公众号后台回复“学习”,获取作者独家秘制精品资料

多年好友心血力作,阿里资深技术专家十余年JVM生产实践经验
《从零开始带你成为JVM实战高手》
限时优惠:88元(正在进行ing)
专栏目录参见文末
扫下方海报进行试读

本文来自头条号:Wooola
1. 背景
生产es集群共12台服务器,5个索引数据总量为2亿,每个索引都有设置replicas=1-3不等。
正常情况下12台服务器down掉一两台甚至是依次挂掉过半服务器都不会有问题。
服务器配置为8-12核 48-96G内存,由于利用率不高,因此决定下线6台服务器,在实际操作过程中由于内部沟通问题导致集群数据丢失、索引损坏等一系列问题。
本文对本次灾难如何发生、怎样恢复做下回顾,以期警示大家在对生产环境做操作一定要细致谨慎、做好备份、避免此类问题发生。
给万一出现此类问题的朋友们提供下应对处理此类问题的一种思路。如有更好的解决方案,欢迎提出,共同探讨。
2. 灾难发生时间轴
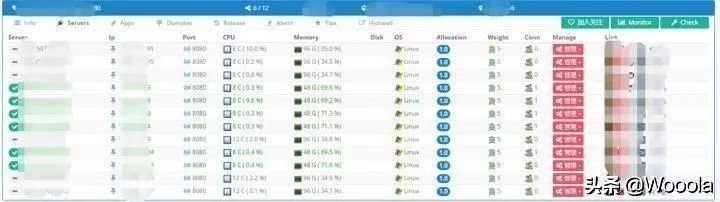
2017-6-09 周五下午——运营将6台服务器拉出集群❷,此时通过域名访问不到这6台服务器,但是实际上这6台服务器仍然处于es集群中,看起来一切正常。
2017-6-12 周一上午9点——经过周末几天的观察没发现问题,运营将6台服务器下线重装系统。
2017-6-12 周一上午10点——负责从db更新数据到es的job应用大量报错(见下图),开发收到相关报错信息报警。
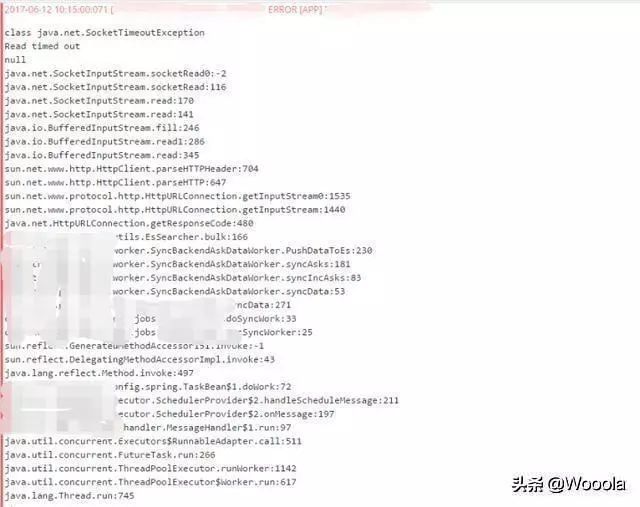
整个过程很简单,暴露的问题也很明显,如果沟通清楚的话在6台服务器下线重装前,开发将该6台服务器es实例依次停掉,就不会有问题,不过这一切都只是后知后觉了~
3.灾难分析
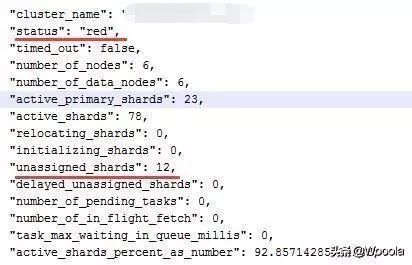
3.1. 检查集群健康状态❸:
3.2. 以索引a_index为例,查看shards情况:

可以看到集群共有12个未分配shards,a_index的0号shard主副共计2个全部丢失,因此3个分片只有2个可用,很确定的是已有数据丢失。
查看集群数据总量,2亿数据现仅存1.2亿~
3.3. 错误日志分析
class java.net.SocketTimeoutException
Read timed out
null
java.net.SocketInputStream.socketRead0:-2
java.net.SocketInputStream.socketRead:116
java.net.SocketInputStream.read:170
java.net.SocketInputStream.read:141
java.io.BufferedInputStream.fill:246
java.io.BufferedInputStream.read1:286
java.io.BufferedInputStream.read:345
sun.net.www.http.HttpClient.parseHTTPHeader:704
sun.net.www.http.HttpClient.parseHTTP:647
sun.net.www.protocol.http.HttpURLConnection.getInputStream0:1535
sun.net.www.protocol.http.HttpURLConnection.getInputStream:1440
java.net.HttpURLConnection.getResponseCode:480
com.xxx.xx.search.utils.EsSearcher.bulk:166
通过日志结合集群状态很容易得出结论——job通过bulk方式向es集群push数据,试图访问失联的shard(为了表述方便,实际上应该是该shard所在的node),导致timed out~
4. 灾难恢复
现在面临如下几个问题:
集群状态red,索引损坏部分shards失联导致job同步数据部分失败大量报错
因此,如何恢复集群以及索引状态成为解决这些问题的关键,怎样对客户端查询影响最小是难点。
4.1 尝试恢复方法一——重启es
寄希望于es会不会有很牛逼的恢复机制,原本倒是也没有抱太大希望,6台服务器依次重启之后果然是没啥用。
4.2 尝试恢复方法二——转移分片
把失联的shards分配到其它可用的nodes,梦想总是有的,结果却依旧失败,分片都没了谈何转移~
# curl -XPOST "http://ESnode:9200/_cluster/reroute' -d '{
"commands" : [ {
"move" : {
"index" : "xxx",
"shard" : 1,
"from_node" : "es_node_one",
"to_node" : "es_node_two"
}
}]
}'
4.3 尝试恢复方法三——索引删除重建
仅仅是个想法,不可行,2亿的数据,删掉重建要花费大量时间,各客户端会哭~领导会疯掉~
无论如何幸存的1.2亿数据要保住~
4.4 复制索引之后通过添加别名替换原索引——可行!
感谢es提供的reindex api,详见:Reindex API | Elasticsearch Reference [5.2] | Elastic
详细step如下,以a_index为例:
curl -XPUT ‘http://xxxx:9200/a_index_copy/‘ -d ‘{
“settings”:{
“index”:{
“number_of_shards”:3,
“number_of_replicas”:2
}
}
}POST _reindex
{
"source": {
"index": "a_index"
},
"dest": {
"index": "a_index_copy",
"op_type": "create"
}
}
curl -XDELETE 'http://xxxx:9200/a_index'
curl -XPOST 'http://xxxx:9200/_aliases' -d '
{
"actions": [
{"add": {"index": "a_index_copy", "alias": "a_index"}}
]
}'
5. Notes
❶. 集群有服务器down掉,丢失的shard会通过其replicas shard复制并重新分配到其它可用节点。强调“依次”,是因为如果不是大量服务器同时down掉的情况(严谨点来说应该这样表述:索引的某个shard的所有主副shard均损坏/丢失),es灾备机制完全可以应付。
❷. 软负载,客户端通过域名+软负载服务器访问集群中各服务器。
❸. es集群健康状态
green 最健康得状态,说明所有的分片包括备份都可用。
yellow 主分片(primary)可用,但是副本分片(replicas)不可用(或者是没有副本)
red 部分的分片可用,表明分片有一部分损坏,有的分片所有主副分片损坏/丢失的情况。此时执行查询部分数据仍然可以查到。
6. 名词释义
replicas——副本数量,e.g.如果索引Aindex设置shard=2 replicas=2则表示其分片总数=2*(2+1)=6,每条数据都会有3条相同记录。
END
如有收获,请划至底部,点击“在看”,谢谢!
《从零开始带你成为JVM实战高手》
专栏详细目录




欢迎长按下图关注公众号石杉的架构笔记,后台回复“学习”
获取作者独家秘制精品资料









