高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
假设系统一直能够提供服务,我们说系统的可用性是100%。如果系统每运行100个时间单位,会有1个时间单位无法提供服务,我们说系统的可用性是99%。很多公司的高可用目标是4个9,也就是99.99%,这就意味着,系统的年停机时间为8.76个小时。
百度的搜索首页,是业内公认高可用保障非常出色的系统,甚至人们会通过www.baidu.com 能不能访问来判断“网络的连通性”,百度高可用的服务让人留下啦“网络通畅,百度就能访问”,“百度打不开,应该是网络连不上”的印象,这其实是对百度HA最高的褒奖。
1. MySQL高可用
说到MySQL的高可用,不得不提到复制,复制是MySQL高可用的基础。复制解决了什么问题呢?
实现数据备份
如果有从服务器,主服务器发生故障之后,开通从服务器的写入功能,从而提供高可用的使用功能
异地容灾
分摊负载(scale out )主服务器:写、从服务器:读
1.1 主从复制流程
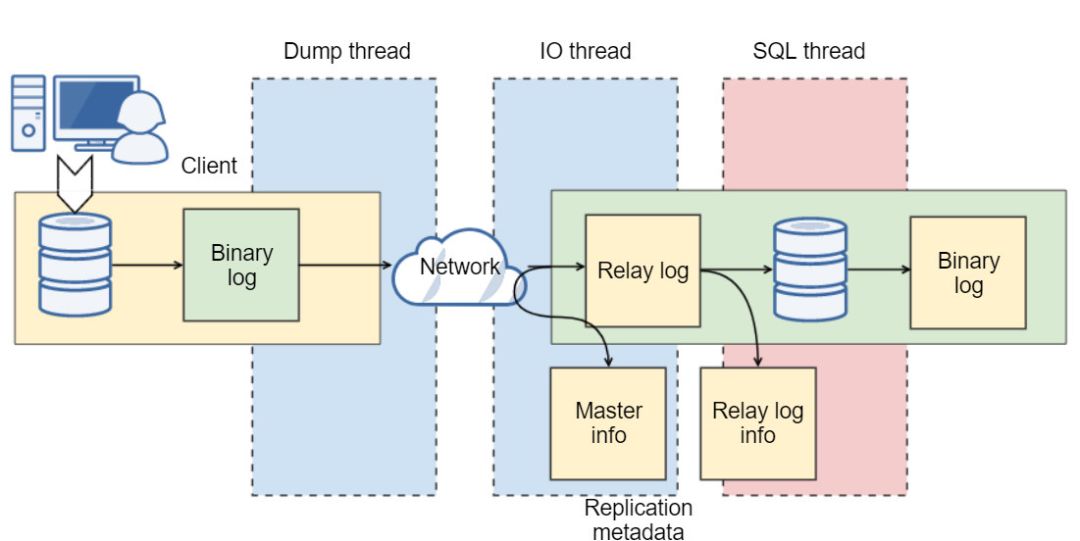
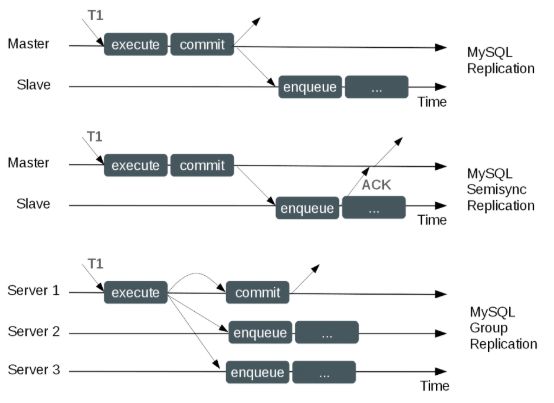
不同的复制协议:
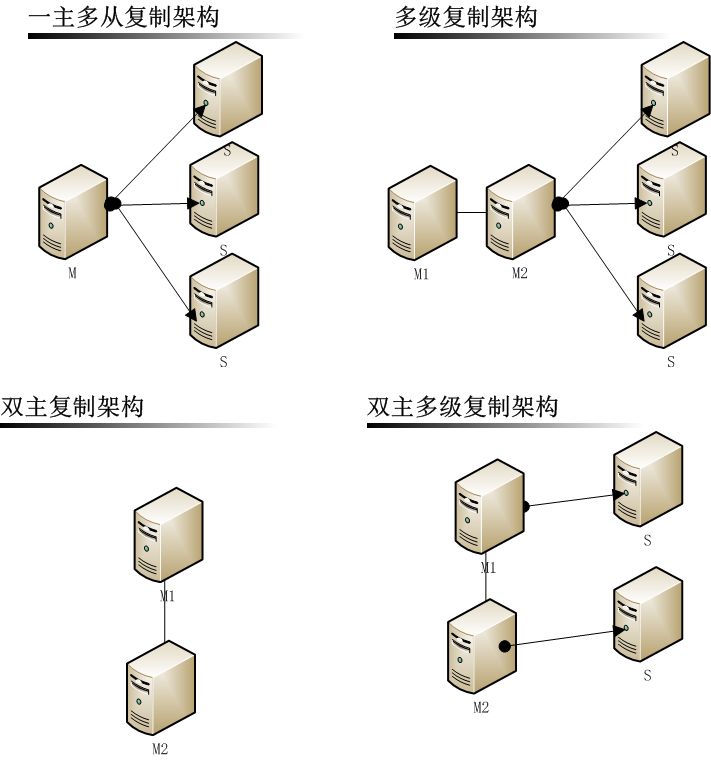
1.2 高可用复制架构
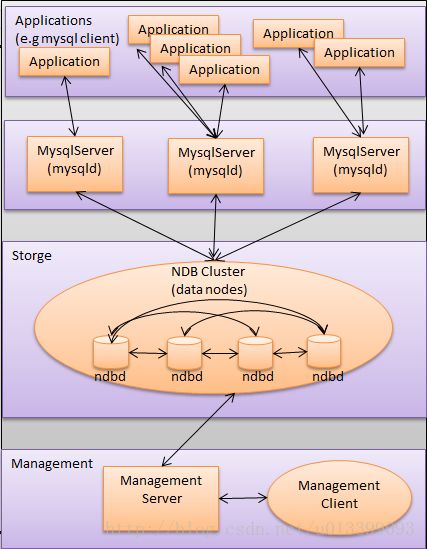
1.3.mysql 高可用架构
1.3.1 MySQL Cluster架构
限制存储引擎为NDB存储引擎:
1.3.2 MySQL+MMM架构
MMM即Master-Master Replication Manager for
MySQL(mysql主主复制管理器),是关于mysql主主复制配置的监控、故障转移和管理的一套可伸缩的脚本套件(在任何时候只有一个节点可以被写入),这个套件也能基于标准的主从配置的任意数量的从服务器进行读负载均衡,所以你可以用它来在一组居于复制的服务器启动虚拟ip,除此之外,它还有实现数据备份、节点之间重新同步功能的脚本。
