
本文为 AI 研习社编译的技术博客,原标题 :
The year in AI/ML advances: 2018 roundup
作者 | Xavier Amatriain
翻译 | leogle97
校对 | 酱番梨 整理 | 菠萝妹
原文链接:
https://medium.com/@xamat/the-year-in-ai-ml-advances-2018-roundup-db52f7f96358
注:本文的相关链接请点击文末【阅读原文】进行访问
AI/机器学习年度2018年度进展综述
对我来说,在每年的这个时候来总结机器学习的进展已经成为一种惯常(例如我去年在Quora上的回答)。和往常一样,这个总结必然会因为我自己的兴趣和关注点而有所偏颇,但我努力让它尽可能的涉猎广泛。请注意,下面是我在Quora上的博客作答。
如果我需要在几行内总结在2018年的机器学习的主要亮点,这些将是我可能会提及的:
人工智能的炒作和恐惧的散播逐渐冷却下来;
更多关注聚焦于具体问题,如公平、可解释性或因果关系;
深度学习有所发挥并在实践中不仅适用于图像分类(尤其是自然语言处理);
人工智能框架的战斗正在升温,如果你想成为名人,你最好发布一些你自己的框架;
让我们更为细致地探讨他们吧。
如果说2017年可能是恐惧散布和人工智能炒作的顶峰,那么2018年似乎是我们开始些许冷静下来的一年。诚然,一些人一直在继续宣扬他们对人工智能的恐惧,但他们可能忙于其他问题而没有把这一点作为他们的重要议程。与此同时,出版社和其他媒体似乎已经平静下来,认为虽然自动驾驶汽车和类似技术正在向我们走来,但它们不会立刻诞生。尽管如此,仍有一些人在为我们应该监管人工智能而不是专注于监管其结果的坏主意辩护。
但是值得高兴的是,今年的重点似乎已经转移到可处理的更具体的问题上。例如,有很多关于公平的讨论,并且有许多关于这个主题的会议(参见FATML或ACM FAT),甚至还有一些谷歌的在线课程。
(图)谷歌的关于公平的在线课程
沿着这些方面,今年被广泛讨论的其他问题还包括可阐释性、解释性和因果性。从后者开始,因果关系似乎重新回到聚光灯下,主要是因为Judea Pearl的《为什么之书》一书的出版。作者不仅决定写他的第一本“通俗易懂”的书,而且他还在Twitter上推广关于因果关系的讨论。事实上,就连流行媒体也将其描述为对现有人工智能方法的“挑战”(例如,请参阅《大西洋刊》的这篇文章)。实际上,即使是ACM Recsys大会上的最佳论文奖也颁给了一篇关于如何在嵌入式中包含因果关系的论文(参见“因果嵌入的建议”)。话虽如此,许多其他作者仍然认为因果关系在某种程度上是一种理论上的干扰,我们应该再次关注更具体的问题,比如阐释性或解释性。说到解释性,这一领域的一个亮点可能是关于Anchor的论文及代码的发布,它们是著名的LIME模型的同一作者的后续。

(图)Judea Pearl的时下经典
虽然仍然存在一些关于深度学习作为最通用人工智能模型范例的问题(考虑到那些疑问,算我一个),虽然我们继续浏览的第n个在Yann LeCun与Gary Marcus间的迭代,显而易见的是深度学习不仅是存在的,并且它仍然是远远没有达到它可达到的水平。更具体地说,在这一年里,深度学习方法在从语言到医疗保健等不同于视觉的领域取得了前所未有的成功。
