后台回复【入门资料】
送你十本Python电子书

文 | 豌豆花下猫
公众号 | Python 猫
在 Python 的项目中,如何管理所用的全部依赖库呢?最主流的做法是维护一份“requirements.txt”,记录下依赖库的名字及其版本号。
那么,如何来生成这份文件呢?在上篇文章《由浅入深:Python 中如何实现自动导入缺失的库?》中,我提到了一种常规的方法:
pip freeze > requirements.txt
这种方法用起来方便,但有几点不足:
可用于项目依赖管理的工具有很多,本文主要围绕与 requirements.txt 文件相关的、比较相似却又各具特色的 4 个三方库,简要介绍它们的使用方法,罗列一些显著的功能点。至于哪个是最好的管理方案呢?卖个关子,请往下看……
pipreqs
这是个很受欢迎的用于管理项目中依赖库的工具,可以用“pip install pipreqs”命令来安装。它的主要特点有:
基本的命令选项如下:
Usage:
pipreqs [options]
Options
:
--use-local Use ONLY local package info instead of querying PyPI
--pypi-server Use custom PyPi server
--proxy Use Proxy, parameter will be passed to requests library. You can also just set the
environments parameter in your terminal:
$ export HTTP_PROXY="http://10.10.1.10:3128"
$
export HTTPS_PROXY="https://10.10.1.10:1080"
--debug Print debug information
--ignore ... Ignore extra directories
--encoding Use encoding parameter for file open
--savepath Save the list of requirements in the given file
--print Output the list of requirements in the standard output
--force Overwrite existing requirements.txt
--diff Compare modules in requirements.txt to project imports.
--clean Clean up requirements.txt by removing modules that are not imported in project.
其中需注意,很可能遇到编码错误:UnicodeDecodeError:'gbk'codec can't decode byte 0xae in。需要指定编码格式“--encoding=utf8”。
在已生成依赖文件“requirements.txt”的情况下,它可以强行覆盖、比对差异以及清除不再使用的依赖项。
pigar
pigar 同样可以根据项目路径来生成依赖文件,而且会列出依赖库在文件中哪些位置使用到了。这个功能充分利用了 requirements.txt 文件中的注释,可以提供很丰富的信息。
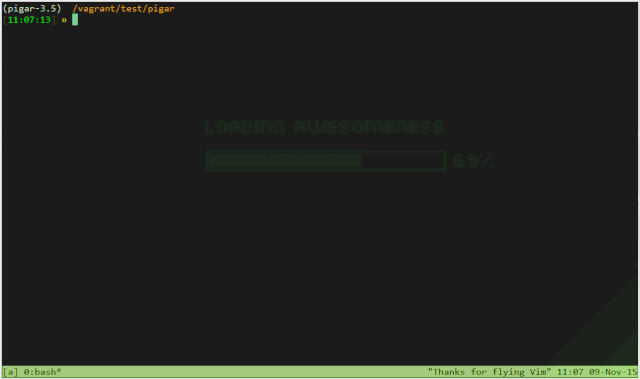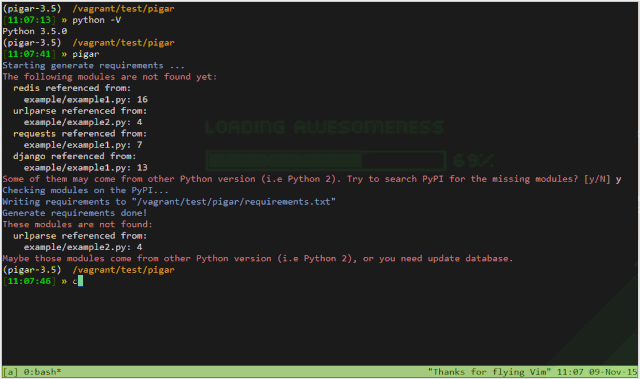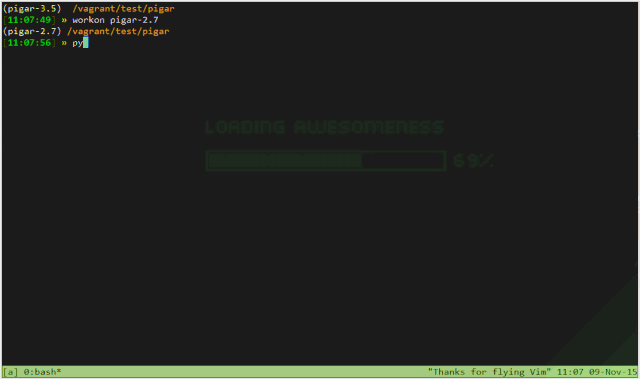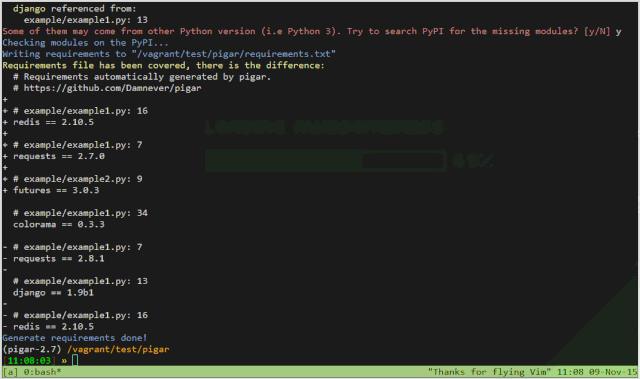
pigar 对于查询真实的导入源很有帮助,例如 bs4 模块来自 beautifulsoup4 库,
MySQLdb 则来自于 MySQL_Python 库。可以通过“-s”参数,查找真实的依赖库。
$ pigar -s bs4 MySQLdb
它使用解析 AST 的方式,而非正则表达式的方式,可以很方便地从 exec/eval 的参数、文档字符串的文档测试中提取出依赖库。
