
扫描下方海报 试读


本文来源:朱小厮的博客
第一眼看到这个问题,皮皮也是很迷惑的,谁没事会问这种问题。然而,事实上这居然是一道真实的面试题。
本来皮皮以为“皮友”只是皮着调侃一下的,既然是道面试题,那就要稍微地分析分析、说道说道了。
首先,从时间上来说,这是不同时期的两个典型产品,MySQL要早于Kafka。
首先我们来说一说MySQL的历史。MySQL可以追溯到1979年,一个名为Monty Widenius的程序员在为TcX的小公司打工,并且用BASIC设计了一个报表工具,使其可以在4MHz主频和16KB内存的计算机上运行。
当时,这只是一个很底层的且仅面向报表的存储引擎,名叫Unireg。1990年,TcX公司的客户中开始有人要求为他的API提供SQL支持。Monty直接借助于mSQL的代码,将它集成到自己的存储引擎中。
令人失望的是,效果并不太令人满意,决心自己重写一个SQL支持。
1996年,MySQL 1.0发布,它只面向一小拨人,相当于内部发布。到了1996年10月,MySQL 3.11.1发布(MySQL没有2.x版本),最开始只提供Solaris下的二进制版本。
一个月后,Linux版本出现了。在接下来的两年里,MySQL被依次移植到各个平台。
2000年,MySQL不仅公布自己的源代码,并采用GPL(GNU General Public License)许可协议,正式进入开源世界。
同年4月,MySQL对旧的存储引擎ISAM进行了整理,将其命名为MyISAM。
2003年12月,MySQL 5.0版本发布,提供了视图、存储过程等功能。
2010年12月,MySQL 5.5发布,其主要新特性包括半同步的复制及对SIGNAL/RESIGNAL的异常处理功能的支持,最重要的是InnoDB存储引擎终于变为当前MySQL的默认存储引擎。
好了,再来简单聊聊Kafka的历史。Apache Kafka最初由LinkedIn开发,并在2011年初开源。
在2012年10月23日由Apache Incubator孵化出站,成为了Apache软件基金会的项目。
2014年11月, Jun Rao、Jay Kreps、 Neha Narkhede等几个曾在LinkedIn为Kafka工作的工程师,创建了名为Confluent的新公司,并着眼于Kafka。
根据2014年Quora(美版知乎)的帖子,Jay Kreps将Kafka以作家Franz Kafka(奥匈帝国作家,代表作:《变形记》)命名。
Kreps选择将该系统以一个作家命名是因为,它是“a system optimized for writing”(一个用于优化写作的系统),而且他很喜欢Kafka的作品。
从时间上来说,先者不能预测未来的事情,也就是说MySQL不能预测未来某个产品的架构以及其能够从此未来架构上吸取点什么经验。
但是前面的这些说辞只能用来做加分项,要彻底说服面试官显然还是不行的。
MySQL经历了这么多年的变迁和改进,底层的存储引擎也有好多个,比如MyISAM、InnoDB,如果觉得某个东西适合自己,是可以在这个变迁的过程中引进过来。
技术面试,还是要从技术的角度去剖析。回答这个问题,除了要考虑时间这个加分项之外,还要说到以下3个技术点:
MySQL中的索引机制;
Kafka中的索引机制;
MySQL与Kafka索引机制的对比。
何为索引?很多人都知道“索引是一个排序的列表,在这个列表中存储着索引的值和包含这个值的数据所在行的物理地址
在数据十分庞大的时候,索引可以大大加快查询的速度,这是因为使用索引后可以不用扫描全表来定位某行的数据,而是先通过索引表找到该行数据对应的物理地址然后访问相应的数据。
索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字。但过多的使用索引将会造成滥用。
因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
索引是在MYSQL的存储引擎层中实现的,而不是在服务层实现的。所以每种存储引擎的索引都不一定完全相同,也不是所有的存储引擎都支持所有的索引类型。
MYSQL目前主要提供了以下4种索引 :
B/B+树索引:最常见的索引类型,大部分引擎都支持B树索引。
HASH 索引:只有Memory引擎支持,使用场景简单。
R-Tree 索引(空间数据索引):空间索引是MyISAM的一种特殊索引类型,主要用于地理空间数据类型。
Full-text (全文索引):全文索引也是MyISAM的一种特殊索引类型,主要用于全文索引,InnoDB从MYSQL5.6版本提供对全文索引的支持。
其它索引类别:还有很多第三方的存储引擎使用不同类型的数据结构来存储索引。
例如TokuDB使用分形树索引(fractal tree index),这是一类较新开发的数据结构,既有B-Tree的很多优点,也避免了B-Tree的一些缺点。
多数情况下,针对InnoDB的讨论也都适用于TokuDB。ScaleDB使用Patricia tries,其他一些存储引擎技术如InfiniDB和Infobright则使用了一些特殊的数据结构来优化某些特殊的查询。
我们知道MySQL从5.5版本开始就将InnoDB作为了默认的存储引擎,在《高性能MySQL》一书对于如何选择存储引擎就发表过这样的观点:
除非需要用到某些InnoDB不具备的特性,并且没有其它办法可以替代,否则都应该优先选择InnoDB引擎。
虽然从学术陈词上来说并不太严谨,但是我们可以简单的认为:在绝大多数情况下,现在我们所说的MySQL所使用的引擎为InnoDB,而索引是在存储引擎中实现的。
“为什么MySQL的索引不采用kafka的索引机制?”这个命题也可以简单的修改为“为什么InnoDB中不采用Kafka的索引机制?”
MySQL中的存储引擎有很多,除了MyISAM、InnoDB之外,还有Archive、Blackhole、CSV、Federated、Memory、Merge、NDB、Groonga、OQGraph、Q4M、SphinxSE、Spider、VPForMySQL….等等
每个存储引擎多针对的优化场景也不同,而且这里我们无法针对每个存储引擎来做分析,所以这里我们针对最最通用的InnoDB来做进一步的分析。
为了弄清楚“为什么mysql的索引不采用kafka的索引机制?”或者“为什么InnoDB中不采用Kafka的索引机制?”
