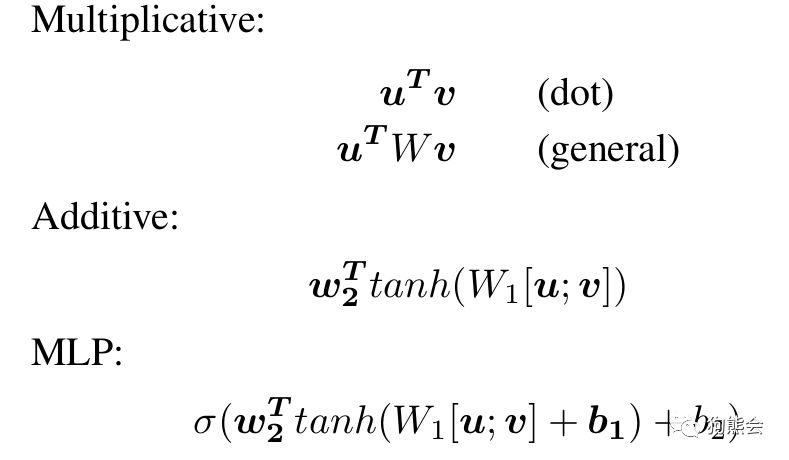
例如在机器翻译中,某一注意力得分的计算图解:
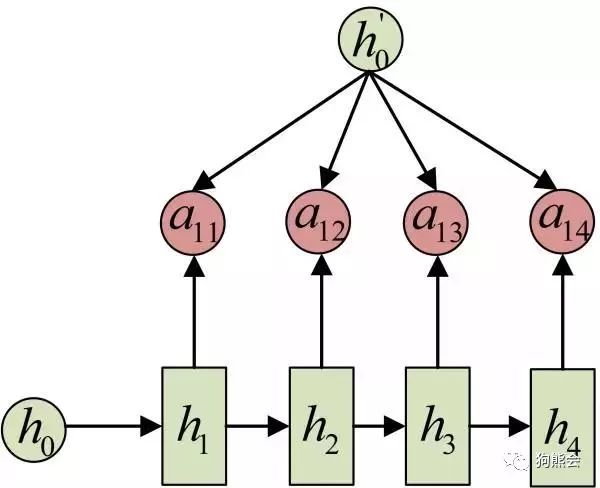
其中,注意力得分由编码中的隐状态 h 和 解码中的隐状态 h’ 计算得到。所以说,每一个上下文变量 C 会自动去选取与当前所要输出的 y 最合适的上下文信息。具体来说,我们用 aij 衡量Encoder中第 j 阶段的 hj 和解码时第 i 阶段的相关性,最终 Decoder中第 i 阶段的输入的上下文信息 Ci 就来自于所有 hj 对 aij 的加权和。
一段汉译英的机器翻译注意力模型图解示意图:
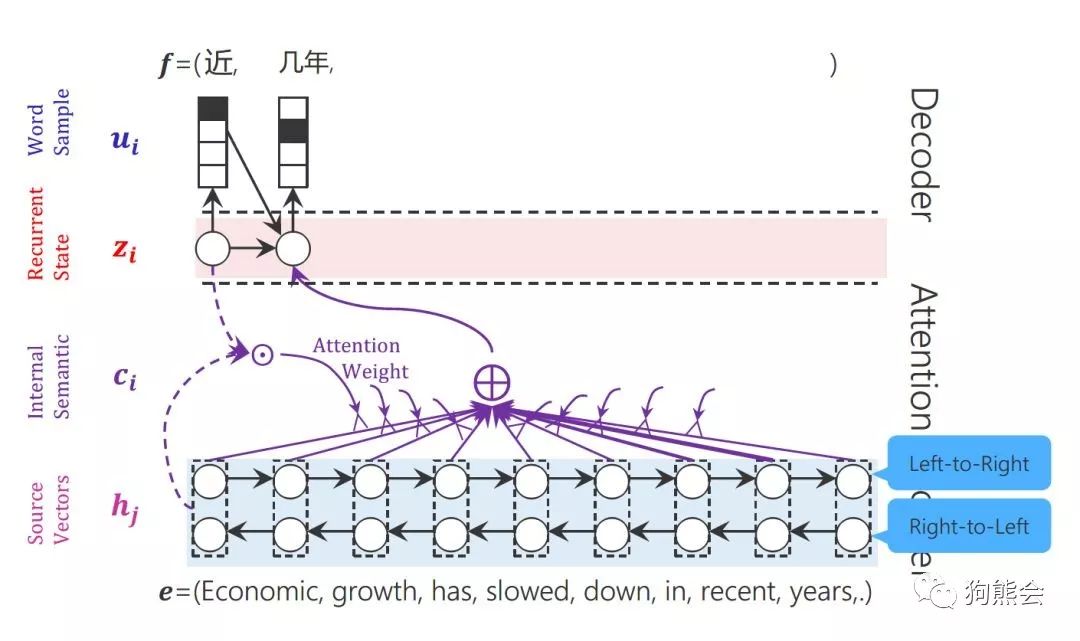
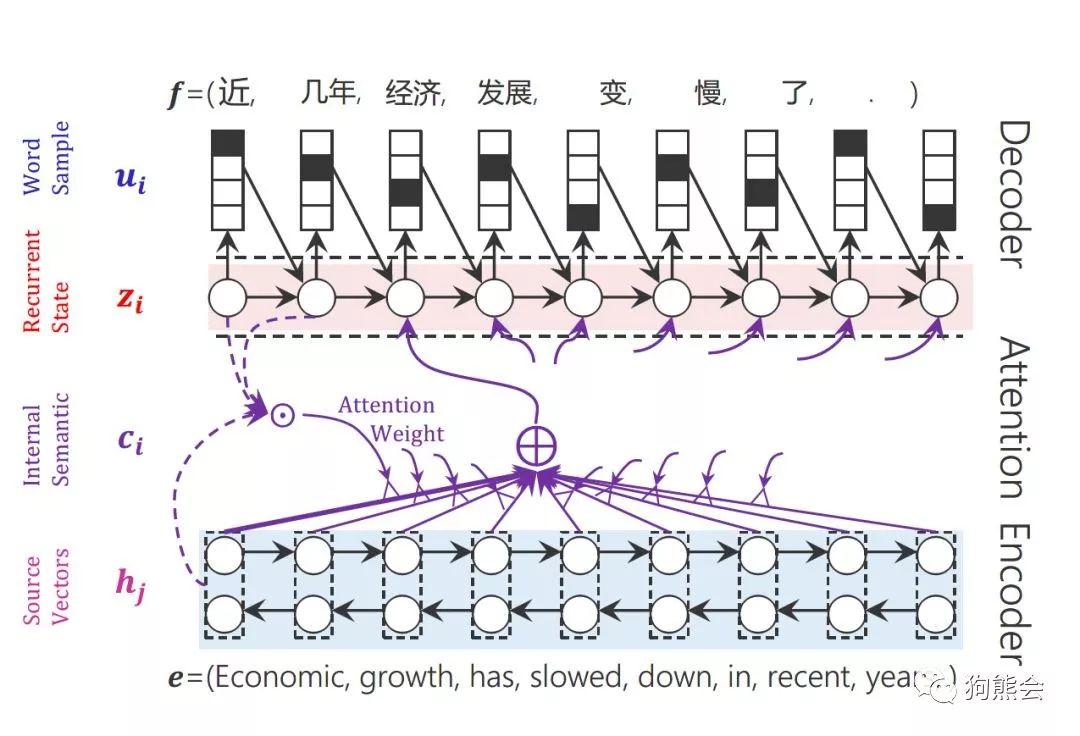
3
基于seq2seq和Attention机制的机器翻译实践
假设我们想根据英文表述的时间文本使用带有注意力机制的 RNN 模型将其翻译成数字时间。输入和输出格式示例如下:

导入任务相关的 package:
from keras.layers import Bidirectional, Concatenate, Permute, Dot, Input, LSTM, Multiply, Reshape
from keras.layers import RepeatVector, Dense, Activation, Lambda
from keras.optimizers import Adamfrom keras.utils import to_categorical
from keras.models import load_model, Model
from keras.callbacks import LearningRateSchedulerimport keras.backend as K
import matplotlib.pyplot as plt
import numpy as npimport random
import math
import json
读入输入和输出相关文本数据:
with open('data/Time Dataset.json','r') as f:
dataset = json.loads(f.read())
with open('data/Time Vocabs.json','r') as f:
human_vocab, machine_vocab = json.loads(f.read())
human_vocab_size = len(human_vocab)
machine_vocab_size = len(machine_vocab)
# 训练样本数
m = len(dataset)
对输入的时间文本进行标记化等预处理,对输出的时间进行 one-hot 等预处理,定义预处理函数:
def preprocess_data(dataset, human_vocab, machine_vocab, Tx, Ty): """
A method for tokenizing data.
