
本文为 AI 研习社编译的技术博客,原标题 :
Snagging Parking Spaces with Mask R-CNN and Python
作者 | Adam Geitgey
翻译 | Vincents
校对 | 邓普斯•杰弗 审核 | 酱番梨 整理 | 立鱼王
原文链接:
https://medium.com/@ageitgey/snagging-parking-spaces-with-mask-r-cnn-and-python-955f2231c400
注:本文的相关链接请点击文末【阅读原文】进行访问
 我住在一个大城市。 但就像大多数城市一样,在这里寻找停车位总是一件很困难的事情。 停车位通常很快被抢走,即使你有一个专门的停车位,朋友们来拜访你也是一件很困难的事,因为他们找不到停车位。
我住在一个大城市。 但就像大多数城市一样,在这里寻找停车位总是一件很困难的事情。 停车位通常很快被抢走,即使你有一个专门的停车位,朋友们来拜访你也是一件很困难的事,因为他们找不到停车位。
我的解决方案是将一个摄像头指向窗外并使用深度学习让我的计算机在新的停车位出现的时候给我发短信:
 这可能听起来相当复杂,但是使用深度学习构建这个工作实际上非常快速且简单。 因为所有需要的工具都可用 - 你只需知道在哪里找到这些工具以及如何将它们组合在一起。
这可能听起来相当复杂,但是使用深度学习构建这个工作实际上非常快速且简单。 因为所有需要的工具都可用 - 你只需知道在哪里找到这些工具以及如何将它们组合在一起。
因此,让我们花几分钟时间建立一个高精度的停车位通知系统,使用Python和深度学习!
拆分问题
当我们想要通过机器学习解决一个复杂的问题时,第一步是将问题分解为简单任务的序列。 然后,使用拆分的方法,我们可以从我们的机器学习工具箱中使用不同的工具来解决每一个较小的任务。 通过将几个小的解决方案链接到一个流水线中,于是我们将拥有一个可以执行复杂操作的系统。
下面是我如何将检测空闲的停车位的问题拆分到流水线中:
 机器学习流程图的输入是来自指向窗口的普通网络摄像头的视频流:
机器学习流程图的输入是来自指向窗口的普通网络摄像头的视频流:

从网络摄像头中的样例视频
我们将视频的每一帧通过该流水线,一次一帧。
流水线的第一步是检测视频帧中所有可能的停车位。 显然,我们需要知道图像的哪些部分是停车位才能检测到哪些停车位未被占用。
第二步是检测每帧视频中的所有汽车。 我们将逐帧跟踪每辆车的移动。
第三步是确定哪些停车位目前被汽车占用,哪些不是。 这需要结合第一步和第二步的结果。
最后一步是在停车位可用的时候发送通知。 这将基于视频帧之间的汽车位置的变化。
我们可以使用各种技术以多种不同方式完成这些步骤。 构建此流水线没有唯一的正确或错误的方法,不同的方法将有不同的优点和缺点。 让我们来看看每一步的具体过程吧!
以下是我们的摄像机的视图:
 我们需要能够扫描该图像并找回有效的停车位的列表,如下所示:
我们需要能够扫描该图像并找回有效的停车位的列表,如下所示:
 这个城市街道上的有效停车位
这个城市街道上的有效停车位
偷懒的方法是手动将每个停车位的位置硬编码到程序中,而不是试图使用自动检测停车位。 但是如果我们移动相机或想要检测不同街道上的停车位,我们必须再次手动硬编码停车位。 这样就很糟糕,所以让我们需要找到一种自动检测停车位的方法。
可能有一种想法是,寻找停车计时器并假设每个计量表旁边都有一个停车位:

检测图像中的停车计时器
但是这种方法存在一定的复杂性。 首先,并非每个停车位都有停车计时器——事实上,我们最感兴趣的是找到我们无需付费的停车位! 其次,只知道停车计时器的位置并不能确切地告诉我们停车位的确切位置。 这只能让我们离目标更接近一点。
另一个想法是建立一个物体检测模型,寻找在道路上绘制的停车位哈希标记,如下所示:
 注意那些微小的黄色标记 - 这些是在道路上绘制每个停车位的边界的地方
注意那些微小的黄色标记 - 这些是在道路上绘制每个停车位的边界的地方
但这种做法也很困难。 首先,我所在城市的停车位线标记非常小,从远处很难看到,所以用电脑也难以检测。 第二,街道上到处都是各种不相关的线条和标记。 很难分清楚哪条线是停车位以及哪条线是车道分隔线或人行横道。
每当您遇到一个看似困难的问题时,请花几分钟时间看看您是否能够采用不同的方式来解决避免某些技术上的挑战。 到底什么是停车位呢? 停车场只是停车场很长一段时间的地方。 所以也许我们根本不需要检测停车位。 我们为什么不能只检测那些长时间不动的车并假设它们在停车位?
