大家好,基于Python的数据科学实践课程又到来了,大家尽情学习吧。本期内容主要由春艳与政委联合推出。
在我们实际的建模过程中,除了数值变量之外,经常会遇到需要处理分类变量的情况。例如火锅团购数据中,就有这样的分类变量存在(例如城市)。那在建模时需要如何处理这类变量呢?
其实在Pandas库中针对分类变量就有一个处理函数pandas.get_dummies可以使用。这个函数可以帮助我们为数据集中的非数值列创建虚变量,这样就可以将原来的分类变量用虚变量代替去拟合统计模型。
例1 利用get_dummies函数将分类变量转化为虚变量
dummies = pd.get_dummies(model_data.城市)
data_with_dummies = model_data.drop('城市', axis = 1).join(dummies)
data_with_dummies
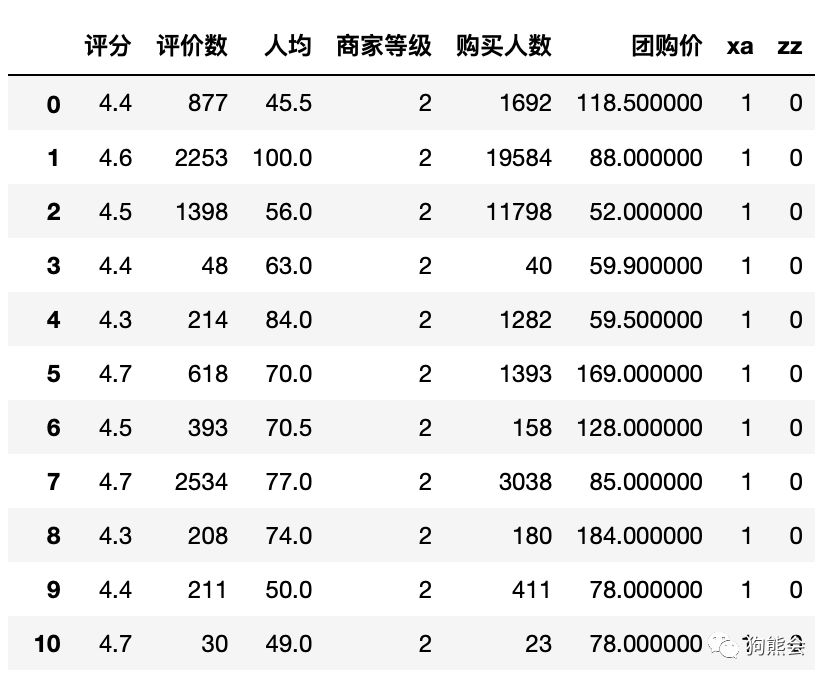
图1 利用get_dummies函数将分类变量转化为虚变量
但利用虚变量拟合某些统计模型时可能会有一些细微的差别。此时,我们可以选择使用Patsy,可能会更简单也更不容易出错。
当在Patsy公式中使用非数值的数据时,它会默认将这些数据转化为虚变量。如果模型有截距,那么为了避免共线性,Patsy会去掉分类变量新产生的虚变量的其中一列。但如果从模型中忽略截距,则每个分类变量的列都会包含在设计矩阵的模型中。
例2 用Patsy公式将分类变量转化为虚变量
y, X = patsy.dmatrices('购买人数 ~ 城市', model_data)
X

图2 用Patsy公式将分类变量转化为虚变量
例3 用Patsy公式将分类变量转化为虚变量(忽略截距)
y, X = patsy.dmatrices('购买人数 ~ 城市 + 0', model_data)
X

图3 用Patsy公式将分类变量转化为虚变量(忽略截距)
另外,火锅数据中的”商家等级“也应该是一个分类变量,只是以数值的形式存储了。此时可以使用C函数,将数值列截取为分类变量。具体方法如下。
例4 用Patsy公式将数值列转化为分类变量
y, X = patsy.dmatrices('购买人数 ~ C(商家等级)', model_data)
X

图4 用Patsy公式将数值列转化为分类变量
除此之外,Patsy还提供多种分类数据转化的其它方法,包括以特定顺序进行转化。详细信息可参考官方文档。
有了前面的铺垫,我们可以正式进入statsmodels的模型拟合部分。statsmodels有多种线性回归模型,包括最基本的(例如普通的最小二乘回归模型),以及复杂的(比如迭代加权最小二乘回归)等。这里我们基于火锅数据,选择对数线性回归模型,以购买人数的对数为因变量展示statsmodels中的模型使用。其他的模型的使用过程基本类似。
statsmodels的线性模型有两种不同的接口,一种基于数组,一种基于公式。它们都可以通过API模块引入。
例5 引入statsmodels的线性模型
import statsmodels.api as sm
import statsmodels.formula.api as smf
首先来看基于数组接入的线性模型的使用方法。在使用火锅数据前,首先对因变量进行对数处理,然后将“城市”和“商家等级”这两个变量转化为虚拟变量。再使用sm.add_constant添加线性模型中的截距,用sm.OLS进行普通最小二乘回归。
例6 基于数组接入最小二乘回归
y = np.log(model_data.购买人数 + 1).values
model_dummies_1 = pd.get_dummies(model_data.商家等级)
model_dummies_1.columns = ['商家等级_0', '商家等级_1', '商家等级_2']
model_dummies_2 = pd.get_dummies(model_data.城市)
model_data_with_dummies = model_data.drop(['商家等级', '城市'], axis = 1).join([model_dummies_1, model_dummies_2])
X = model_data_with_dummies.drop(['购买人数', '商家等级_0', 'xa'], axis = 1).values
X_model = sm.add_constant(X)
model = sm.OLS(y, X_model)
results = model.fit()
results.params