那么我们还是先来复习一下Kafka中的索引机制。
在kafka中,每个日志分段文件都对应了两个索引文件——偏移量索引文件和时间戳索引文件(还有其它的诸如事务日志索引文件就不细表了),主要用来提高查找消息的效率。
偏移量索引文件用来建立消息偏移量(offset)到物理地址之间的映射关系,方便快速定位消息所在的物理文件位置;时间戳索引文件则根据指定的时间戳(timestamp)来查找对应的偏移量信息。
Kafka 中的索引文件以稀疏索引(sparse index)的方式构造消息的索引,它并不保证每个消息在索引文件中都有对应的索引项。
每当写入一定量 (由 broker 端参数 log.index.interval.bytes 指定,默认值为 4096,即 4KB) 的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索引项,增大或减小 log.index.interval.bytes 的值,对应地可以缩小或增加索引项的密度。
稀疏索引通过 MappedByteBuffer 将索引文件映射到内存中,以加快索引的查询速度。
偏移量索引文件中的偏移量是单调递增的,查询指定偏移量时,使用二分查找法来快速定位偏移量的位置,如果指定的偏移量不在索引文件中,则会返回小于指定偏移量的最大偏移量。
时间戳索引文件中的时间戳也保持严格的单调递增,查询指定时间戳时,也根据二分查找法来查找不大于该时间戳的最大偏移量,至于要找到对应的物理文件位置还需要根据偏移量索引文件来进行再次定位。
稀疏索引的方式是在磁盘空间、内存空间、查找时间等多方面之间的一个折中。
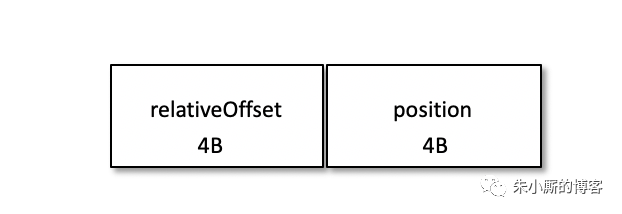
以偏移量索引文件来做具体分析。偏移量索引项的格式如下图所示。
每个索引项占用 8 个字节,分为两个部分:
(1) relativeOffset: 相对偏移量,表示消息相对于 baseOffset 的偏移量,占用 4 个字节,当前索引文件的文件名即为 baseOffset 的值。
(2) position: 物理地址,也就是消息在日志分段文件中对应的物理位置,占用 4 个字节。
消息的偏移量(offset)占用 8 个字节,也可以称为绝对偏移量。
索引项中没有直接使用绝对偏移量而改为只占用 4 个字节的相对偏移量(relativeOffset = offset - baseOffset),这样可以减小索引文件占用的空间。
举个例子,一个日志分段的 baseOffset 为 32,那么其文件名就是 00000000000000000032.log,offset 为 35 的消息在索引文件中的 relativeOffset 的值为 35-32=3。
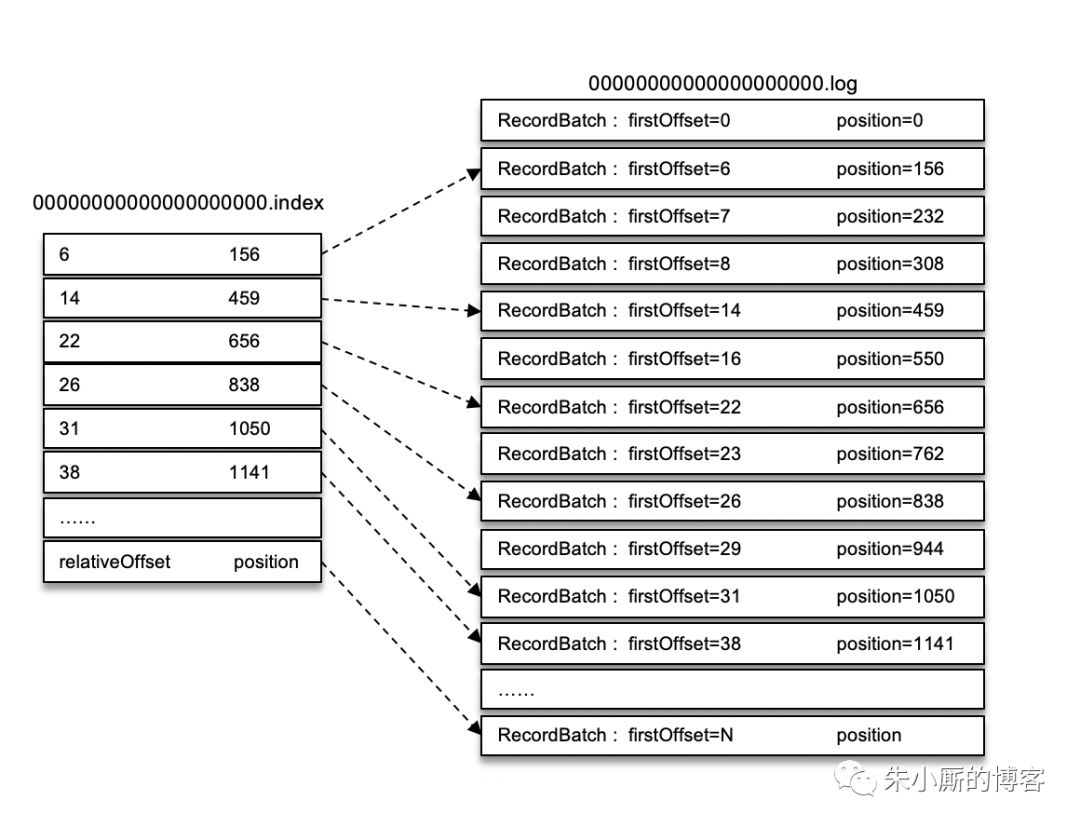
如果我们要查找偏移量为 23 的消息,那么应该怎么做呢?首先通过二分法在偏移量索引文件中找到不大于 23 的最大索引项,即[22, 656],然后从日志分段文件中的物理位置 656 开始顺序查找偏移量为 23 的消息。

以上是最简单的一种情况。参考上图,如果要查找偏移量为 268 的消息,那么应该怎么办呢?
