

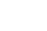
大家好!又到了每周一狗熊会的深度学习时间了。在前面的推送中,小编给大家介绍的DNN、CNN、RNN等网络都属于监督深度学习范畴。本讲以及下一讲,小编想要和大家介绍的是深度学习中生成模型。本讲先要介绍的是自编码器模型。作为一种无监督或者自监督算法,自编码器本质上是一种数据压缩算法。从现有情况来看,无监督学习很有可能是一把决定深度学习未来发展方向的钥匙,在缺乏高质量打标数据的监督机器学习时代,若是能在无监督学习方向上有所突破对于未来深度学习的发展意义重大。从自编码器到生成对抗网络,小编将和大家一起来探索深度学习中的无监督学习。

所谓自编码器(Autoencoder,AE),就是一种利用反向传播算法使得输出值等于输入值的神经网络,它现将输入压缩成潜在空间表征,然后将这种表征重构为输出。所以,从本质上来讲,自编码器是一种数据压缩算法,其压缩和解压缩算法都是通过神经网络来实现的。自编码器有如下三个特点:
数据相关性。就是指自编码器只能压缩与自己此前训练数据类似的数据,比如说我们使用mnist训练出来的自编码器用来压缩人脸图片,效果肯定会很差。
数据有损性。自编码器在解压时得到的输出与原始输入相比会有信息损失,所以自编码器是一种数据有损的压缩算法。
自动学习性。自动编码器是从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。
构建一个自编码器需要两部分:编码器(Encoder)和解码器(Decoder)。编码器将输入压缩为潜在空间表征,可以用函数f(x)来表示,解码器将潜在空间表征重构为输出,可以用函数g(x)来表示,编码函数f(x)和解码函数g(x)都是神经网络模型。
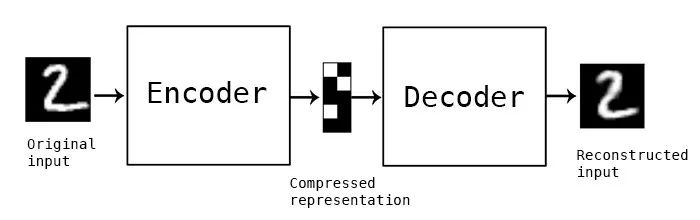
所以,我们大致搞清楚了自编码器是一种让输入等于输出的算法。但仅仅如此吗?当然不是,如果一个算法只是为了让输入等于输出,那这个算法意义肯定不大,自编码器的核心价值在于经编码器压缩后的潜在空间表征。上面我们提到自编码器是一种数据有损的压缩算法,经过这种有损的数据压缩,我们可以学习到输入数据种最重要的特征。
虽然自编码器对于我们是个新概念,但是其内容本身非常简单。在后面的keras实现中大家可以看到如何用几行代码搭建和训练一个自编码器。那么重要的问题来了,自编码器这样的自我学习模型到底有什么用呢?这个问题的答案关乎无监督学习在深度学习领域的价值,所以还是非常有必要说一下的。自编码器吸引了一大批研究和关注的主要原因之一是很长时间一段以来它被认为是解决无监督学习的可能方案,即大家觉得自编码器可以在没有标签的时候学习到数据的有用表达。但就具体应用层面上而言,自编码器通常有两个方面的应用:一是数据去噪,二是为进行可视化而降维。自编码器在适当的维度和系数约束下可以学习到比PCA等技术更有意义的数据映射。
上一节我们讲到自编码器的一个重要作用就是给数据进行降噪处理。给定mnist数据集,我们给原始数据添加一些噪声看看:
from keras.datasets import mnist
import numpy as np
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 1, 28, 28))
x_test = np.reshape(x_test, (len(x_test), 1, 28, 28))
# 给数据添加噪声
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
展示添加了噪声后的mnist数据示例:
# 噪声数据展示
n = 10
plt.figure(figsize=(20, 4))
for i in range(1, n):
ax = plt.subplot(2, n, i)
plt.imshow(x_train_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()

下面我们想要自编码器模型对上述经过噪声处理后的数据进行降噪和还原,我们使用卷积神经网络作为编码和解码模型:
from keras.layers import Input, Dense, UpSampling2D
from keras.layers import
Convolution2D, MaxPooling2D
from keras.models import Model
# 输入维度
input_img = Input(shape=(1, 28, 28))
# 基于卷积和池化的编码器
x = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(input_img)
x = MaxPooling2D((2, 2), border_mode='same')(x)
x = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(x)
encoded = MaxPooling2D((2, 2), border_mode='same')(x)
# 基于卷积核上采样的解码器
x = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Convolution2D(1, 3, 3, activation='sigmoid', border_mode='same')(x)
# 搭建模型并编译
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
对噪声数据进行自编码器的训练:
# 对噪声数据进行自编码训练
autoencoder.fit(x_train_noisy, x_train,
nb_epoch=100,
batch_size=128,
shuffle=True,
validation_data=(x_test_noisy, x_test))