图5 基于数组接入最小二乘回归的拟合系数
模型的fit方法返回的是一个回归结果对象,它包含拟合的模型参数以及其他内容。通常使用.params查看模型的拟合系数。除此之外,summary方法可以对模型的详细诊断结果进行打印。
例7 summary打印模型详细诊断结果
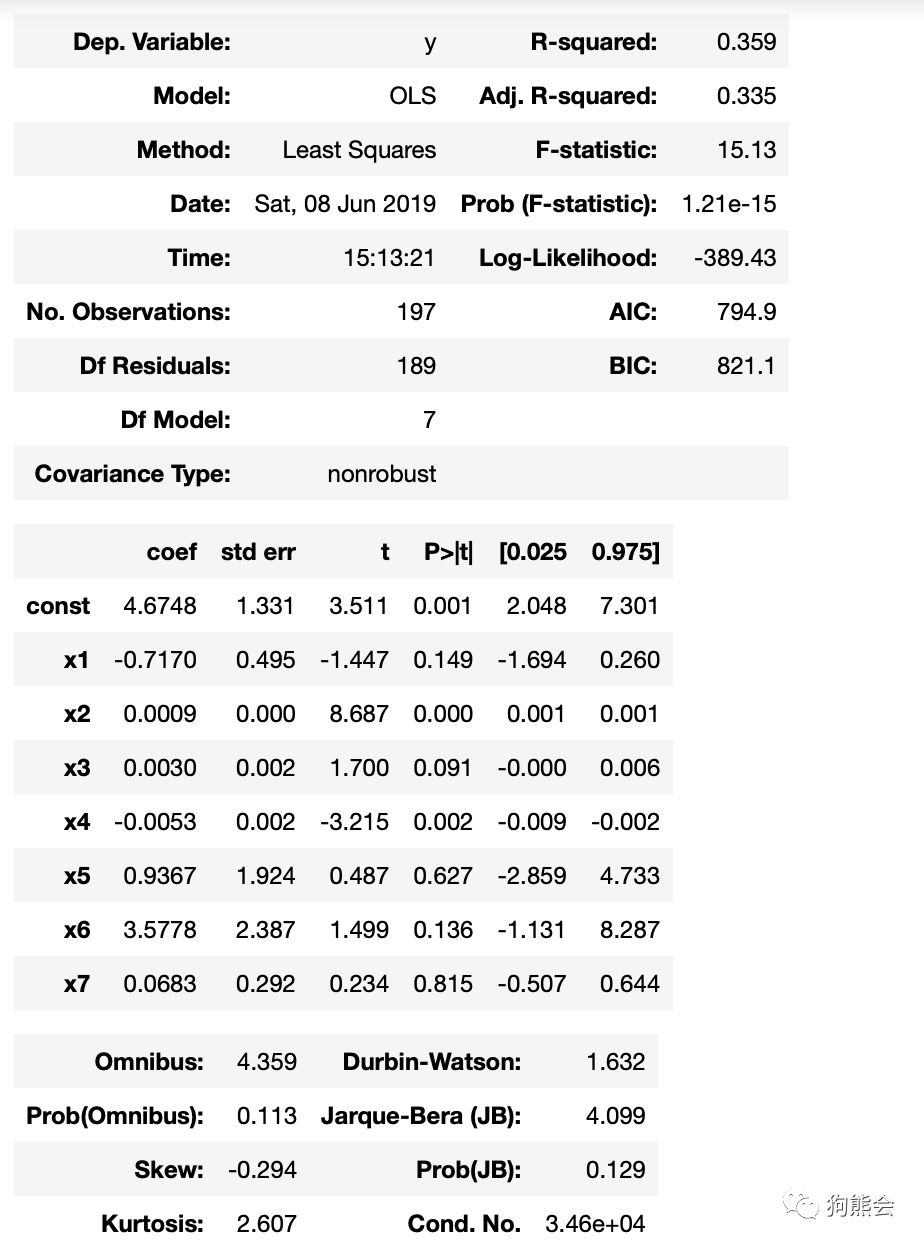
图6 summary打印模型详细诊断结果
此处可以会发现,这里的变量名为通用的x1,x2等。这就需要我们根据X的数据集再进行还原,从而分析每个变量的结果。那么如果想要变量名显示为数据集中的特有名称应该怎么办呢?接下来,就需要用到基于公式的线性模型接入。此时就要使用到我们之前介绍的Patsy库。
当所有的模型参数都在一个DataFrame中存储时,我们可以使用statsmodels的公式API以及Patsy的公式字符串来直接构建线性模型。
例8 基于公式接入最小二乘回归
results_f = smf.ols('np.log(购买人数 + 1) ~ 城市 + 评分 + 评价数 + 人均 + C(商家等级) + 团购价 ', data = model_data).fit() #用公式API和patsy公式拟合最小二乘回归模型
results_f.params #展示拟合参数

