大家好,基于Python的数据科学实践课程又到来了,大家尽情学习吧。本期内容主要由智亿同学与政委联合推出。
上一部分推文我们学习了如何用Pandas完成绝大部分的数据处理工作。在此基础上,后续几次的推文将学习如何对于处理后的数据进行可视化。首先,应该明白人类受限于思维能力,所以理解数据的方法极其有限。一种方法是通过数字特征,而另一种方法是通过数据产生的机制(例如:商业数据的商业逻辑,物理世界产生数据的物理定律等)。把这两者完美的结合起来的方式就是探索性数据分析。这也是数据学科中最重要的一步。探索性数据分析其实是试图通过数字特征与数据可视化的方法结合数据产生机制解读数据与理解数据的过程。数据可视化是探索性数据分析的最关键的步骤,本部分介绍利用Python中的两个绘图模块,Matplotlib和Plotly进行探索性数据分析。
Matplotlib是Python绘图的基石,是几乎所有和绘图有关的模块都会作为核心的底层模块。其绘图风格接近Matlab,主要用于比较严谨的场合。在此基础上还有Seaborn、Bokeh等,风格更美观。Plotly是基于Json和JS的绘图模块,主要通过动态图的方式展现数据,可以认为是绘图方面最高级的模块。
数据可视化的重要性体现在三个方面:
1、直观展现数据特点,便于建模。
正所谓,一图胜过千言万语。在前期探索性分析阶段,面对茫茫数字,很难一眼看出数据的分布特点,极有可能忽视存在的建模特征;而对数据可视化展示后,发现数据分布特点的可能性大大增加。
2、将建模结果直观展现,便于调优。
建模的过程不是一蹴而就的,往往涉及"建模——调优——再建模"。这就需要将结果好坏直观展现到图片上,便于发现模型的不足之处。尤其是在机器学习、深度学习领域,往往涉及到大量的调参,每次参数变化程度都很小,光看数字其实很难判别出哪组参数是最佳的,将结果可视化后就能更加直观地感受到。
3、将工作成果可视化汇总,便于汇报。
假设,政委好不容易做完了模型,效果也不错,最终给熊大过目申请经费,汇报的时候是下面这个样子:
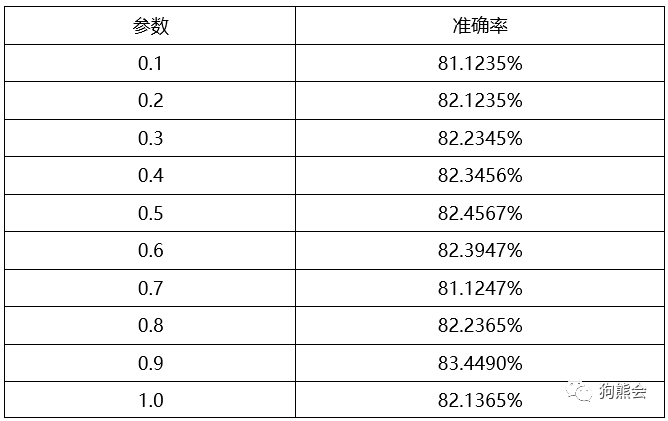
熊大看起来很糟心不说,而且一看前几个数字,.1235,.2345,.3456,.4567......"政委啊,前几个小数怎么惊人的一致啊,你过来下咱们聊聊...."。
第二回申请经费:
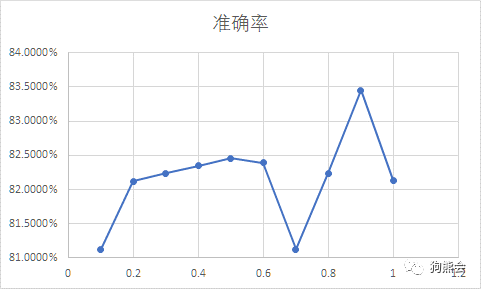
一张图一摆,熊大一看,“喔,原来参数为0.9的时候能最优啊,嗯,效果不错,批了!” 政委偷偷笑着,心想:“还是上回的数字,只是画了张图而已,嘿嘿。” 这时候水妈跳出来了,大喊一声”这是丑图的好案例“。
还是那句话,一图胜千言万语。
本章将学习:
● 如何使用Matplotlib构建画布
● 如何使用Matplotlib绘制六种主流图形
● 如何修改Matplotlib的全局配置
先读入上一章处理后的整合数据。
1import pandas as pd
2merge_data = pd.read_excel("https://github.com/xiangyuchang/xiangyuchang.github.io/blob/master/BearData/merge_shop_coupon_nm.xlsx?raw=true")
3print('数据的维度是:', merge_data.shape)
4
merge_data.head()
无论是Matlab、R、Python、还是SAS,亦或是现实中的画家画图,基本思想是一样的:在一张画布上堆叠各种元素。看上去一张2D的图片,如果把绘制时间也算一个维度的话,其实可以认为是3D(按照堆叠时间展开的2D图像)。所以,我们的第一步是构建绘图的画板。
表1 构建白板
例1 构建白板
1import matplotlib.pyplot as plt
2fig = plt.figure(figsize=(18,6))
3ax1 = fig.add_subplot(2,2,1)
4ax2 = fig.add_subplot(2,2,2)