经过卷积自编码器训练之后的噪声图像还原效果如下:

添加的噪声基本被消除了,可见自编码器确实是一种较好的数据降噪算法。原始的自编码器我们就讲到这里,下面我们再来看更加著名的变分自编码器。
3
变分自编码器
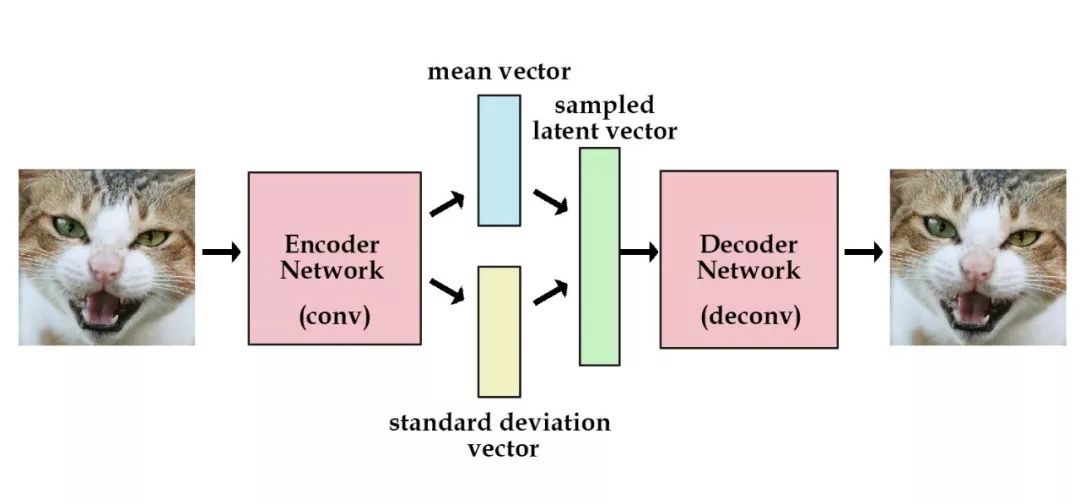
作为一种特殊的编码器模型,变分自编码器(Variational autoencoder,VAE)也是生成模型的两座大山之一(另一座是我们下一讲要说的生成对抗网络GAN),VAE特别适用于利用概念向量进行图像生成和编辑的任务。
经典的自编码器由于本身是一种有损的数据压缩算法,在进行图像重构时不会得到效果最佳或者良好结构的潜在空间表达,VAE则不是将输入图像压缩伟潜在空间的编码,而是将图像转换为最常见的两个统计分布参数——均值和标准差。然后使用这两个参数来从分布中进行随机采样得到隐变量,对隐变量进行解码重构即可。这是VAE的一段相当简洁的描述,实际上,因为概率图本身的抽象性,小编认为VAE不是一个容易理解模型。所以,本节小编就和大家一起来详细了解一下VAE的原理与机制。
生成模型与分布变换
在统计学习方法中,通过生成方法所学习到模型就是生成模型(generative model)(对应于判别方法和判别模型)。所谓生成方法,就是根据数据学习输入X和输出Y之间的联合概率分布,然后求出条件概率分布p(Y|X)作为预测模型的过程,这种模型便是生成模型。比如说咱们传统机器学习中的朴素贝叶斯模型和隐马尔可夫模型都是生成模型。
具体到深度学习和图像领域,生成模型也可以概括为用概率方式描述图像的生成,通过对概率分布采样产生数据。深度学习领域的生成模型的目标一般都很简单:就是根据原始数据构建一个从隐变量Z生成目标数据Y的模型,只是各个模型有着不同的实现方法。从概率分布的角度来解释就是构建一个模型将原始数据的概率分布转换到目标数据的概率分布,目标就是原始分布和目标分布要越像越好。所以,从概率论的角度来看,生成模型本质上就是一种分布变换。
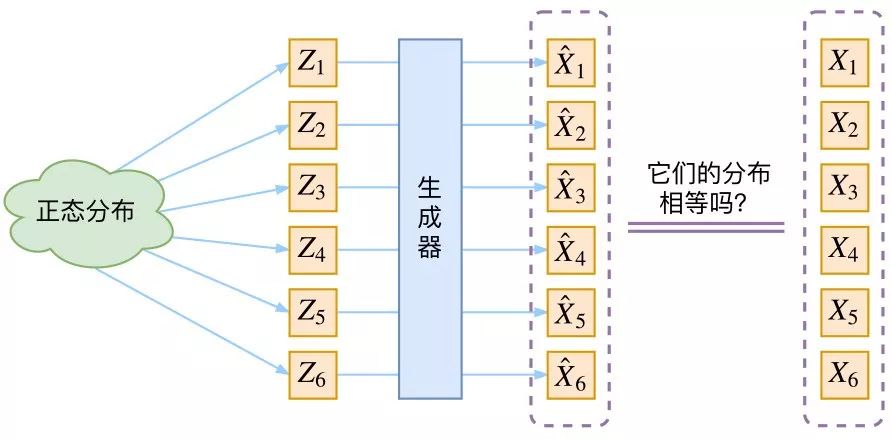
图片来自苏剑林科学空间站博客https://kexue.fm/
变分自编码器的原理
VAE的直观理解如下图所示:
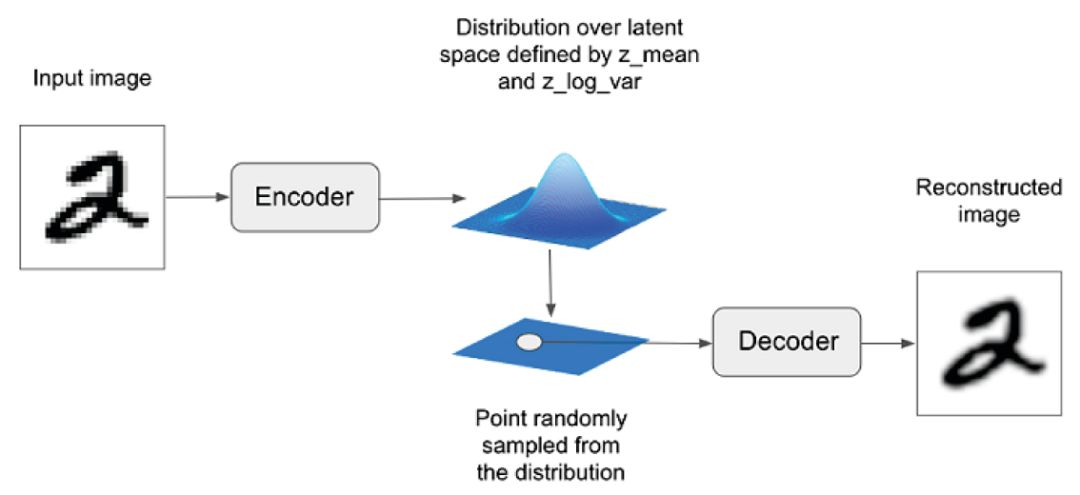
我们先根据图中的流程简述一下VAE的技术原理:
虽然上图的思路足够清晰,但恐怕还不能真正理解得了变分自编码器。我们来重新捋一捋整个思路流程。
假设我们有一批原始数据样本 {X1,…,Xn},可以用 X 来描述这个样本的总体,在X的分布 p(X) 知道的情况下,我们可以直接对 p(X) 这个概率分布进行采样,如果是这样的话,皆大欢喜,后面就没 VAE 什么事了。但事与愿违,正常情况下,原始样本的分布 p(X) 我们是不知道的。那我们只好退而求其次,看看能不能采用迂回的战术,通过对 p(X) 进行变换来推算 X 也行。于是我们可以将 p(X) 的分布表示为:
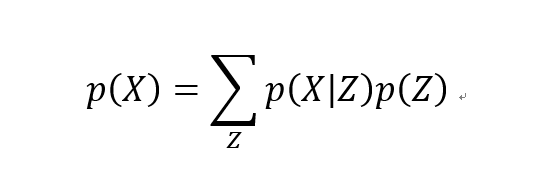
根据上式,p(X|Z) 描述了一个由 Z 来生成 X 的模型,而我们假设 Z 服从标准正态分布,也就是 p(Z)=N(0,I)。如果这条路能走得通的话,那么我们就可以先从标准正态分布中采样一个 Z,然后根据 Z 来算一个 X,这会是一个很优秀的生成模型。最后我们将这个模型结合自编码器进行表示,如下图所示:
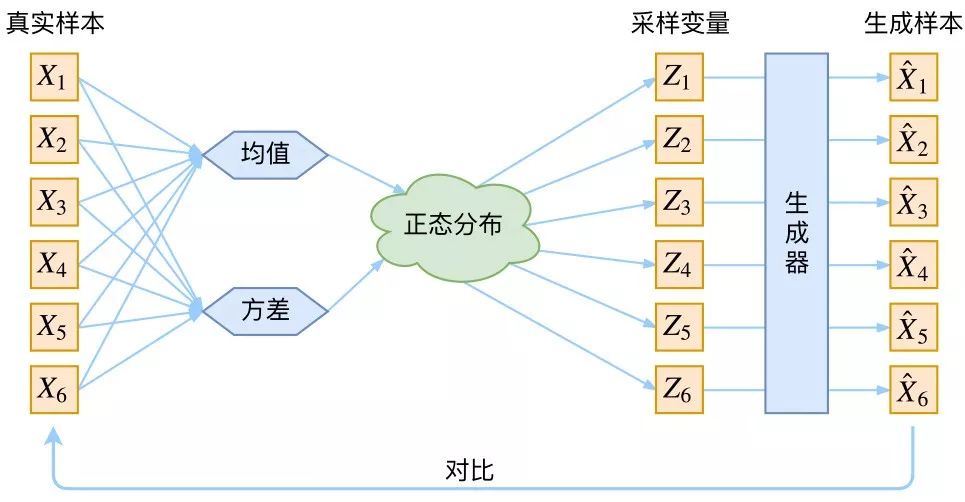
图片来自苏剑林科学空间站博客https://kexue.fm/
这幅图可以看作是 VAE 的一种更为直观的表达:通过对原始样本均值和方差的统计量计算,我们可以将数据编码成潜在空间的正态分布,然后对正态分布进行随机采样,将采样的结果进行解码结构,最后生成目标图像。一气呵成,皆大欢喜。其实不然,上图有一个关键问题在于:采样后的得到的Zk跟原始数据中的Xk是否还存在着一一对应的关系。这很关键,因为正是这种一一对应的关系才使得模型具备输入图像的重构能力。
根据上面的表述,实际的 VAE 其实是对每一个原始样本 Xk 配置了一个专属的正态分布。为什么是专属?因为我们后面要训练一个生成器 X=g(Z),希望能够把从分布 p(Z|Xk) 采样出来的一个 Zk 还原为 Xk。如果假设 p(Z) 是正态分布,然后从 p(Z) 中采样一个 Z,那么我们怎么知道这个 Z 对应于哪个真实的 X 呢?现在 p(Z|Xk) 专属于 Xk,我们有理由说从这个分布采样出来的 Z 应该要还原到 Xk 中去。还有一个问题就是,我们要怎样找出每一个 Xk 专属正态分布 p(Z|Xk) 的均值和方差呢?很简单,用神经网络进行拟合即可,有时候深度学习就是这么的粗暴。这样一来,我们就可以将上图中的 VAE 示意图修改成这样了:
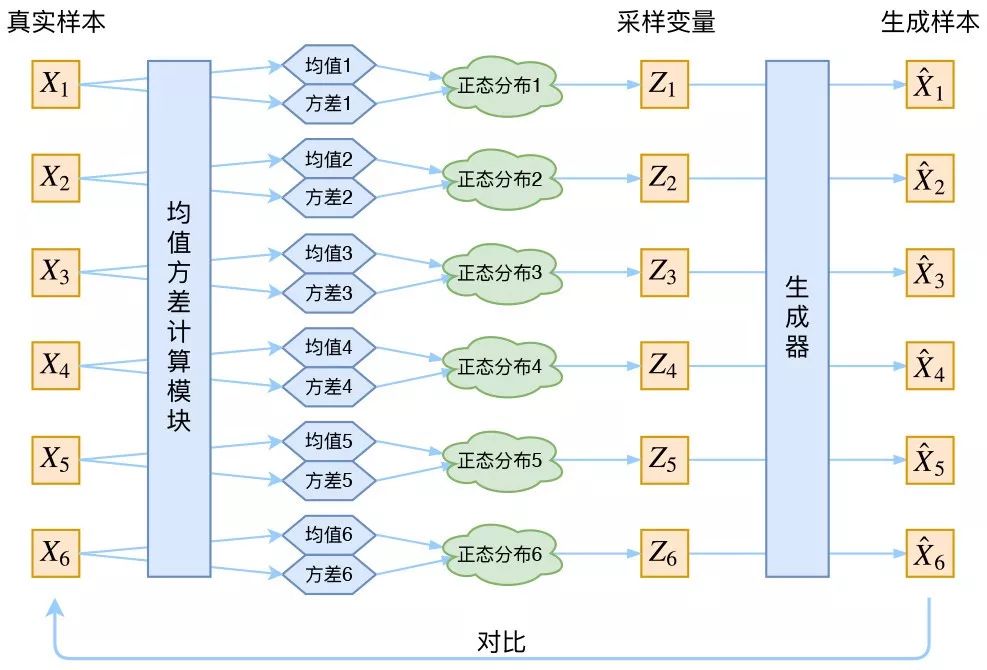
图片来自苏剑林科学空间站博客https://kexue.fm/
原来真正的 VAE 长这样!好了,我们基本搞清楚了,VAE 通过神经网络将原始数据进行均值和方差的潜在空间表征,然后将其描述为正态分布,再根据正态分布进行采样。下面我们把目光聚焦到正态分布和采样上来。
先来看正态分布。首先,我们希望重构 X,也就是最小化原始分布和目标分布之间的误差,但是这个重构过程受到噪声的影响,因为 Zk 是通过重新采样过的,不是直接由 encoder 算出来的。噪声的存在会增加数据重构的难度,但是我们知道均值和方差都在编码过程中由神经网络计算得到的,所以模型为了重构的更好,在这个过程中肯定会尽量让方差为向 0 靠近,但不能等于 0,等于 0 的话就失去了随机性,这样跟普通的自编码器就没什么区别了。
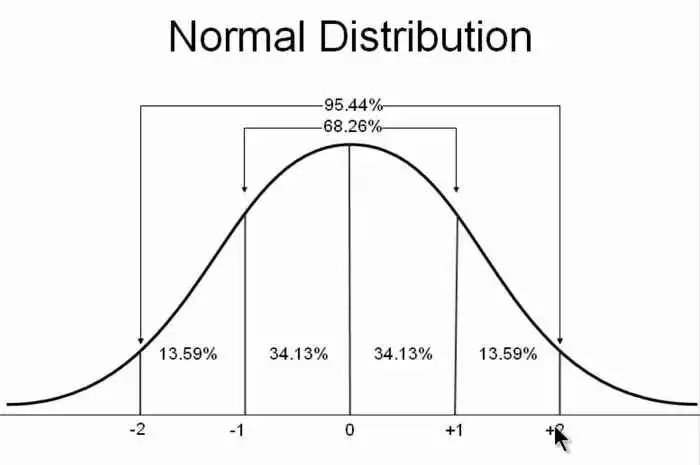
VAE 给出的一个办法在于让所有的专属正态分布都向 p(Z|Xk) 都向标准正态分布 N(0,1) 看齐,于是有下式:
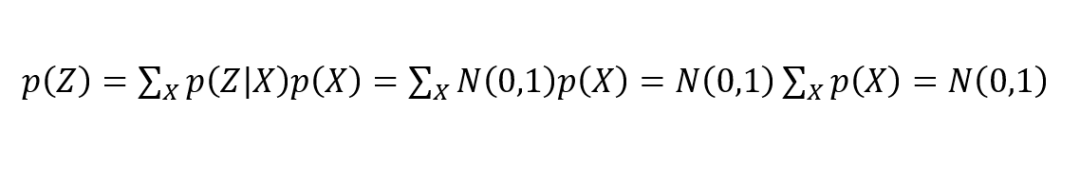
这样我们就能达到我们的先验假设:p(Z) 是标准正态分布。然后我们就可以放心地从 N(0,I) 中采样来生成图像了。所以说,VAE 为了使模型具有生成能力,模型要求每个 p(Z|Xk) 都努力向标准正态分布看齐。如下图所示:
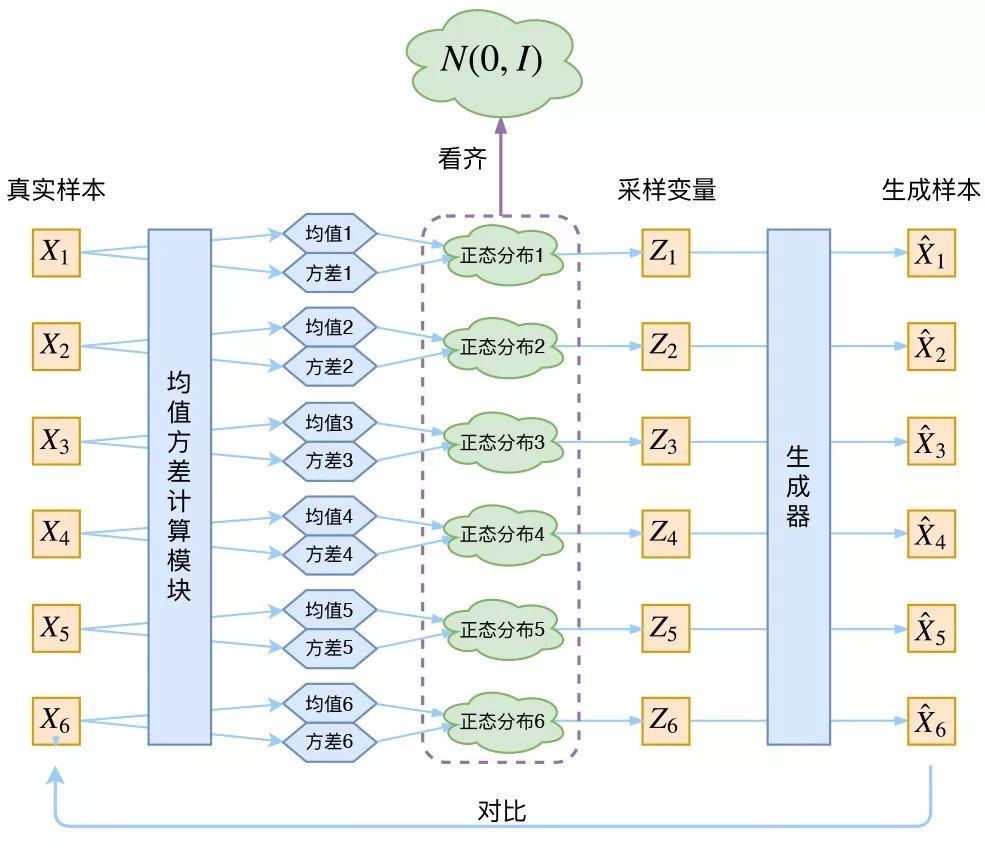
图片来自苏剑林科学空间站博客https://kexue.fm/
再来看采样。潜在空间表示为正态分布之后就是采样过程了。这里,VAE 的原始论文中提出一种参数复现(Reparameterization)的采样技巧。假设我们要从 p(Z|Xk) 中采样一个 Zk 出来,尽管我们知道了 p(Z|Xk) 是正态分布,但是均值方差都是靠模型算出来的,我们要靠这个过程反过来优化均值方差的模型,但是“采样”这个操作是不可导的,而采样的结果是可导的,于是我们利用了一个事实:从N(μ,σ^2) 中采样一个 Z,就相当于从 N(0,1) 中采样了一个 ε ,然后做一个 Z = μ+ ε*σ 的变换即可。如下图所示:
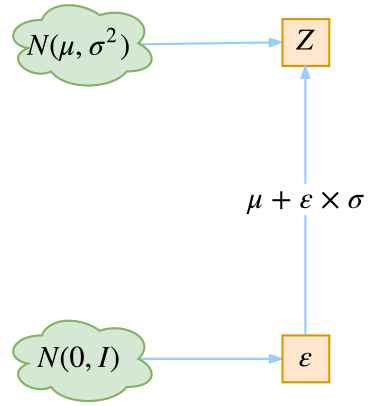
图片来自苏剑林科学空间站博客https://kexue.fm/
采样完了之后我们就可以用一个解码网络(生成器)来对采样结果进行解码重构了。
最后一个细节就是 VAE 训练的损失函数。VAE的参数训练由两个损失函数来训练,一个是重构损失函数,该函数要求解码出来的样本与输入的样本相似(与之前的自编码器相同),第二项损失函数是学习到的隐分布与先验分布的KL距离,可以作为一个正则化损失。具体损失函数公式这里不展开细说。
以上就是变分自编码器的基本和细节,当然还有很多内容笔者每有展开细谈,感兴趣的朋友可以找来 VAE 的原始论文进行研读。
变分的含义与VAE的本质
虽然已基本搞清楚了变分自编码器的基本细节和原理,但还有一些问题指值得我们继续探讨。大家注意到我们这个模型的名字叫做变分自编码器,但是我们讲到现在,好像也没有碰到变分的概念。所以,这里我们得捋一捋变分的含义。
什么是变分?应该学过泛函分析的朋友们都知道。所以,我们从泛函开始说起。大家都知道函数的概念在于变量之间的映射,输入一个数值返回的也是一个数值。而泛函则是函数的函数,所谓函数的函数,就是输入函数,返回的是数值,我们一般用积分的形式来表示泛函。这是函数与泛函的对比。
另外我们都知道函数有微分这一概念。函数的微分就是关于自变量 x 发生变化时对应函数值的变化量。将微分的概念推广到泛函就是变分的含义。所谓变分,就是自变量函数 x(t) 发生变化时,对应泛函值的变化量。所以,简单而言,变分就是泛函的微分。我们都知道微分可以用来求函数的极值,那么相应的变分就可以用来求泛函的极值,研究泛函机制的方法就是所谓的变分法(Variational Method)。