首先肯定是定位到baseOffset为251的日志分段,然后计算相对偏移量relativeOffset = 268 - 251 = 17,之后再在对应的索引文件中找到不大于 17 的索引项,最后根据索引项中的 position 定位到具体的日志分段文件位置开始查找目标消息。
那么又是如何查找 baseOffset 为 251 的日志分段的呢?
这里并不是顺序查找,而是用了跳跃表的结构。
Kafka 的每个日志对象中使用了 ConcurrentSkipListMap 来保存各个日志分段,每个日志分段的 baseOffset 作为 key,这样可以根据指定偏移量来快速定位到消息所在的日志分段。
在Kafka中要定位一条消息,那么首先根据 offset 从 ConcurrentSkipListMap 中来查找到到对应(baseOffset)日志分段的索引文件,然后读取偏移量索引索引文件,之后使用二分法在偏移量索引文件中找到不大于 offset - baseOffset z的最大索引项,接着再读取日志分段文件并且从日志分段文件中顺序查找relativeOffset对应的消息。
Kafka中通过offset查询消息内容的整个流程我们可以简化成下图:

我们再来复习MySQL(InnoDB)中的索引机制。
可以说数据库必须有索引,没有索引则检索过程变成了顺序查找,O(n)的时间复杂度几乎是不能忍受的。
我们非常容易想象出一个只有单关键字组成的表如何使用B+树进行索引,只要将关键字存储到树的节点即可。
当数据库一条记录里包含多个字段时,一棵B+树就只能存储主键,如果检索的是非主键字段,则主键索引失去作用,又变成顺序查找了。这时应该在第二个要检索的列上建立第二套索引。 这个索引由独立的B+树来组织。
有两种常见的方法可以解决多个B+树访问同一套表数据的问题,一种叫做聚簇索引(clustered index ),一种叫做非聚簇索引(secondary index)。
这两个名字虽然都叫做索引,但这并不是一种单独的索引类型,而是一种数据存储方式。
对于聚簇索引存储来说,行数据和主键B+树存储在一起,辅助键B+树只存储辅助键和主键,主键和非主键B+树几乎是两种类型的树。
对于非聚簇索引存储来说,主键B+树在叶子节点存储指向真正数据行的指针,而非主键。

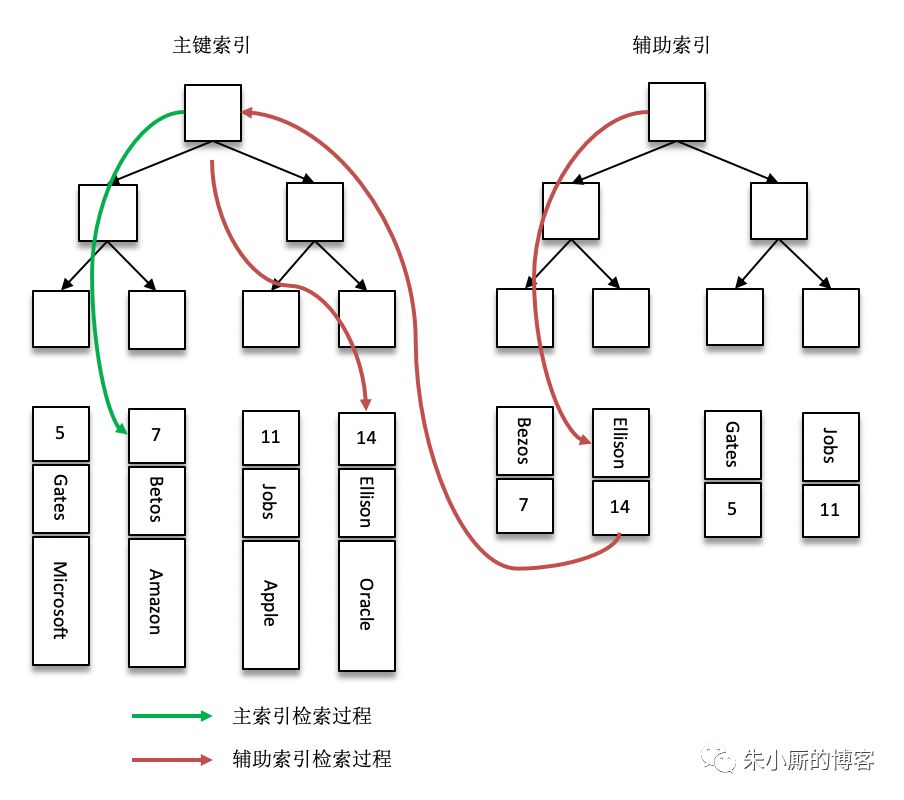
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。
若对Name列进行条件搜索,则需要两个步骤:
Kafka中消息的offset可以类比成InnoDB中的主键,前者是通过offset检索出整条Record的数据,后者是通过主键检索出整条Record的数据。
InnoDB中通过主键查询数据内容的整个流程建议简化成下图(下半部分)。

