本文将同时对Firebird、MySQL和PostgreSQL三个项目进行比较,找出具有意思的bug并且代码质量最高的一个项目。下面直入主题!
 关于项目写在前面的话
关于项目写在前面的话
Firebird

Firebird(Firebird SQL)是一个开源的SQL关系数据库管理系统,它在Linux、Microsoft Windows、Mac OS X和各种Unix上运行。这个数据库是在2000年由Borland的InterBase开源版本开源的,但是从Firebird 1.5版本以来大部分代码已经被重写。
附加信息:
· Official website(官方网站)
· GitHub repository(GitHub库)
· GitHub好评得分:133
· GitHub差评得分:51
MySQL

MySQL是一个开源的关系数据库管理系统(RDBMS)。MySQL通常用作本地和远程客户端的服务器,但是发行版还包括一个嵌入式MySQL服务器库,这使得在客户应用程序中运行MySQL服务器成为可能。
MySQL支持多种表类型,这使它成为一种非常灵活的工具:用户可以在支持全文搜索的MyISAM表和InnoDB表之间进行选择,而InnoDB表支持个单个记录级别的事务。MySQL还附带了一个名为EXAMPLE的特殊表类型,用于描述创建新表类型的原则。由于开放的体系结构和GPL许可,新表类型经常被归到MySQL中。
附加信息:
· Official website(官方网站)
· GitHub repository(GitHub库)
· GitHub好评得分:2179
· GitHub差评得分:907
PostgreSQL

PostgreSQL是一个对象关系数据库管理系统(ORDBMS)。它可以处理各种工作负载,从小型单机应用程序到大型的面向网络的拥有许多并发用户的应用程序(或用于数据仓库);在macOS服务器上,PostgreSQL是默认数据库;也可以用于Microsoft Windows和Linux(大多数提供的是发行版)。PostgreSQL是由PostgreSQL全球开发小组开发的,该小组是一个由许多公司和个人贡献者组成的多样化团队。PostgreSQL是免费和开源的,并且根据PostgreSQL许可证的条款发布,PostgreSQL许可证是比较宽松的。
附加信息:
· Official website(官方网站)
· GitHub repository mirror(GitHub镜像库)
· GitHub好评得分:3260
· GitHub差评得分:1107
PVS-Studio

我使用了静态代码分析器PVS-Studio来检测bug。PVS-Studio是一个由C、C++和C#编写的源代码的分析器,它通过早期发现程序源代码中的漏洞、缺陷和安全问题,有助于减少软件开发成本。PVS-Studio在Windows和Linux上运行。
下载链接:
· Windows
· Linux
由于这三个项目中的每一个都很容易构建并且都包含.sln文件(从一开始就可用,或者通过CMake生成),分析本身就变成了一项非常简单的任务:只需要在Visual Studio的PVS-Studio插件中启动一个检查。
比较标准
在开始讨论之前,我们必须先决定使用什么比较标准。这是本文的主要关注点之一。
为什么“Head-On”的比较不是一个好主意
根据分析器生成的错误消息的数量(更精确的说是消息的数量/数量的LOC比率)进行“Head-On”比较虽然花费最少,但不是一个好方式。其原因,以PostgreSQL项目为例。PostgreSQL触发了611个高确定性级别的GA警告,但是如果通过PVS-Studio诊断规则的代码(V547)以及ret < 0消息的一部分,来过滤警告。将有419个警告!显然PostgreSQL触发了过多警告,似乎所有这些消息都来自于一个单独的源,例如宏或自动生成的代码。发布警告文件开头的评论,证明我们的假设是正确的:
1 /* This file was generated automatically
2 by the Snowball to ANSI C compiler */
既然代码是自动生成的,那么有两个选择:
1. 在生成的代码中禁止所有我们不感兴趣的警告。这样就减少了消息的总数(GA,Lvl1)的高达69%!
2. 接受自动生成代码中的bug仍然是bug,并尝试对它们进行一些操作(比如,修复代码生成脚本)。在这种情况下,消息的数量保持不变。
另一个问题是在项目中使用的第三方组件中发现的错误。同样有两个选择:
· 假装这些bug与你无关——但是用户未必会同意
· 承担出现这些错误的责任
这只是几个例子,说明我们必须做出的选择是如何影响(有时严重)需要处理的警告数量。
另一种方式
我们同意把3(低确定性)级别的消息保留下来。但是写分析文章和使用静态分析的时候会忽略掉。
本文章不是一个全面的比较。全面比较需要对每个项目的分析程序进行初步配置,并在检测后浏览和检查数百条消息。太过浪费时间。
本文将查看每个项目的日志,挑选最有趣的bug,对它们进行注释,并检查其他两个项目是否有类似的问题。
我们最近开始关注安全问题,并发布了一篇文章,题目是“How Can PVS-Studio Help in the Detection of Vulnerabilities?”。MySQL作为本文的内容之一,在上述文章中提到过,鉴于我很想知道PVS-Studio是否能够检测到特定的代码模式。我会额外地寻找类似于上述文章中讨论过的警告。