换句话说,有效的停车位只是一些车辆长时间不动的地方:
 这里每辆车的边界框实际上都是一个停车位! 如果我们能够检测到静止的汽车,我们不需要实际检测停车位。
这里每辆车的边界框实际上都是一个停车位! 如果我们能够检测到静止的汽车,我们不需要实际检测停车位。
因此,如果我们能够检测到汽车,并找出那些在视频帧之间不移动的车辆,我们就可以推断停车位的位置。 这将会很容易 - 那么让我们继续检测汽车!
在视频帧中检测汽车是教科书式的对象检测问题。 我们可以使用许多机器学习方法来检测图像中的对象。 以下是一些最常见的对象检测算法,从“旧方法”到“新方法”:
训练一个HOG(方向梯度直方图)物体探测器并将其滑动通过我们的图像以找到所有的汽车。 这种较旧的非深度学习的方法运行起来相对较快,但是它不能很好地处理在不同方向上旋转的汽车。
训练CNN(卷积神经网络)物体探测器并将其滑动通过我们的图像,直到我们找到所有的汽车。 这种方法是准确的,但效率不高,因为我们必须使用CNN多次扫描图像才能找到整个图像中的所有汽车。虽然它可以很容易地找到以不同方向旋转的汽车,但它需要比基于HOG的物体探测器更多的训练数据。
使用更新的深度学习方法,如Mask R-CNN,Faster R-CNN或YOLO,将CNN的准确性与巧妙的设计和高效的技巧相结合,大大加快了检测过程。 只要我们有大量训练数据来训练模型,它将能够相对较快地(在GPU上)运行。
一般来说,我们希望选择最简单的解决方案,以最少的训练数据完成工作,而不是假设我们需要最新或是最花哨的算法。 但在这种特殊情况下,Mask R-CNN是一个合理的选择,尽管它又新又相当华丽。
Mask R-CNN架构以这样一种方式设计,即在不使用滑动窗口方法的情况下以计算有效的方式检测整个图像上的对象。 换句话说,它运行得相当快。 使用现代GPU,我们应该能够以每秒几帧的速度检测高分辨率视频中的对象。 对于这个项目来说应该没问题。
此外,Mask R-CNN为我们提供了有关每个检测到的对象的大量信息。 大多数对象检测算法仅返回每个对象的边界框。 但Mask R-CNN不仅会给我们每个对象的位置,还会给我们一个对象轮廓(或掩码),如下所示:
 为了训练Mask R-CNN,我们需要大量我们想要检测的物种对象的图片。 我们可以去外面拍摄汽车照片并追踪这些照片中的所有汽车,但这需要几天的工作。 幸运的是,汽车是许多人想要检测的常见物体,因此汽车图像的几个公共数据集已经存在。
为了训练Mask R-CNN,我们需要大量我们想要检测的物种对象的图片。 我们可以去外面拍摄汽车照片并追踪这些照片中的所有汽车,但这需要几天的工作。 幸运的是,汽车是许多人想要检测的常见物体,因此汽车图像的几个公共数据集已经存在。
有一个非常流行的数据集名为COCO(Common Objects In Context),其中包含使用对象掩码注释的图像。 在此数据集中,已经标注了超过12,000张汽车图像。 这是COCO数据集中的一个图像:
 一张已经标注的COCO数据集中的图片
一张已经标注的COCO数据集中的图片
该数据非常适合训练Mask R-CNN模型。
等等,还有更好的事情! 由于想要使用COCO数据集构建对象检测模型是如此常见,因此很多人已经完成并共享了他们的结果。 因此,我们可以从预先训练好的模型开始,而不是训练我们自己的模型,该模型可以开箱即用地检测汽车。 对于这个项目,我们将使用来自Matterport的大型开源Mask R-CNN实现,它带有预训练的模型。
旁注:不要害怕训练自定义的Mask R-CNN物体探测器! 标注数据是花费时间的,但并不困难。 如果您想使用自己的数据训练自定义Mask R-CNN模型,请查看我的书。
如果我们在相机图像上运行预先训练的模型,这就是直接检测到的模型:
 我们的图像中默认的COCO对象被检测 - 汽车,人,交通灯和树
我们的图像中默认的COCO对象被检测 - 汽车,人,交通灯和树
我们不仅检测到了汽车,而且我们也得到交通信号灯和人员等信息。 并且滑稽地,它将其中一棵树确定为“盆栽植物”。
对于图像中检测到的每个对象,我们从Mask R-CNN模型中获取四件事:
检测到的对象类型(是一个整数)。 经过预培训的COCO模型知道如何检测80种不同的常见物体,如汽车和卡车。 这里是它们的完整列表。
物体检测的置信度得分。 数字越大,模型就越能确定正确识别对象。
