在对数据进行分析之前,需要对数据做一些预处理,包括数据分割、缺失值处理、删除近零方差变量、删除高度线性相关变量、数据标准化。
第一步是读入数据,对数据进行初步了解。下面以小说《三生三世十里桃花》中的人物信息为背景,具体的变量解释表如表1所示,其中因变量Y为“决定”这个变量。
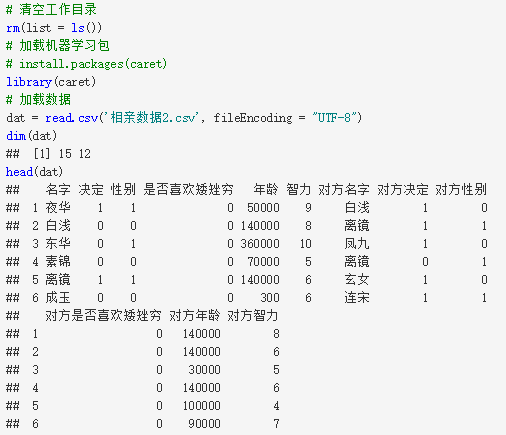
表1 变量说明表
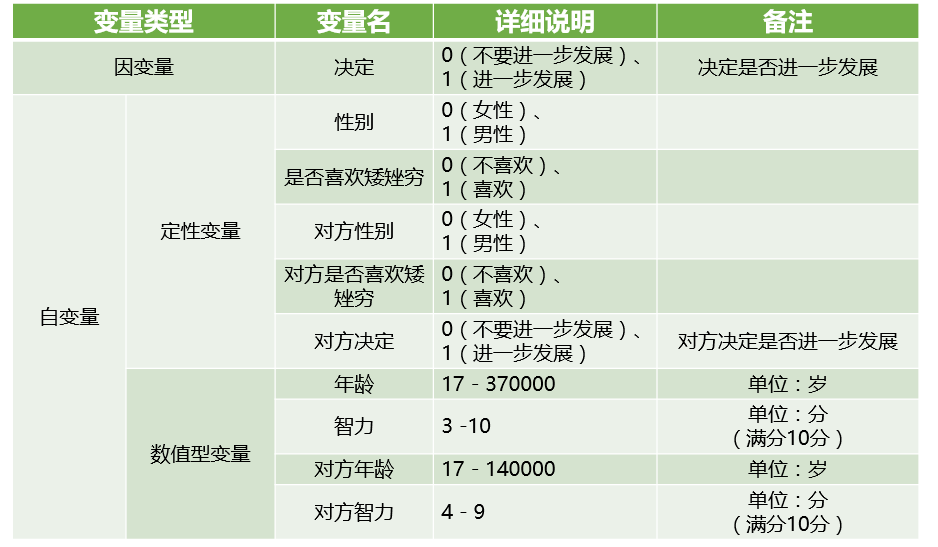
数据拿到之后,要先划分训练集和测试集。测试集是黑盒子,是不能触碰的炸弹,所做的任何处理,包括标准化、缺失值填补都只能基于训练集。下面介绍几个典型划分训练集和测试集的方法。
1.留出法
留出法分割是将样本分为两个互斥的子集,通常情况下,划分数据的80%为训练集,剩下的20%为测试集(见图1)。之前提过,caret包中的createDataPartition()函数不仅可以实现这样的划分,而且可以保证训练集和测试集中Y的比例是一致的,简而言之就是按照Y进行分层抽样。


图1 留出法
2.交叉验证法
交叉验证法将原始数据分成K组(一般是均分),每次训练将其中一组作为测试集,另外K-1组作为训练集。
实际应用中一般十折交叉验证用得最多,但是这里由于数据量太少,就以3折交叉验证为例(见图2),展示代码如下:

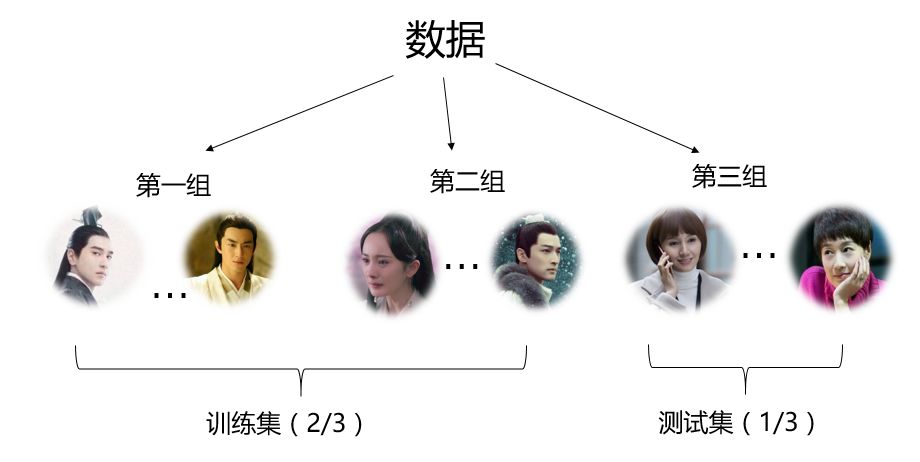
图2 交叉验证法
3.Bootstrap法
当数据量比较少时,Bootstrap抽样会成为“救命稻草”,它是一种从给定训练集中有放回的均匀抽样。也就是说,每当选中一个样本,它依然会被再次选中并被再次添加到训练集中。
createResample()函数中times参数用于设定生成几份随机样本,当times为3,意味着生成3份样本(见图3),不仅不同sample之间会有交叉,就连同一份sample中也会有重复的样本。