图7 基于公式接入最小二乘回归的拟合参数
此时可以发现,模型返回的是Series结果,同时还展示了DataFrame的列名。并且,在使用公式API和Patsy公式接入模型时,不再需要使用add_constant来手动添加截距项。同样的,使用summary可以查看模型的详细诊断结果。
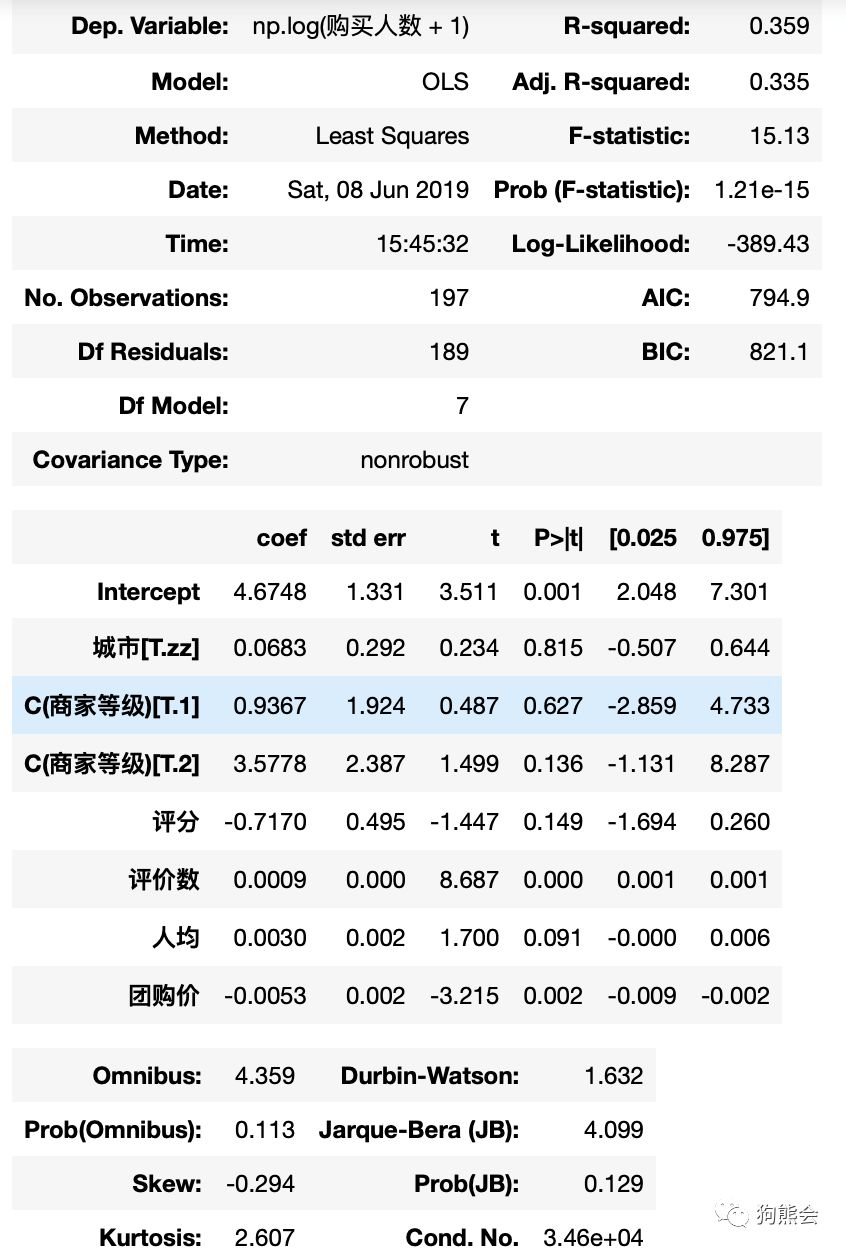
图8 基于公式接入模型的详细诊断结果
应用statsmodels拟合线性回归模型我们就介绍到这里。当然,statsmodels是一个非常强大的统计库,其可调用的模型还有很多,绝不仅仅只是最小二乘回归而已。对于其他统计模型的具体的调用逻辑其实都是大同小异的,这里我们就不再针对其他的模型调用展开详细的介绍,大家可以通过statsmodels的官方文档来自行进行后续的学习。
好了,今天就讲到这里。