从上图中我们也可以明显的看到就检索而言,InnoDB中的索引机制比Kafka中的索引机制要简略一点,检索效率应该也是InnoDB获胜
我们将上图中分为左中右三部分来分析:
最左部分:ConcurrentSkipListMap和B+树索引的查询时间复杂度都为logN,B+树中的非叶子节点一般也可以都驻留在内存中
我们可以简单的将Kafka中查找baseOffset对应的日志分段和InnoDB中查找对应叶子节点的消耗看做差不多相等的,粗略算作平手。
最右部分:Kafka中后面通过索引读取分段日志文件的内容是一个页的大小(可以思考下前面提及的“每当写入一定量(由 broker 端参数 log.index.interval.bytes 指定,默认值为 4096,即 4KB)的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索引项”),B+树中一个叶子节点也是一个页的大小。最后都是从这块内容中查找所要的内容
Kafka中是顺序查找,InnoDB中还会有更有的方式去查找(比如以主键为搜索条件,可以使用Page Directory通过二分法快速定位)。这里比较而言,应该是InnoDB小胜。
Kafka中通过时间戳索引文件去检索消息的方式可以类比于InnoDB中的辅助索引的检索方式:
前者是通过timestamp去找offset,后者是通过索引去找主键,后面两者的过程就和上面的陈述相同。
我们再来思考一个问题:
既然InnoDB的索引这么厉害,那么作为后起之秀的Kafka不采用呢?
我们还要考虑一个问题:InnoDB中维护索引的代价比Kafka中的要高。
Kafka中当有新的索引文件建立的时候ConcurrentSkipListMap才会更新,而不是每次有数据写入时就会更新,这块的维护量基本可以忽略
B+树中数据有插入、更新、删除的时候都需要更新索引,还会引来“页分裂”等相对耗时的操作。Kafka中的索引文件也是顺序追加文件的操作,和B+树比起来工作量要小很多。
说到底还是应用场景不同所决定的。MySQL中需要频繁地执行CRUD的操作,CRUD是MySQL的主要工作内容,而为了支撑这个操作需要使用维护量大很多的B+树去支撑。
Kafka中的消息一般都是顺序写入磁盘,再到从磁盘顺序读出(不深入探讨page cache等),他的主要工作内容就是:写入+读取,很少有检索查询的操作
换句话说,检索查询只是Kafka的一个辅助功能,不需要为了这个功能而去花费特别太的代价去维护一个高level的索引。
前面也说过,Kafka中的这种方式是在磁盘空间、内存空间、查找时间等多方面之间的一个折中。
END
如有收获,请划至底部,点击“在看”,谢谢!
欢迎长按下图关注公众号石杉的架构笔记








