
日志分析在web系统中故障排查、性能分析方面有着非常重要的作用。目前,开源的ELK系统是成熟且功能强大的选择。但是部署及学习成本亦然不低,这里我实现了一个方法上相对简单(但准确度和效率是有保证的)的实现。另外该脚本的侧重点不是通常的PV,UV等展示,而是短期内(如三天历史or一周历史)提供细粒度的异常和性能分析。
先说一下我想实现这个功能的驱动力(痛点)吧:
我们有不少站点,前边有CDN,原站前面是F5,走到源站的访问总量日均PV约5000w。下面是我们经常面临一些问题:
CDN回源异常,可能导致我们源站带宽和负载都面临较大的压力。这时需要能快速的定位到是多了哪些回源IP(即CDN节点)或是某个IP的回源量异常,又或是哪些url的回源量异常
在排除了CDN回源问题之后,根据zabbix监控对一些异常的流量或者负载波动按异常时段对比正常时段进行分析,定位到具体的某(几)类url。反馈给开发进行review以及优化
有时zabbix会监控到应用服务器和DB或者缓存服务器之间的流量异常,这种问题一般定位起来是比较麻烦的,甚至波动仅仅是在一两分钟内,这就需要对日志有一个非常精细的分析粒度
我们希望能所有的应用服务器能过在本机分析日志(分布式的思想),然后将分析结果汇总到一起(MySQL)以便查看;并且还希望能尽可能的实时(将定时任务间隔设置低一些),以便发现问题后能尽快的通过此平台进行分析
通用和性能:对于不同的日志格式只需对脚本稍加改动即可分析;因为将日志分析放在应用服务器本机,所以脚本的性能和效率也要有保证,不能影响业务
再说下原理:
比较简单,就是利用python的re模块通过正则表达式对日志进行分析处理,取得uri、args、时间当前、状态码、响应大小、响应时间、用户IP、CDN ip、server name 等信息存储进数据库。
当然前提规范也是必须的:
各台server的日志文件按统一路径存放
日志格式保持一致
每天的0点日志切割
我的nginx日志格式如下:

日志分析原理:
通过Python的re模块,按照应用服务器的日志格式编写正则,例如按照我的日志格式,写出的正则如下(编写正则时,先不要换行,确保空格或引号等与日志格式一致,最后考虑美观可以折行)

用以上正则来整体匹配一行日志记录,然后各个部分可以通过log_pattern_obj.search(log).group('remote_addr')、log_pattern_obj.search(log).group('body_bytes_sent')
等形式来访问
对于其他格式的nginx日志或者Apache日志,按照如上原则,并对数据库结构做相应调整,都可以轻松的使用该脚本分析处理。
原理虽简单但实现起来却发现有好多坑,主要是按照上述的日志格式(靠空格或双引号来分割各段)主要问题是面对各种不规范的记录时(原因不一而足,而且也是样式繁多),如何正确的分割及处理日志的各字段,这也是我用re模块而不是简单的split()函数的原因。代码里对一些“可以容忍”的异常记录通过一些判断逻辑予以处理;对于“无法容忍”的异常记录则返回空字符串并将日志记录于文件。
其实对于上述的这些不规范的请求,最好的办法是在nginx中定义日志格式时,用一个特殊字符作为分隔符,例如“|”。这样都不用Python的re模块,直接字符串分割就能正确的获取到各段。
接下来看看使用效果:
先看一行数据库里的记录
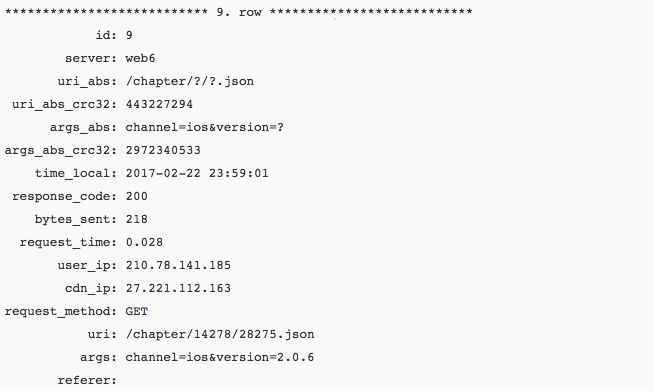
其中uri_abs和args_abs是对uri和args进行抽象化(抽象出一个模式出来)处理之后的结果。对uri中个段和args中的value部分除了完全由[a-zA-Z-_]+组成的部分之外的部分都用“?”做替换。uri_abs_crc32和args_abs_crc32两列是对抽象化结果进行crc32计算,这两列单纯只是为了在MySQL中对uri或args进行分类统计汇总时得到更好的性能。
现在还没有完成统一分析的入口脚本,所以还是以sql语句的形式来查询(对用户的sql功底有要求,不友好待改善)
select count(*) from www where time_local>='2016-12-09 00:00:00' and time_local<='2016-12-09 23:59:59'
mysql> select count(*) from www where uri_abs_crc32=2043925204 and time_local > '2016-11-23 10:00:00' and time_local
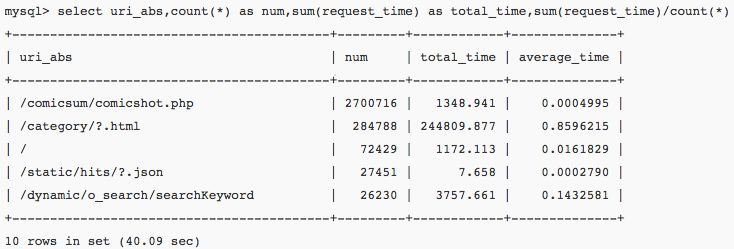
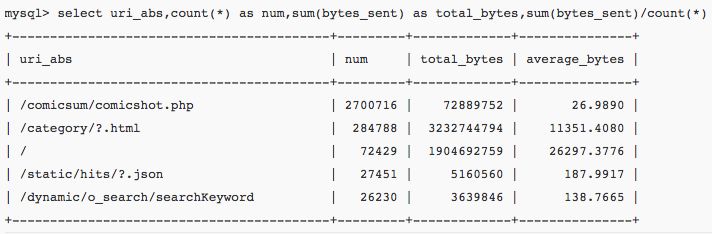
以上只列举了几个例子,基本上除了UA部分(代码中已有捕捉,但是笔者用不到),其他的信息都以包含到表中。因此几乎可以对网站流量,负载,响应时间等方面的任何疑问给出数据上的支持。
Python外部包依赖:pymysql
MySQL(笔者5.6版本)将innodb_file_format设置为Barracuda(这个设置并不对其他库表产生影响,即使生产数据库设置也无妨),以便在建表语句中可以通过ROW_FORMAT=COMPRESSED将innodb表这只为压缩模式,笔者实验开启压缩模式后,数据文件大小将近减小50%。
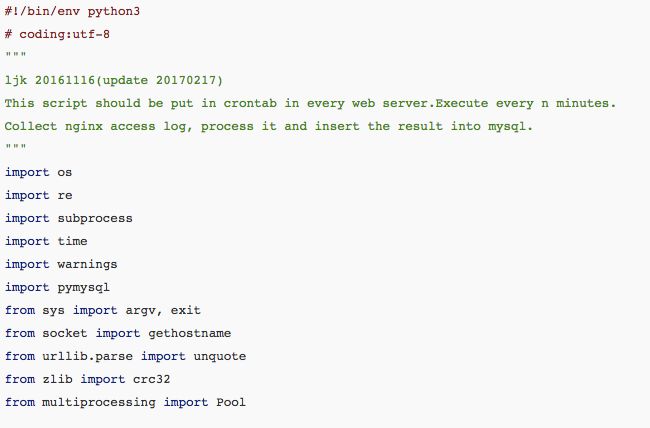
接下来请看代码:












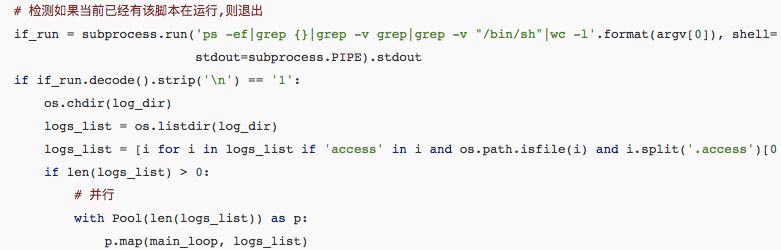
最后按照我们期望的间隔设置计划任务即可:*/30 * * * * export LANG=zh_CN.UTF-8;python3 /root/log_analyse_parall.py &> /tmp/log_analyse.py3
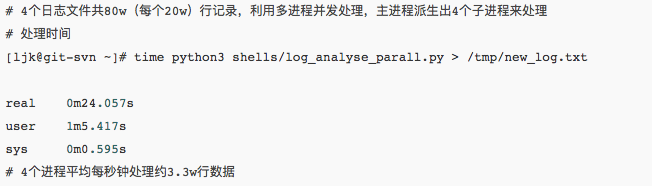
关于这样一个对不确定格式的大量文本进行分析的脚本来说,通用性和执行效率两个因素非常重要。通用性上文中已大致说明了原理;性能方面,经笔者在一台4核虚拟机上进行测试结果如下:
作者:kaifly
链接:http://blog.csdn.net/kai404/article/details/53443693
————近期Python开班————
《马哥教育Python全能开发实战班》由马哥教育导师联合BAT、豆瓣等一线互联网Python开发达人,根据目前企业需求的Python开发人才进行了深度定制,加入了大量一线互联网公司:大众点评、饿了么、腾讯等生产环境真是项目,课程由浅入深,从Python基础到Python高级,让你融汇贯通Python基础理论,手把手教学让你具备Python自动化开发需要的前端界面开发、Web框架、大监控系统、CMDB系统、认证堡垒机、自动化流程平台六大实战能力,让你从0开始蜕变成Hold住年薪20万的Python自动化开发人才。
10期面授班:2018年03月05号(北京)
09期网络班:腾讯课堂随到随学(网络)

 扫描二维码领取学习资料
扫描二维码领取学习资料