MySQL本身没有提供replication failover的解决方案,通过MMM方案能实现服务器的故障转移,从而实现mysql的高可用。
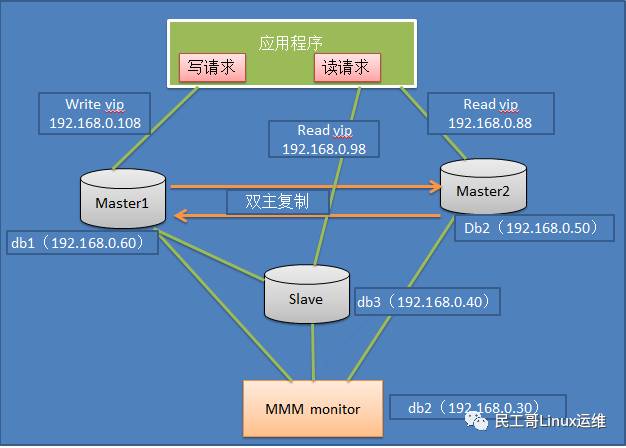
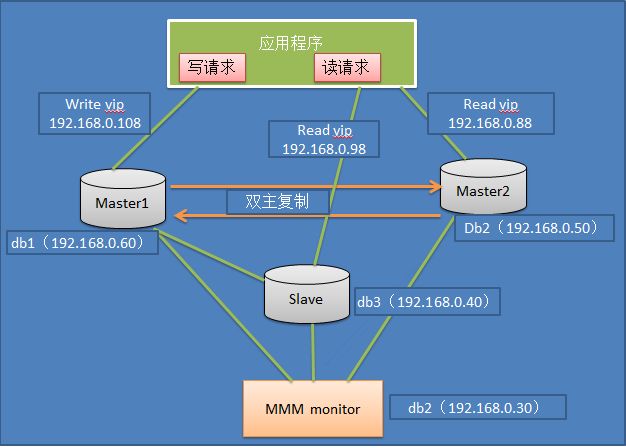
此方案特点:
1、安全、稳定性较高,可扩展性好
2、 对服务器数量要求至少三台及以上
3、 对双主(主从复制性要求较高)
4、 同样可实现读写分离
1.3.3 MySQL+MHA架构
MHA目前在MySQL高可用方案中应该也是比较成熟和常见的方案,它由日本人开发出来,在MySQL故障切换过程中,MHA能做到快速自动切换操作,而且还能最大限度保持数据的一致性。
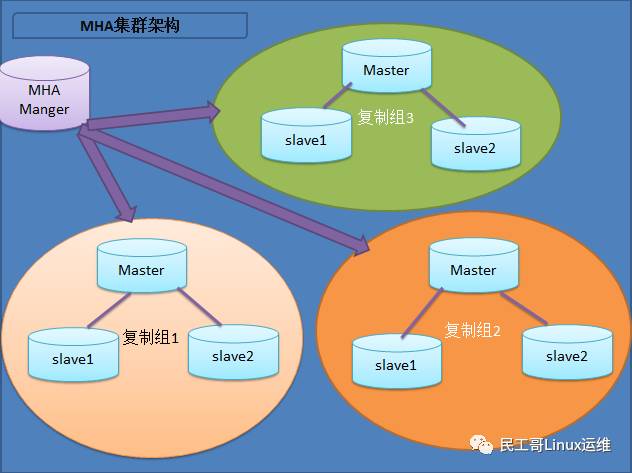
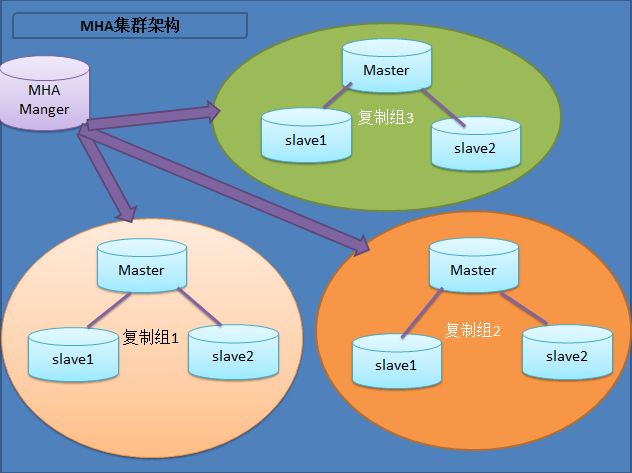
此架构特点:
1、安装布署简单,不影响现有架构
2、自动监控和故障转移
3、保障数据一致性
4、故障切换方式可使用手动或自动多向选择
5、适应范围大(适用任何存储引擎)
2.MySQL高可用带给我们对高可用架构设计的思考
为了保证数据的一致性,MySQL提出了复制的概念。
为了满足acid,MySQL提供了两种日志redo和undo日志,redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作。undo log不是redo log的逆向过程,其实它们都算是用来恢复的日志:redo log通常是物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。undo用来回滚行记录到某个版本。undo log一般是逻辑日志,根据每行记录进行记录。为了高可用的保证,有了多主或者主从切换。