Inputs:
dataset - A list of sentence data pairs.
human_vocab - A dictionary of tokens (char) to id's.
machine_vocab - A dictionary of tokens (char) to id's.
Tx - X data size
Ty - Y data size
Outputs:
X - Sparse tokens for X data
Y - Sparse tokens for Y data
Xoh - One hot tokens for X data
Yoh - One hot tokens for Y data
"""
# Metadata
m = len(dataset)
# Initialize
X = np.zeros([m, Tx], dtype='int32')
Y = np.zeros([m, Ty], dtype='int32')
# Process data
for i in range(m):
data = dataset[i]
X[i] = np.array(tokenize(data[0], human_vocab, Tx))
Y[i] = np.array(tokenize(data[1], machine_vocab, Ty))
# Expand one hots
Xoh = oh_2d(X, len(human_vocab))
Yoh = oh_2d(Y, len(machine_vocab))
return (X, Y, Xoh, Yoh)
def tokenize(sentence, vocab, length):
"""
Returns a series of id's for a given input token sequence.
It is advised that the vocab supports and .
Inputs:
sentence - Series of tokens
vocab - A dictionary from token to id
length - Max number of tokens to consider
Outputs:
tokens -
"""
tokens = [0]*length
for i in range(length):
char = sentence[i] if i < len(sentence) else ""
char = char if (char in vocab) else ""
tokens[i] = vocab[char]
return tokens
def ids_to_keys(sentence, vocab):
"""
Converts a series of id's into the keys of a dictionary.
"""
return [list(vocab.keys())[id] for id in sentence]