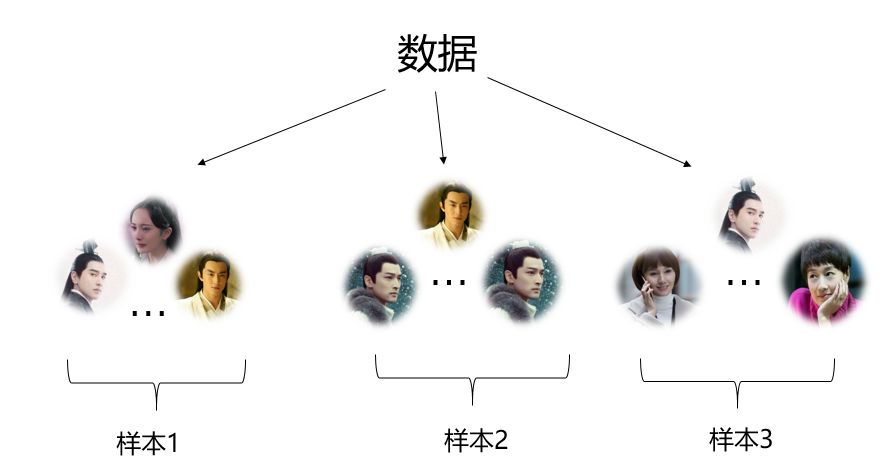
图3 Bootstrap法
上面这些划分训练集和测试集的方法都是针对横截面数据而言的,那么对于时间序列又该如何进行数据分割呢?
4.分割时间序列
以微信公号狗熊会中的水哥的成长数据为例,来展示如何对时间序列数据进行划分。
首先,读入水哥的成长数据。

接下来,利用caret包来分割时间序列。createTimeSlices()函数需要输入以下参数:initialWindow表示第一个训练集中的样本数;horizon参数表示每个测试集中的样本数;fixedWindow参数表示是否每个训练集中的样本数都相同。
从结果可以看出来,一共有2组训练集和测试集。第一组的训练集为1、2、3、4、5行观测,测试集为6、7行观测。那么第二组呢?从下面的数据就可以看出。

caret包中preProcess()函数实现了两种常用的缺失值处理方法:中位数填补法、K近邻方法。
1.中位数填补法
该方法直接用训练集的中位数代替缺失值,所以对于每个变量而言,填补的缺失值都相同,为训练集的中位数。该方法的优点是速度非常快,但填补的准确率有待验证。
罗子君被分到了测试集中,而中位数法插补出来罗子君的智力为8.5,下面验证一下训练集中所有人的智力中位数值是不是8.5呢?
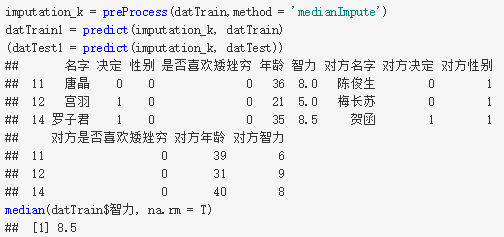
2.K近邻法
该方法的思想是“近朱者赤近墨者黑”。K近邻法对于需要插值的记录,基于欧氏距离计算k个和它最近的观测,然后接着利用k个近邻的数据来填补缺失值。
K近邻法会自动利用训练集的均值标准差信息对数据进行标准化,所以最后得到的数据是标准化之后的。如果想看原始值,那么还需要将其去标准化倒推回来。


这个错误的意思是说是否喜欢矮矬穷和对方是否喜欢矮矬穷这两个变量的方差为0。
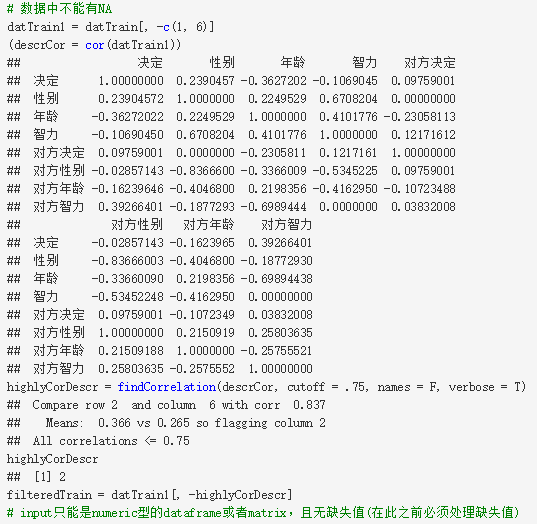
这种零方差或者近零方差的变量传递不了什么信息,因为几乎所有人的取值都一样。可以利用caret包中的nearZeroVar()函数,一行代码就能找出近零方差的变量,操作过程非常简单。

caret包中的findCorrelation()函数会自动找到高度共线性的变量,并给出建议删除的变量。
但需要注意,这个函数对输入的数据要求比较高:首先,数据中不能有缺失值,所以在此之前需要先处理缺失值;其次,只能包含数值型变量。
为什么要标准化?很简单,看看年龄,几十万岁,但是智力这个变量最高也才10分,这两列变量的量纲不同,为了防止年龄的权重过高,就需要将这些特征进行标准化才能学习各个变量真实的权重。需要注意的是:只能拿训练集的均值和标准差来对测试集进行标准化。

请扫描以下二维码/点击链接购买
《
R语言:从数据思维到数据实战》


https://detail.tmall.com/item.htm?spm=a220z.1000880.0.0.0A6pvS&id=581845865737