事实上,很可能是在自然语言处理领域,我们看到了今年最有趣的进展。如果我必须选择今年最令人印象深刻的AI应用程序,它们都是自然语言处理(而且都来自谷歌)。第一个是谷歌超级有用的智能架构,第二个是他们的双工对话系统。
使用语言模型的想法加速了这些进展,这种想法在今年由Fast.ai的UMLFit普及(参见“理解 UMLFit”)。然后,我们看到了其他(和改进的)方法,如艾伦的ELMO、Open AI的变形金刚,或者最近谷歌的打败了许多SOTA的结果的BERT。这些模型被描述为“自然语言处理的 Imagenet 时刻”,因为它们提供了可使用的预训练通用模型,这些模型也可以针对特定任务进行微调。除了语言模型之外,还有许多其他有趣的改进,比如Facebook的多语言嵌入便是一个例子。有趣的是,我们还看到这些方法和其他方法是如何迅速地集成到更一般的自然语言处理框架中,比如AllenNLP或Zalando的FLAIR。
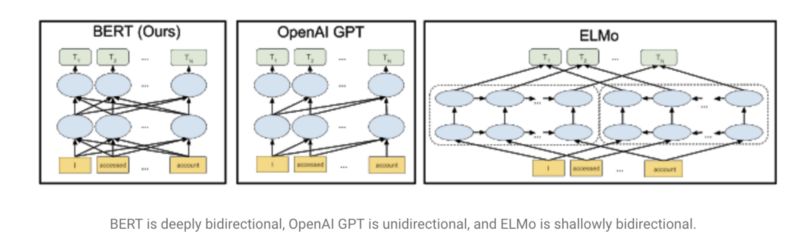
(图)BERT是深度双向的,OpenAI GPT是单向的,而ELMo是浅双向的
说到框架,今年的“人工智能框架之战”愈演愈烈。令人惊讶的是,就在Pytorch 1.0发布时,Pytorch似乎正在赶上TensorFlow。虽然在生产中使用Pytorch的情况仍然不是最理想的,但是Pytorch在这方面的进展似乎比Tensorflow在可用性、文档和教育方面的进展要快。有趣的是,很可能选择Pytorch作为框架在实现Fast.ai库上扮演了重要角色。话虽如此,谷歌意识到了这一切,并正在朝着正确的方向推进,如将Keras作为最高级而纳入框架,或者增加像Paige Bailey这样的以开发人员为中心的关键领导。最后,我们都能从这些伟大的资源中获益,所以请继续努力吧!
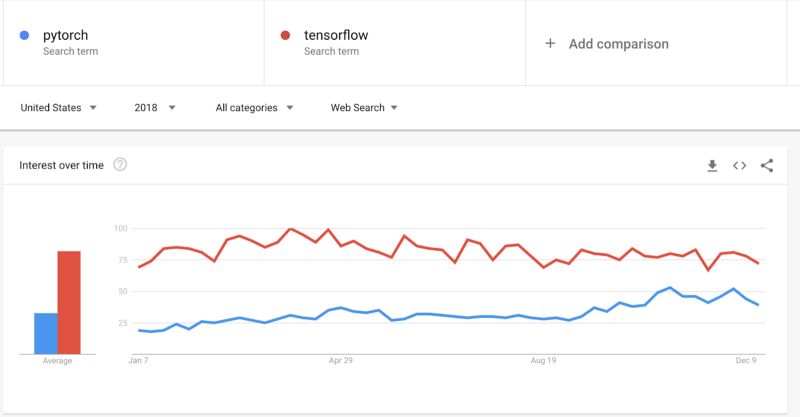
(图)pytorch VS tensorflow 的搜索量趋势
有趣的是,框架空间中另一个在框架空间有着诸多有趣的发展的是强化学习。虽然我不认为强化学习的研究进展像前几年那样令人印象深刻(我只想到DeepMind最近的Impala的工作),但令人惊讶的是,在一年时间里,我们看到所有主要人工智能厂家都发布了强化学习框架。谷歌发布了Dopamine框架用于研究,而Deepmind(也在谷歌内部)发布了某种程度上与之竞争的TRFL框架。Facebook不能落后,它发布Horizon,而微软则发布了TextWorld,而它更擅长训练基于文本的代理。有希望的是,所有这些开源的好处将帮助我们在2019年看到许多强化学习的进步。
为结束框架层面的讨论,我很高兴地看到谷歌最近在Tensor Flow上发布了TFRank。排名是一个非常重要的机器学习应用,而最近它可能没有得到应有的喜爱。