def
oh_2d(dense, max_value):
"""
Create a one hot array for the 2D input dense array.
"""
# Initialize
oh = np.zeros(np.append(dense.shape, [max_value]))
# Set correct indices
ids1, ids2 = np.meshgrid(np.arange(dense.shape[0]), np.arange(dense.shape[1]))
oh[ids1.flatten(), ids2.flatten(), dense.flatten('F').astype(int)] = 1
return oh
进行预处理并划分数据集:
# Max x sequence length
Tx = 41
# y sequence length
Ty = 5
X, Y, Xoh, Yoh = preprocess_data(dataset, human_vocab, machine_vocab, Tx, Ty)
# 划分训练集和测试集
train_size = int(0.8*m)
Xoh_train = Xoh[:train_size]
Yoh_train = Yoh[:train_size]
Xoh_test = Xoh[train_size:]
Yoh_test = Yoh[train_size:]
查看数据预处理前后的数据样例:
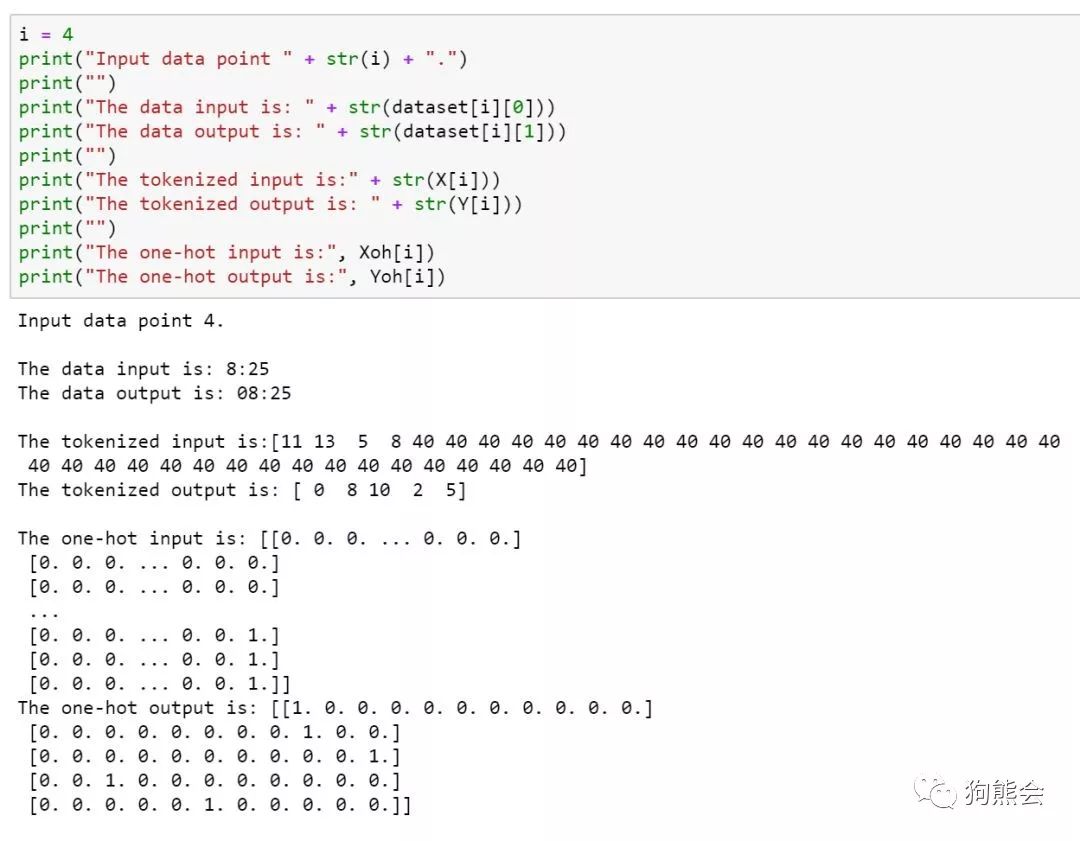
数据准备好即可开始建模,本例中注意力得分和上下文向量的计算公式如下:
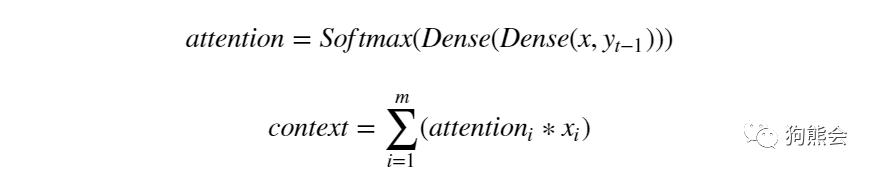
定义一个时间步的注意力机制过程:
# Define part of the attention layer gloablly so as to
# share the same layers for each attention step.
def softmax(x):
return K.softmax(x, axis=1)
layer1_size = 32
# Attention layer
layer2_size = 64
at_repeat = RepeatVector(Tx)
at_concatenate = Concatenate(axis=-1)
at_dense1 = Dense(8, activation="tanh")
at_dense2 = Dense(1, activation="relu")
at_softmax = Activation(softmax, name='attention_weights')
at_dot = Dot(axes=1)def one_step_of_attention(h_prev, a):
"""
Get the context.