图像中对象的边界框,以X / Y像素位置给出。
位图“掩码”,用于指示边界框内的哪些像素是对象的一部分,哪些不是。 使用掩码数据,我们还可以计算出对象的轮廓。
下面是使用Matterport的Mask R-CNN实现的预训练模型以及OpenCV来检测汽车边界框的Python代码:
import os
import numpy as np
import cv2
import mrcnn.config
import mrcnn.utils
from mrcnn.model import MaskRCNN
from pathlib import Path
class MaskRCNNConfig(mrcnn.config.Config):
NAME = "coco_pretrained_model_config"
IMAGES_PER_GPU = 1
GPU_COUNT = 1
NUM_CLASSES = 1 + 80
DETECTION_MIN_CONFIDENCE = 0.6
def get_car_boxes(boxes, class_ids):
car_boxes = []
for i, box in enumerate(boxes):
if class_ids[i] in [3, 8, 6]:
car_boxes.append(box)
return np.array(car_boxes)
ROOT_DIR = Path(".")
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
if not os.path.exists(COCO_MODEL_PATH):
mrcnn.utils.download_trained_weights(COCO_MODEL_PATH)
IMAGE_DIR = os.path.join(ROOT_DIR, "images")
VIDEO_SOURCE = "test_images/parking.mp4"
model = MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=MaskRCNNConfig())
model.load_weights(COCO_MODEL_PATH, by_name=True)
parked_car_boxes = None
video_capture = cv2.VideoCapture(VIDEO_SOURCE)
while video_capture.isOpened():
success, frame = video_capture.read()
if not success:
break
rgb_image = frame[:, :, ::-1]
results = model.detect([rgb_image], verbose=0)
r = results[0]
car_boxes = get_car_boxes(r['rois'], r['class_ids'])
print("Cars found in frame of video:")
for box in car_boxes:
print("Car: ", box)
y1, x1, y2, x2 = box
cv2.rectangle(frame, (x1, y1), (x2, y2), (0
, 255, 0), 1)
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video_capture.release()
cv2.destroyAllWindows()
当您运行该脚本时,您将在屏幕上看到一个图像,每个检测到的汽车周围都有一个框,如下所示:
 每辆检测到的汽车都被绿色矩形框起来
每辆检测到的汽车都被绿色矩形框起来
并且您还可以在控制台中打印的每个检测到的汽车的像素坐标,如下所示:
Cars found in frame of video:
Car: [492 871 551 961]
Car: [450 819 509 913]
Car: [411 774 470 856]
目前,我们已成功检测到图像中的汽车。 让我们进行下一步!
我们知道图像中每辆车的像素位置。 通过连续观看多个视频帧,我们可以轻松地确定哪些车辆没有移动,并假设这些区域是停车位。 但是,我们如何检测汽车何时离开停车位?