泛函和变分解释清楚了,那么 VAE 中好像确实没有用到变分啊?实际上,VAE 中的变分,在于损失函数推导过程利用了 KL 散度及其性质,而 KL 散度本身则是一个泛函: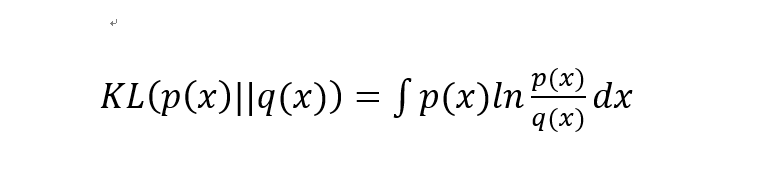
也许这就是变分自编码器中变分的含义。
作为自编码器的一种,VAE 有着自己的特殊性,但是其本质并不复杂。正如我们在文章开头所说的一样,VAE 的思想和框架其实很简单。VAE本质上就是在我们常规的自编码器的基础上,对 encoder 的结果(在VAE中对应着计算均值的网络)加上了“高斯噪声”,使得结果 decoder 能够对噪声有鲁棒性;而那个额外的 KL loss(目的是让均值为 0,方差为 1),事实上就是相当于对 encoder 的一个正则项,希望 encoder 出来的东西均有零均值。 而编码计算方差的网络的作用在于动态调节噪声的强度。到这里,变分自编码器的基本原理基本上就讲完了。最后一点内容,我们来看一下 keras 给出的 VAE 实现。
4
VAE的Keras实现
本小节小编用Keras给大家简单展示一下VAE的实现过程。
导入相关模块:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
from keras.layers import Input, Dense, Lambda
from keras.models import Model
from keras import backend as K
from keras import metrics
from keras.datasets import mnist
from keras.utils import to_categorical
设置模型相关参数:
batch_size = 100
original_dim = 784
latent_dim = 2
intermediate_dim = 256
epochs = 50
epsilon_std = 1.0
num_classes = 10
加载mnist数据集:
(x_train, y_train_), (x_test, y_test_) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
y_train = to_categorical(y_train_, num_classes)
y_test = to_categorical(y_test_, num_classes)
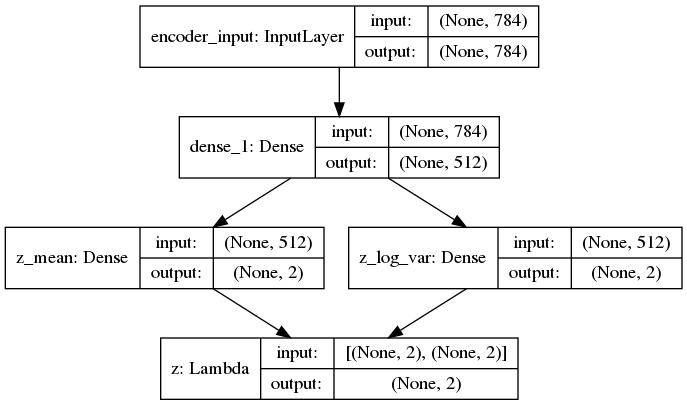
建立计算均值和方差的编码网络:
x = Input(shape=(original_dim,))
h = Dense(intermediate_dim, activation='relu')(x)
# 算p(Z|X)的均值和方差
z_mean = Dense(latent_dim)(h)
z_log_var = Dense(latent_dim)(h)
编码示意图:
定义参数复现技巧函数和抽样层:
# 参数复现技巧
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(K.shape(z_mean)[0], latent_dim), mean=0.,
stddev=epsilon_std)
return z_mean + K.exp(z_log_var / 2) * epsilon
# 重参数层,相当于给输入加入噪声
z = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_var])定义模型解码部分,即生成器:
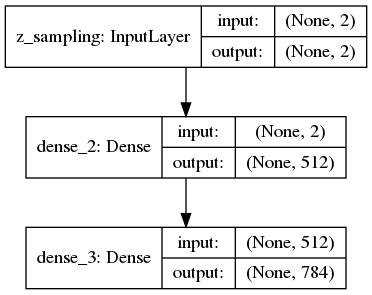
# 解码层,也就是生成器部分
decoder_h = Dense(intermediate_dim, activation='relu')
decoder_mean = Dense(original_dim, activation='sigmoid')
h_decoded = decoder_h(z)
x_decoded_mean = decoder_mean(h_decoded)
解码示意图:
接下来实例化三个模型:
# 端到端的vae模型
vae = Model(x, x_decoded_mean)
# 构建encoder,然后观察各个数字在隐空间的分布
encoder = Model(x, z_mean)
# 构建生成器
decoder_input = Input(shape=(latent_dim,))
_h_decoded = decoder_h(decoder_input)
_x_decoded_mean = decoder_mean(_h_decoded)
generator = Model(decoder_input, _x_decoded_mean)
定义 VAE 损失函数并进行训练:
# xent_loss是重构loss,kl_loss是KL loss
xent_loss = original_dim * metrics.binary_crossentropy(x, x_decoded_mean)
kl_loss = - 0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)
vae_loss = K.mean(xent_loss + kl_loss)
# add_loss是新增的方法,用于更灵活地添加各种lossvae.add_loss(vae_loss)
vae.compile(optimizer='rmsprop', loss=None)
vae.summary()
vae.fit(x_train,
shuffle=True,
epochs=epochs,
batch_size=batch_size,
validation_data=(x_test, None))
模型概要:
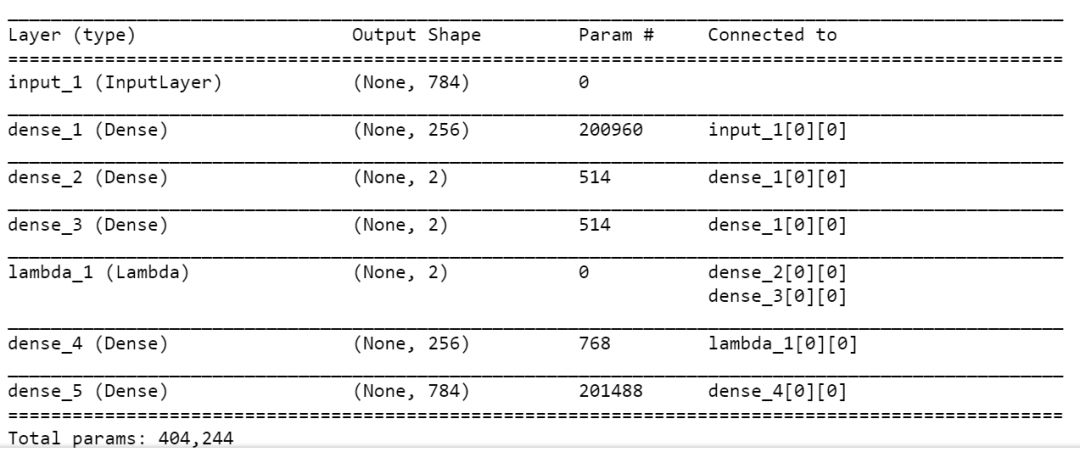