Input:
h_prev - Previous hidden state of a RNN layer (m, n_h)
a - Input data, possibly processed (m, Tx, n_a)
Output:
context - Current context (m, Tx, n_a)
"""
# Repeat vector to match a's dimensions
h_repeat = at_repeat(h_prev)
# Calculate attention weights
i = at_concatenate([a, h_repeat])
i = at_dense1(i)
i = at_dense2(i)
attention = at_softmax(i)
# Calculate the context
context = at_dot([attention, a])
return context
然后根据一个时间步的注意力过程定义一个注意力网络层:
def attention_layer(X, n_h, Ty):
"""
Creates an attention layer.
Input:
X - Layer input (m, Tx, x_vocab_size)
n_h - Size of LSTM hidden layer
Ty - Timesteps in output sequence
Output:
output - The output of the attention layer (m, Tx, n_h)
"""
# Define the default state for the LSTM layer
h = Lambda(lambda X: K.zeros(shape=(K.shape(X)[0], n_h)))(X)
c = Lambda(lambda X: K.zeros(shape=(K.shape(X)[0], n_h)))(X) # Messy, but the alternative is using more Input()
at_LSTM = LSTM(n_h, return_state=True)
output = []
# Run attention step and RNN for each output time step
for _ in range(Ty):
context = one_step_of_attention(h, X)