5ax3 = fig.add_subplot(2,2,3)
6ax4 = fig.add_subplot(2,2,4)
7plt.show()
8plt.close()
运行结果如图1所示。
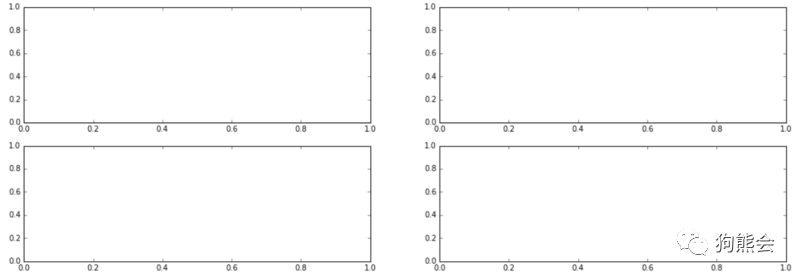
图1 构建白板
说明几点:
● 先通过plt.figure()函数创建一张完整的画布,作为最底层,之后的所有操作都在这张画布上完成。
● 再通过fig.add_subplot()函数创建子图,相当于在已创建的画布上再叠加子图,子画布间相互独立,这样就可以达到一次性完成多幅图片的效果。堆叠逻辑如图2所示。
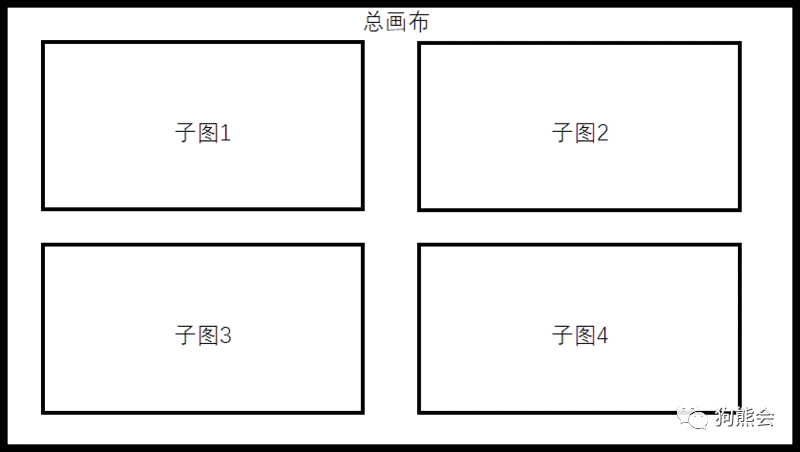
图2 堆叠逻辑
● 为便于展示,在这个例子中,我们依次创建了四个子图,实际中可以通过循环最后一个参数达到效果。
1fig = plt.figure(figsize=(18,6)) # 创建一个18*6大小的图实例(相当于一个画布)
2
3for i in range(1, 5):
4 ax = fig.add_subplot(2,2,i)
5
6plt.show()
7plt.close()
最终效果是与图2是一致的,这样能更方便的批量生产图片。
● 每次plt.show()结束后,由于jupyter本身的特性,所有数据只要不覆盖就仍然保存在内存中,因此可能导致反复调用时出现上一次运行的结果。所以,切记加上plt.close()关闭这个画布。
此小节主要涉及Matplotlib画布和子图的相关个性化设置。由于全局配置的不同参数会相互覆盖,因此本小节不提供代码文件,读者可以跟随本书一起实现案例代码。
● 指定中文字体
表2 显示中文

例2 无法显示中文
1fig = plt.figure()
2ax1 = fig.add_subplot(111)
3ax1.set_title('你好')
4plt.show()
由于Matplotlib默认只显示英文字体,遇到中文字体会显示长方形的框框。