模型训练过程:
因为变分编码器是一个生成模型,我们可以用它来生成新数字。我们可以从隐平面上采样一些点,然后生成对应的显变量,即MNIST的数字:
# 观察隐变量的两个维度变化是如何影响输出结果的
n = 15
# figure with 15x15 digits
digit_size = 28
figure = np.zeros((digit_size * n, digit_size * n))
#用正态分布的分位数来构建隐变量对
grid_x = norm.ppf(np.linspace(0.05, 0.95, n))
grid_y = norm.ppf(np.linspace(0.05, 0.95, n))
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z_sample = np.array([[xi, yi]])
x_decoded = generator.predict(z_sample)
digit = x_decoded[0].reshape(digit_size, digit_size)
figure[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit
plt.figure(figsize=(10, 10))
plt.imshow(figure, cmap='Greys_r')
plt.show()
生成手写数字图片如下:

以上便是本讲内容。
本节内容有一点多,小编对深度生成模型中的自编码器模型进行了相对详细的介绍。对原始的自编码器及其简单实现、变分自编码器的原理、与概率图模型的一些关系以及基于Keras的简单实现都进行了较为细致的讲解。在此,特别感谢科学空间站站长、中山大学的苏剑林在科学空间上的几篇关于生成模型和自编码器的文章,帮助小编解决了很多疑惑,并且这篇文章也借用了文章中的几幅图片以及部分细节着重进行了参考,在此一并表示感谢。咱们下一期见!
【参考资料】
https://blog.keras.io/building-autoencoders-in-keras.html
深度学习 Ian GoodFellow
https://zhuanlan.zhihu.com/p/34238979
Auto-Encoding Variational Bayes
https://kexue.fm/
paperweekly 苏剑林 变分自编码器VAE:原来是这么一回事
Tutorial on Variational Autoencoders
作者简介
鲁伟,狗熊会人才计划一期学员。目前在杭州某软件公司从事数据分析和深度学习相关的研究工作,研究方向为贝叶斯统计、计算机视觉和迁移学习。

识别二维码,查看作者更多精彩文章
识别下方二维码成为狗熊会会员!
友情提示:
个人会员不提供数据、代码,
视频only!
个人会员网址:http://teach.xiong99.com.cn