h, _, c = at_LSTM(context, initial_state=[h, c])
output.append(h)
return output
### 然后即可搭建带有注意力机制的 LSTM 网络
layer3 = Dense(machine_vocab_size, activation=softmax)
def get_model(Tx, Ty, layer1_size, layer2_size, x_vocab_size, y_vocab_size):
"""
Creates a model.
input:
Tx - Number of x timesteps
Ty - Number of y timesteps
size_layer1 - Number of neurons in BiLSTM
size_layer2 - Number of neurons in attention LSTM hidden layer
x_vocab_size - Number of possible token types for x
y_vocab_size - Number of possible token types for y
Output:
model - A Keras Model.
"""
# Create layers one by one
X = Input(shape=(Tx, x_vocab_size))
a1 = Bidirectional(LSTM(layer1_size, return_sequences=True), merge_mode='concat')(X)
a2 = attention_layer(a1, layer2_size, Ty)
a3 = [layer3(timestep) for timestep in a2]
# Create Keras model
model = Model(inputs=[X], outputs=a3)
return model
然后传入数据,编译模型并进行训练:
# Obtain a model instance
model = get_model(Tx, Ty, layer1_size, layer2_size, human_vocab_size, machine_vocab_size)
# Create optimizer
opt = Adam(lr=0.05, decay=0.04, clipnorm=1.0)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