另外,它对于不同 Python 版本的差异可以很好地支持。例如, concurrent.futures 是 Python 3.2+ 的标准库,而在之前早期版本中,需要安装三方库 futures ,才能使用它。pigar 做到了有效地识别区分。(PS:pipreqs 也支持这个识别,详见这个合入:https://github.com/bndr/pipreqs/pull/80)
pip-tools
pip-tools 包含一组管理项目依赖的工具:pip-compile 与 pip-sync,可以使用命令“pip install pip-tools”统一安装。它最大的优势是可以精准地控制项目的依赖库。
两个工具的用途及关系图如下:
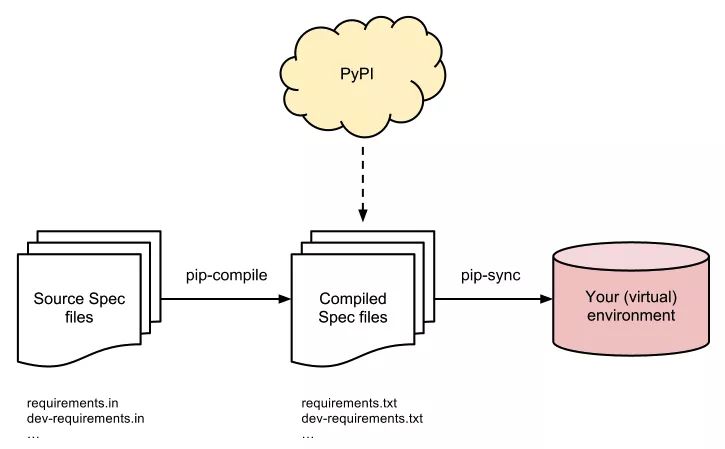
pip-compile 命令主要用于生成依赖文件和升级依赖库,另外它可以支持 pip 的“Hash-Checking Mode ”,并支持在一个依赖文件中嵌套其它的依赖文件(例如,在 requirements.in 文件内,可以用“-c requirements.txt”方式,引入一个依赖文件)。
它可以根据 setup.py 文件来生成 requirements.txt,假如一个 Flask 项目的 setup.py 文件中写了“install_requires=['Flask']”,那么可以用命令来生成它的所有依赖:
$ pip-compile
#
# This file is autogenerated by pip-compile
# To update, run:
#
# pip-compile --output-file requirements.txt setup.py
#
click==6.7 # via flask
flask==0.12.2
itsdangerous==0.24 # via flask
jinja2==2.9.6 # via flask
markupsafe==1.0 # via jinja2
werkzeug==0.12.2 # via flask
在不使用 setup.py 文件的情况下,可以创建“requirements.in”,在里面写入“Flask”,再执行“pip-compile requirements.in”,可以达到跟前面一样的效果。
pip-sync 命令可以根据 requirements.txt 文件,来对虚拟环境中进行安装、升级或卸载依赖库(注意:除了 setuptools、pip 和 pip-tools 之外)。这样可以有针对性且按需精简地管理虚拟环境中的依赖库。
另外,该命令可以将多个“*.txt”依赖文件归并成一个:
$ pip-sync dev-requirements.txt requirements.txt
pipdeptree
它的主要用途是展示 Python 项目的依赖树,通过有层次的缩进格式,显示它们的依赖关系,不像前面那些工具只会生成扁平的并列关系。

除此之外,它还可以:
它也有缺点,比如无法穿透虚拟环境。如果要在虚拟环境中工作,必须在该虚拟环境中安装 pipdeptree。因为跨虚拟环境会出现重复或冲突等情况,因此需要限定虚拟环境。但是每个虚拟环境都安装一个 pipdeptree,还是挺让人难受的。
好啦,4 种库介绍完毕,它们的核心功能都是分析依赖库,生成 requirements.txt 文件,同时,它们又具有一些差异,补齐了传统的 pip 的某些不足。
本文不对它们作全面的测评,只是选取了一些主要特性进行介绍,好在它们安装方便(pip install xxx),使用也简单,感兴趣的同学不妨一试。
更多丰富的细节,请查阅官方文档:
https://github.com/bndr/pipreqs
https://github.com/damnever/pigar
https://github.com/jazzband/pip-tools
https://github.com/naiquevin/pipdeptree
回复下方「关键词」,获取优质资源
回复关键词「 pybook03」,立即获取主页君与小伙伴一起翻译的《Think Python 2e》电子版
回复关键词「入门资料」,立即获取主页君整理的 10 本 Python 入门书的电子版
回复关键词「m」,立即获取Python精选优质文章合集
回复关键词「book 数字」,将数字替换成 0 及以上数字,有惊喜好礼哦~
推荐阅读
题图:pexels,CC0 授权。