因此,我将再次根据以下标准对代码质量进行评估:
· 首先,我将浏览这三篇日志,以获得与上述安全相关的文章中所讨论的相同的警告。这个想法很简单:如果我们知道某个代码模式可能是一个漏洞(即使并非所有情况下都是),那么我们应该仔细研究一下它。
· 然后,我将查看前两个确定性级别的GA警告,选择最感兴趣的,并检查其他项目是否触发了类似的警告。
在进程中,我将对每个项目都进行缺陷计分,得分最少的那个项目将会是胜出者(在前面讨论的限制条件中)。一些具体的细节,我将在过程中以及本文的最后对其进行注释。
开始比较!
bug审查
总分析结果
下表显示了“as is”的总分析结果,即没有假阳性结果,也没有任何文件夹的过滤,等等。注警告只参考General Analysis分析集。
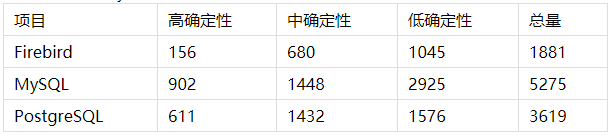
上表对于得出任何关于代码质量的结论都不是一个好依据。如前所述,有很多原因:
· 没有分析仪初步配置
· 没有假阳性抑制
· 代码库大小不同
· 在撰写本文时,我们对分析程序进行了更改,因此“前”和“后”结果可能略有不同。
至于警告(不是bug)的密度,即消息数量和LOC之间的比率,由于是在没有初步配置的情况下测定,对于Firebird和PostgreSQL来说结果是一样的,对于MySQL来说稍微高一点。但我们不能妄下结论,因为在细节中还有重要信息。
清除私有数据的问题
V597诊断是通过调用memset函数的演示以及执行数据清除来发布的,私有数据在优化时可以由编译器移除。因此私有数据可能仍未被清除。有关详细信息,请参阅有关诊断的文档。
Firebird和PostgreSQL都没有触发这种类型的消息,但MySQL确实做到了。下面的例子就是从MySQL选取的:
1extern "C"
2char *
3my_crypt_genhash(char *ctbuffer,
4 size_t ctbufflen,
5 const char *plaintext,
6 size_t plaintext_len,
7 const char *switchsalt,
8 const char **params)
9{
10 int salt_len;
11 size_t i;
12 char *salt;
13 unsigned char A[DIGEST_LEN];
14 unsigned char B[DIGEST_LEN];
15 unsigned char DP[DIGEST_LEN];
16 unsigned char DS[DIGEST_LEN];
17 ....
18 (void) memset(A, 0, sizeof (A));
19 (void) memset(B, 0, sizeof (B));
20 (void) memset(DP, 0, sizeof (DP));
21 (void) memset(DS, 0, sizeof (DS));
22
23return (ctbuffer);
24}
PVS-Studio警告:
· V597编译器可以删除“memset”函数调用,该函数用于刷新“A”缓冲区。应该使用RtlSecureZeroMemory()函数来删除私有数据。
crypt_genhash_impl.cc 420
· V597编译器可以删除“memset”函数调用,该函数用于刷新“B”缓冲区。应该使用RtlSecureZeroMemory()函数来删除私有数据。
crypt_genhash_impl.cc 421
· V597编译器可以删除“memset”函数调用,该函数用于刷新“DP”缓冲区。应该使用RtlSecureZeroMemory()函数来删除私有数据。
crypt_genhash_impl.cc 422
· V597编译器可以删除“memset”函数调用,该函数用于刷新“DS”缓冲区。应该使用RtlSecureZeroMemory()函数来删除私有数据。
crypt_genhash_impl.cc 423
分析器检测到一个具有多达4个缓冲区(!)的函数,这些缓冲区必须被强制清除。但是该函数可能无法做到这一点,因此导致数据保留在内存“as-is ”中。由于在后续操作中没有使用缓冲区A、B、DP和DS,所以编译器可以取消对memset函数的调用,因为从c/c++语言的角度来看,这样的优化不会影响程序的行为。有关此问题的更多信息,请参阅文章Safe Clearing of Private Data(安全清除私有数据)。