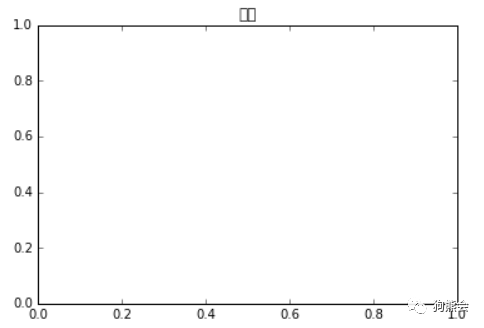
图3 无法显示中文
例3 显示中文
1
2import matplotlib.font_manager as mfm
3
4font_path = r"../data/msyh.ttc"
5prop = mfm.FontProperties(fname = font_path)
6
7fig = plt.figure()
8ax1 = fig.add_subplot(111)
9ax1.set_title('你好', fontproperties=prop, fontsize=20)
10plt.show()
运行结果如图4。
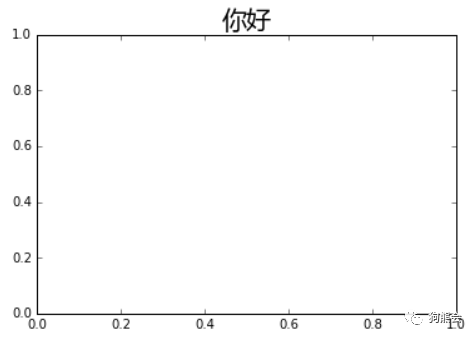
图4 显示中文
注意,mfm.FontProperties()中指定的是字体文件的路径,而不是字体名称,建议将字体文件复制到相应的项目文件夹下。
● 指定全局画图主题
表3 修改画图主题

例4 修改画图主题
1
2plt.style.use('ggplot')
3
4plt.style.available
运行结果如图5所示。
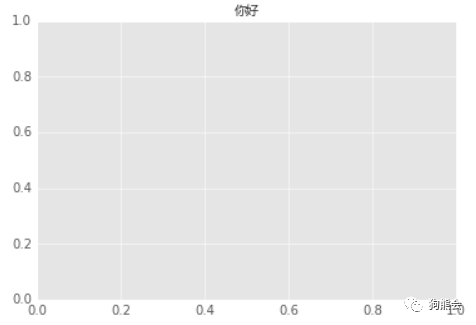
图5 修改画图主题
● 其他配置
ax代表子图的变量。
表4 其他配置
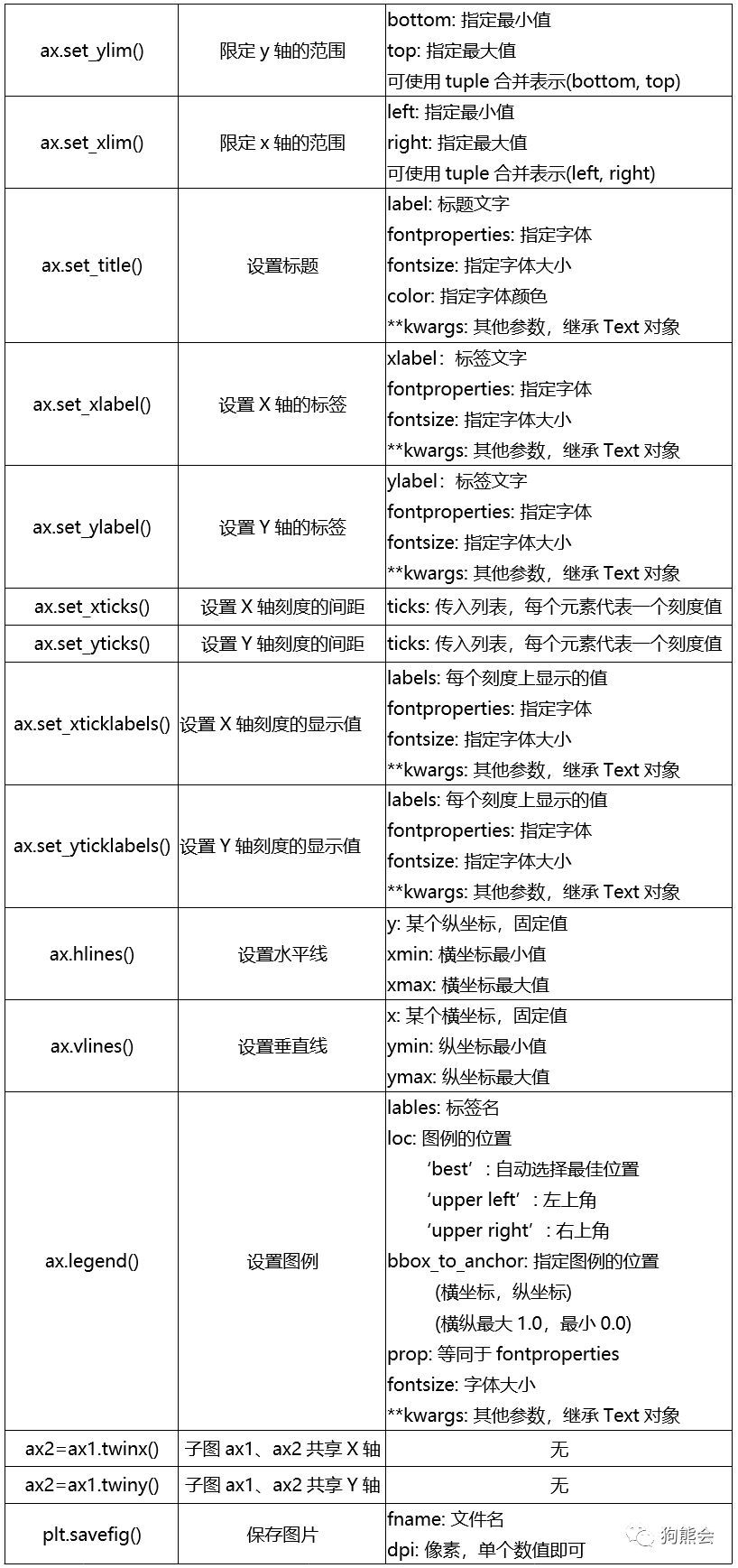
由于Matplotlib属于非常底层的绘图工具,几乎所有元素都可以重新设置,因此接口和函数众多,建议归类记忆。比如涉及到字体的接口中,继承的是Text类,设置字体样式的变量基本就是fontproperties, 涉及到字体大小就是fontsize。正因为它非常底层,熟练掌握后,换成其他绘图包基本可以一眼就会。
好了,今天就讲到这里。
作业:打开Jupyter构建自己的画布,导入自己的字体,并给子图中的横轴,纵轴加入名称。