有一个问题是我们图像中汽车的边界框会部分重叠:

即使对于不同停车位的汽车,每辆汽车的边界框也会重叠一点。
因此,如果我们假设每个边界框代表一个停车位,那么即使停车位是空的,也可能有一部分被其他汽车占用。 我们需要一种方法来测量两个对象重叠的程度,以便检查“大多数空闲”的框。
我们将使用的措施称为Intersection Over Union或IoU。 通过查找两个对象重叠的像素数量并将其除以两个对象所覆盖的像素数量来计算IoU,如下所示:
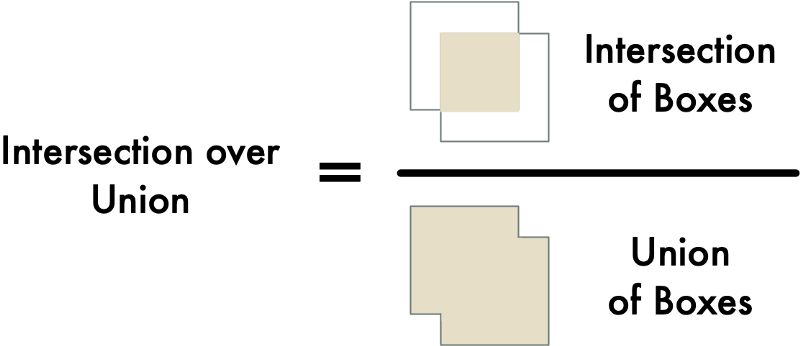
这将为我们提供汽车边界框与停车位边界框重叠的程度。 有了这个,我们可以很容易地确定汽车是否在停车位。 如果IoU测量值很低,如0.15,那意味着汽车并没有真正占用大部分停车位。 但如果措施很高,如0.6,这意味着汽车占据了大部分停车位区域,因此我们可以确定该停车位被占用。
由于IoU是计算机视觉中常见的测量方法,因此您使用的库通常已经实现了它。 事实上,Matterport Mask R-CNN库中已经包含了一个函数名为mrcnn.utils.compute_overlaps(),因此我们可以使用该函数。
假设我们有一个表示我们图像中停车区域的边界框列表,检查检测到的车辆是否在这些边界框内,就像添加一行或两行代码一样简单:
car_boxes = get_car_boxes(r['rois'], r['class_ids'])
overlaps = mrcnn.utils.compute_overlaps(car_boxes, parking_areas)
print(overlaps)
结果如下:
[
[1. 0.07040032 0. 0.]
[0.07040032 1. 0.07673165 0.]
[0. 0. 0.02332112 0.]
]
在该2D阵列中,每行代表一个停车位边界框。同样,每列代表一个检测到的汽车与停车位重叠的程度。 1.0得分意味着汽车完全占据空间而0.02这样的低分意味着汽车占但不占据大部分区域。
要查找未占用的停车位,我们只需要检查此阵列中的每一行。如果所有数字都为零或非常小,那意味着没有任何东西占据那个空间,那么这个停车位将会是空闲的!
但请记住,对象检测并不总是与实时视频完美配合。即使Mask R-CNN非常准确,偶尔也会在单帧视频中错过一两辆车。因此,在将停车位标记为空闲之前,我们应该确保它在一段时间内保持空闲 - 可能是5或10个连续的视频帧。这将阻止系统错误地检测开放的停车位,因为物体检测在一帧视频上有暂时的小失误。但是,只要我们看到我们至少有一个停车位可以自由连续几帧视频,我们就可以发送短信!
我们的流水线的最后一步是,当我们发现停车位在几个视频帧的都是空闲时发送短信提醒。
使用Twilio从Python发送SMS消息非常简单。 Twilio是一种流行的API,它允许您使用几行代码从基本上任何编程语言发送SMS消息。 当然,如果您更喜欢使用其他SMS服务供应商,则可以使用它。 我没有Twilio的股份(不是打广告)。我只是第一反应想到了它。
要使用Twilio,请注册试用帐户,创建Twilio电话号码并获取您的帐户凭据。 然后,您需要安装Twilio Python客户端库:
安装完成后,这是用Python发送SMS消息的完整代码(只需用您自己的帐户详细信息替换值):
from twilio.rest import Client
twilio_account_sid = 'Your Twilio SID here'
twilio_auth_token = 'Your Twilio Auth Token here'
twilio_source_phone_number = 'Your Twilio phone number here'
client = Client(twilio_account_sid, twilio_auth_token)
message = client.messages.create(
body="This is my SMS message!",
from_=twilio_source_phone_number,
to="Destination phone number here"
)
为了向我们的脚本添加短信发送功能,我们可以直接删除该代码。但我们需要注意的是,我们不会在免费停车位空闲时候的视频的每一帧都发送自己的短信。 所以我们需要有一个标志来跟踪我们是否已经发送短信并确保我们不会发送另一个短信,直到经过一定的时间或者检测到不同的停车位空闲。
把全部连起来
让我们将流水线的每一步组装成一个Python脚本。 这是完整的代码:
import os
import numpy as np
import cv2
import mrcnn.config
import mrcnn.utils
from mrcnn.model import MaskRCNN
from pathlib import Path
from twilio.rest import Client
class MaskRCNNConfig(mrcnn.config.Config):
NAME = "coco_pretrained_model_config"
IMAGES_PER_GPU = 1
GPU_COUNT = 1
NUM_CLASSES = 1 + 80
DETECTION_MIN_CONFIDENCE = 0.6
def get_car_boxes(boxes, class_ids):
car_boxes = []
for i, box in enumerate(boxes):
if class_ids[i] in
[3, 8, 6]:
car_boxes.append(box)
return np.array(car_boxes)
twilio_account_sid = 'YOUR_TWILIO_SID'
twilio_auth_token = 'YOUR_TWILIO_AUTH_TOKEN'
twilio_phone_number = 'YOUR_TWILIO_SOURCE_PHONE_NUMBER'
destination_phone_number = 'THE_PHONE_NUMBER_TO_TEXT'
client = Client(twilio_account_sid, twilio_auth_token)
ROOT_DIR = Path(".")