数据库的高可用架构一般在系统的底层,这方面的技术要求比较高,整个高可用系统大致如下:
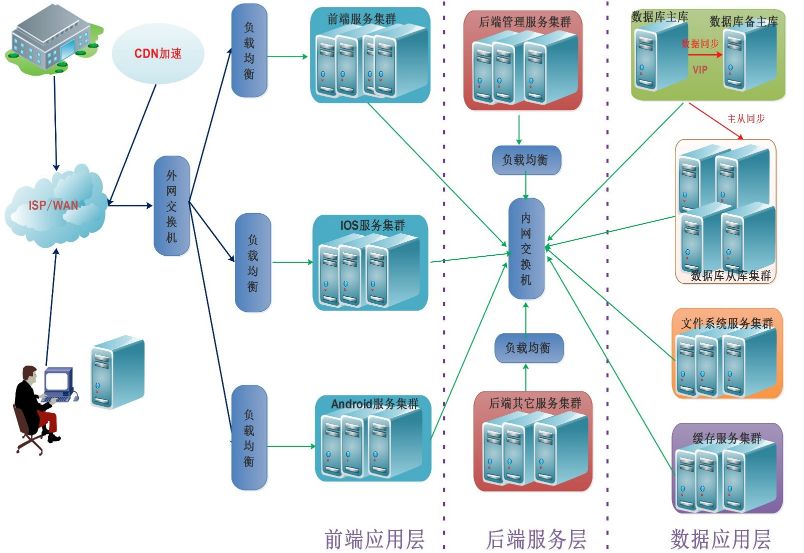
3.总结
我们都知道,单点是系统高可用的大敌,单点往往是系统高可用最大的风险和敌人,应该尽量在系统设计的过程中避免单点。
方法论上,高可用保证的原则是“集群化”,或者叫“冗余”:只有一个单点,挂了服务会受影响;如果有冗余备份,挂了还有其他backup能够顶上。冗余的最大难道是一致性即复制技术,MySQL提供了一个思路。
有了冗余之后,还不够,每次出现故障需要人工介入恢复势必会增加系统的不可服务实践。所以,又往往是通过“自动故障转移”来实现系统的高可用。灾备的恢复一般通过日志来做,日志的设计也是难点,MySQL提供了一个思路。
【1】http://uat.severalnines.com/blog/comparing-replication-solutions-oracle-and-mysql
【2】https://mysqlhighavailability.com/mysql-group-replication-hello-world/
【3】https://www.cnblogs.com/youkanyouxiao/p/8335159.html
【4】http://www.sohu.com/a/197271694_505827
【5】https://www.cnblogs.com/f-ck-need-u/archive/2018/05/08/9010872.html
【6】https://www.cnblogs.com/youkanyouxiao/p/9834791.html
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
架构文摘
ID:ArchDigest
互联网应用架构丨架构技术丨大型网站丨大数据

更多精彩文章,请点击下方:阅读原文