# Group the output by timestep, not example
outputs_train = list(Yoh_train.swapaxes(0, 1))
# model train
model.fit([Xoh_train], outputs_train, epochs=30, batch_size=
100)
训练示例如下:
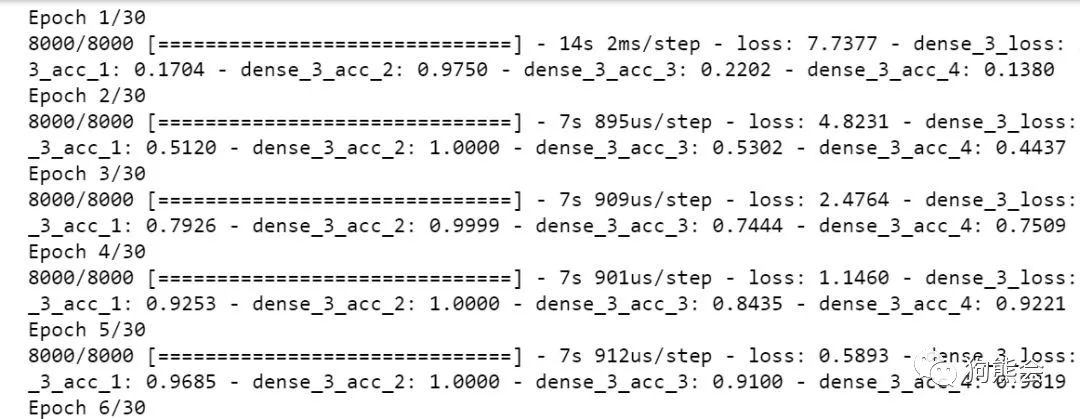
含有注意力层部分的模型结构如下:

模型的大致结构如下图所示(并不完全一致,仅供说明):
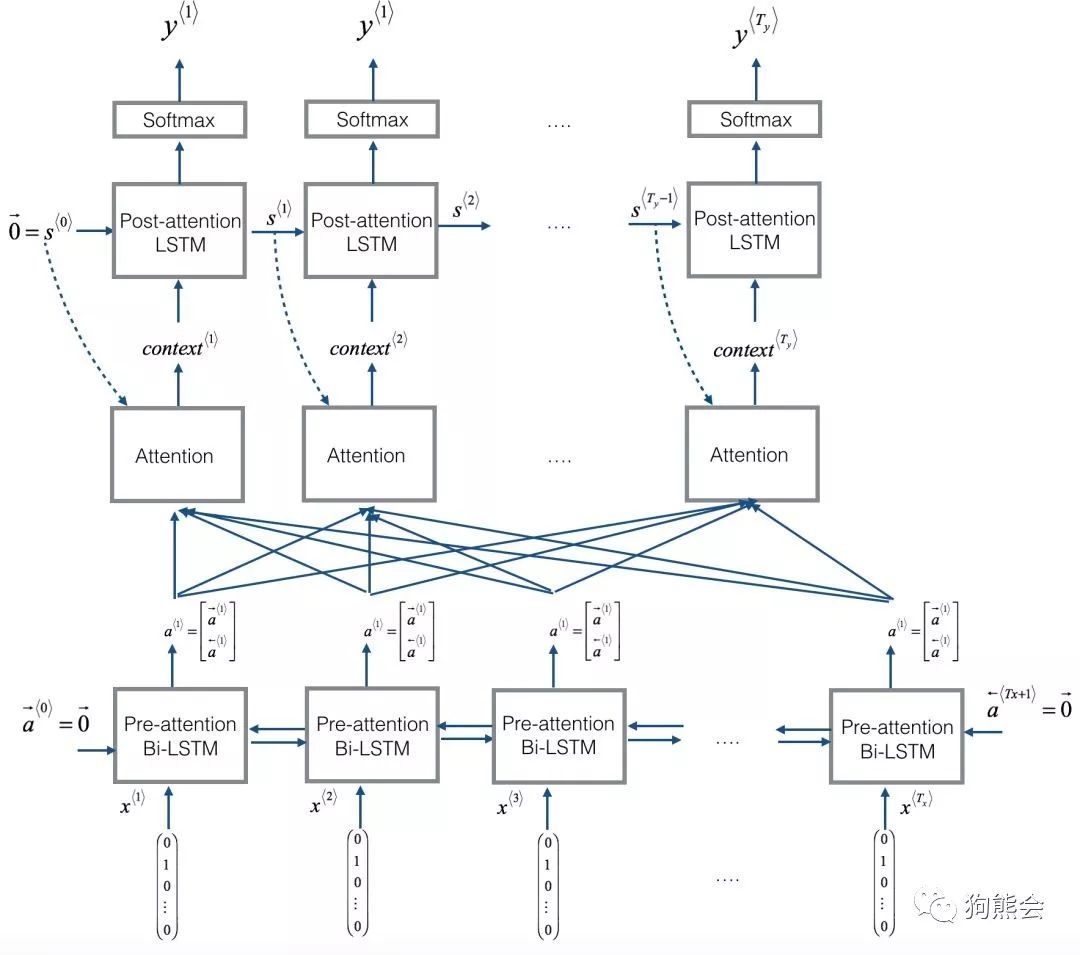
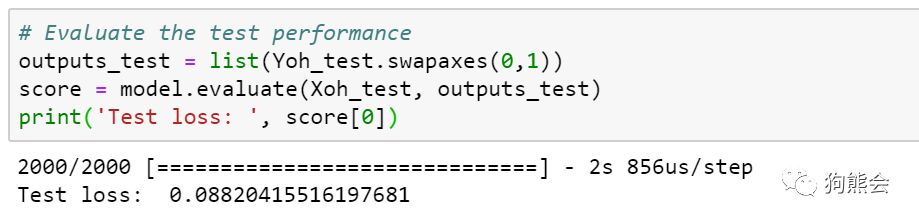
然后基于训练模型对测试集进行评估:
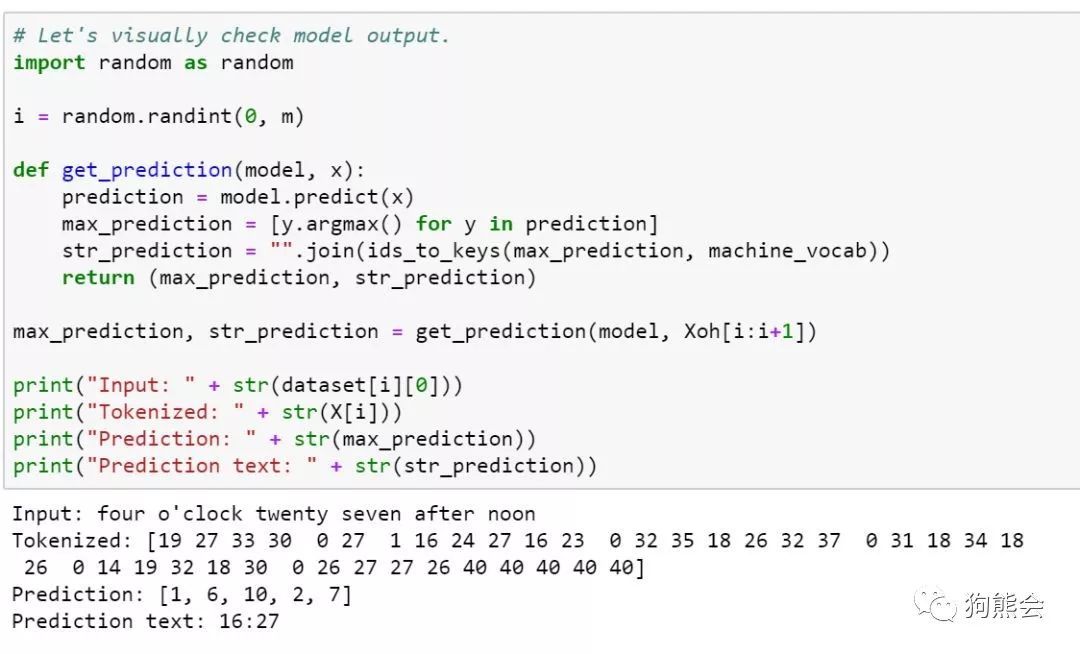
最后我们来简单看一下注意力模型到底在翻译过程中表达了什么,用可视化的方法对注意力模型进行展示:

可以看到,在上面这个测试的例子中,注意力机制使得模型将注意力集中在了对应的输入字符上。
以上便是本讲内容。
在本节内容中,小编和大家重点介绍了seq2seq模型的基本内容以及编码和解码的多对多模型框架。并在此基础上,继续深入介绍了注意力机制模型,对注意力机制的思想和原理进行了详细的介绍,最后基于这两个原理给出了一个机器翻译的代码实践。咱们下一期见!
【参考资料】
deeplearningai.com
Sequence to Sequence Learning with Neural Networks
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
https://zhuanlan.zhihu.com/p/28054589
https://github.com/luwill/Attention_Network_With_Keras
鲁伟,狗熊会人才计划一期学员。目前在杭州某软件公司从事数据分析和深度学习相关的研究工作,研究方向为贝叶斯统计、计算机视觉和迁移学习。

识别二维码,查看作者更多精彩文章
识别下方二维码成为狗熊会会员!
友情提示:
个人会员不提供数据、代码,
视频only!
个人会员网址:http://teach.xiong99.com.cn