似乎深度学习最终消除了对数据的智能需求,但事实远非如此。围绕着改进数据的想法,该领域仍有一些非常有趣的进展。例如,虽然数据增强已经存在一段时间了,而且对于许多深度学习应用程序来说很关键,但是今年谷歌发布了自动增强,它是一种自动增强训练数据的深度强化学习方法。一个更极端的想法是用合成数据训练深度学习模型。这已经在实践中被尝试了一段时间,并被许多人视为是人工智能未来的关键。NVidia在使用合成数据进行深度学习训练的论文中提出了有趣的新想法。在我们的“向专家学习”中,我们还展示了如何即使是在与现实数据相结合下,都能使用专家系统来生成合成数据,并使用这些数据来训练深度学习系统的方法。最后,还有一个有趣的方法,就是使用“弱监管”来减少对大量手工标记数据的需要。Snorkel是一个非常有趣的项目,旨在通过提供一个通用框架来促进这种方法。
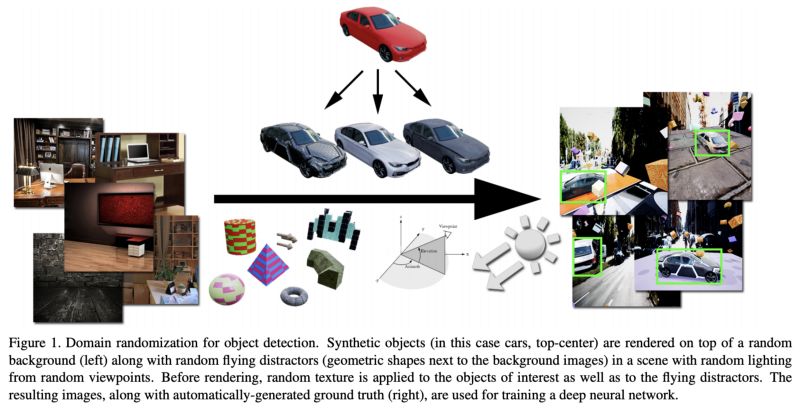
至于人工智能方面的更多基础性突破,可能是我和我的关注点,但我并没有看到太多。我不完全同意辛顿的观点,他说缺乏创新是因为这个领域有“一些资深人士和无数的年轻人”,尽管在科学领域确实存在一种趋势,即突破性研究是在较晚的年龄完成的。在我看来,目前缺乏突破的主要原因是现有方法和变化仍然有许多有趣的实际应用,所以很难冒险采用那些可能不太实际的方法。当该领域的大部分研究由大公司赞助时,这一点就更加重要了。无论如何,一篇对某些假设提出挑战的有趣论文是“对用于序列建模的通用卷积网络和循环网络的实证评估”。虽然它是高度经验主义并使用已知的方法,但它打开了发现新方法的大门,因为它证明了通常被认为是最佳的方法实际上不是最佳的。需要明确的是,我不同Bored Yann LeCun所认为的看法,即卷积网络是最终的“主宰算法”,而是认为RNN也不是。即使是序列建模也有很大的研究空间。另一篇具有高度探索性的论文是最近的NeurIPS最佳论文奖“神经常微分方程”,它挑战了深度学习中的一些基本内容,包括层本身的概念。

有趣的是,该论文的动机来自一个项目,作者在该项目中研究医疗数据(更具体地说,是电子健康记录)。我必须在这篇总结时提及人工智能和医疗保健交叉领域的研究,因为这是我在Curai的重点所在。不幸的是,在这个空间里发生了太多的事情,以至于我需要写另一篇文章。所以,我会指出在MLHC会议和ML4H NeurIPS研讨会上发表的论文。我们在Curai的团队成功地让论文在这两处都被接受,所以你会在许多有趣的论文中发现我们的论文,它们会让你了解我们的世界正在发生什么。
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
https://ai.yanxishe.com/page/TextTranslation/1380
AI研习社每日更新精彩内容,观看更多精彩内容:
用PyTorch来做物体检测和追踪
算法基础:五大排序算法Python实战教程
手把手:用PyTorch实现图像分类器(第一部分)
手把手:用PyTorch实现图像分类器(第二部分)
等你来译:
对混乱的数据进行聚类
初学者怎样使用Keras进行迁移学习
强化学习:通往基于情感的行为系统
一文带你读懂 WaveNet:谷歌助手的声音合成器

点击 阅读原文 查看本文更多内容↙