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
if not os.path.exists(COCO_MODEL_PATH):
mrcnn.utils.download_trained_weights(COCO_MODEL_PATH)
IMAGE_DIR = os.path.join(ROOT_DIR, "images")
VIDEO_SOURCE = "test_images/parking.mp4"
model = MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=MaskRCNNConfig())
model.load_weights(COCO_MODEL_PATH, by_name=True)
parked_car_boxes = None
video_capture = cv2.VideoCapture(VIDEO_SOURCE)
free_space_frames = 0
sms_sent = False
while video_capture.isOpened():
success, frame = video_capture.read()
if not success:
break
rgb_image = frame[:, :, ::-1]
results = model.detect([rgb_image], verbose=0)
r = results[0]
if parked_car_boxes is None:
parked_car_boxes = get_car_boxes(r['rois'], r['class_ids'])
else:
car_boxes = get_car_boxes(r['rois'], r['class_ids'])
overlaps = mrcnn.utils.compute_overlaps(parked_car_boxes, car_boxes)
free_space = False
for parking_area, overlap_areas in zip(parked_car_boxes, overlaps):
max_IoU_overlap = np.max(overlap_areas)
y1, x1, y2, x2 = parking_area
if max_IoU_overlap < 0.15
:
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 3)
free_space = True
else:
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 0, 255), 1)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, f"{max_IoU_overlap:0.2}", (x1 + 6, y2 - 6), font, 0.3, (255, 255, 255))
if free_space:
free_space_frames += 1
else:
free_space_frames = 0
if free_space_frames > 10:
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, f"SPACE AVAILABLE!", (10, 150), font, 3.0, (0
, 255, 0), 2, cv2.FILLED)
if not sms_sent:
print("SENDING SMS!!!")
message = client.messages.create(
body="Parking space open - go go go!",
from_=twilio_phone_number,
to=destination_phone_number
)
sms_sent = True
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video_capture.release()
cv2.destroyAllWindows()
要运行此代码,您需要先安装Python 3.6 +,Matterport Mask R-CNN和OpenCV。
我故意将代码尽可能地简洁。 例如,它只是假设第一帧视频中存在的任何车辆都是停放的汽车。 你可以试着运行一下,看看你是否可以提高它的可靠性。
不要害怕为了适应不同的场景而调整代码。 您只需更改模型所需的对象ID,就可以将代码完全转换为其他内容。 例如,假设您在滑雪胜地工作。 通过一些调整,您可以将此脚本转换为一个系统,可以自动检测从斜坡上跳下的雪板,并为很酷的滑雪板跳跃进行高亮显示。 或者如果你在野生动物保护区工作,你可以把它变成一个计算野外斑马数目的系统。 唯一的限制是你的想象力。祝你玩得开心!
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
https://ai.yanxishe.com/page/TextTranslation/1457
AI研习社每日更新精彩内容,观看更多精彩内容:
CVPR 2018 最牛逼的十篇论文
深度学习目标检测算法综述
迷你自动驾驶汽车深度学习特征映射的可视化
在2018年用“笨办法”学数据科学体会分享
等你来译:
如何在神经NLP处理中引用语义结构
深度学习不同类型卷积的综合介绍——通过可视化直观理解卷积
高级DQNs:利用深度强化学习玩吃豆人游戏
深度强化学习新趋势:谷歌如何把好奇心引入强化学习智能体