其余的消息都一样,所以只列出下面几个:
· V597编译器可以删除“memset”函数调用,该函数用于刷新“table_list”对象。应该使用RtlSecureZeroMemory() 函数来删除私有数据。sql_show.cc 630
· V597编译器可以删除“memset”函数调用,该函数用于刷新“W”缓冲区。应该使用RtlSecureZeroMemory() 函数来删除私有数据。sha.cpp 413
· V597编译器可以删除“memset”函数调用,该函数用于刷新“W”缓冲区。应该使用RtlSecureZeroMemory() 函数来删除私有数据。sha.cpp 490
· V597编译器可以删除“memset”函数调用,该函数用于刷新“T”缓冲区。应该使用RtlSecureZeroMemory() 函数来删除私有数据。sha.cpp 491
· V597编译器可以删除“memset”函数调用,该函数用于刷新“W”缓冲区。应该使用RtlSecureZeroMemory() 函数来删除私有数据。sha.cpp 597
· V597编译器可以删除“memset”函数调用,该函数用于刷新“T”缓冲区。应该使用RtlSecureZeroMemory() 函数来删除私有数据。sha.cpp 598
这里有一个更有趣的例子。
1void win32_dealloc(struct event_base *_base, void *arg)
2{
3 struct win32op *win32op = arg;
4 ....
5 memset(win32op, 0, sizeof(win32op));
6 free(win32op);
7}
PVS-Studio警告:V597:编译器可以删除“memset”函数调用,该函数用于刷新“win32op”对象。应该使用RtlSecureZeroMemory() 函数来删除私有数据。win32.c 442
它与前面的示例类似,但在清除内存块之后,指针将被传递给自由函数。但即使这样,编译器仍然可以删除对memset的调用,只留下对自由函数的调用(清除内存块)。因此,要清除的数据仍然存在于内存中。要了解更多信息,请参阅上面提到的文章。
缺点评分。这是一个相当严重,甚至可能会更严重的错误,因为它有三个实例。MySQL得3分。
不对Malloc返回的指针和其他类似函数进行检查
三个项目都触发了V769警告。
· Firebird:高度确定性-0;中等确定性- 0;低确定性- 9
· MySQL:高确定性-0;中确定性- 13;低确定性- 103
· PostgreSQL:高度确定性-1;中确定性-2;低确定性- 24
由于忽略第三等级的警告,所以不需要对Firebird进行下一步操作(上述结果显示它已经最优)。PostgreSQL的三个警告被证明是不相关的。只有MySQL还引发了一些误报,其中一些警告值得关注。
1bool
2Gcs_message_stage_lz4::apply(Gcs_packet &packet)
3{
4 ....
5 unsigned char *new_buffer =
6 (unsigned char*) malloc(new_capacity);
7 unsigned char *new_payload_ptr =
8 new_buffer + fixed_header_len + hd_len;
9
10 // compress payload
11 compressed_len=
12 LZ4_compress_default((const char*)packet.get_payload(),
13 (char*)new_payload_ptr,
14 static_cast(old_payload_len),
15 compress_bound);
16 ....
17}
PVS-Studio警告:V769:“new_buffer + fixed_header_len”表达式中的“new_buffer”指针可以是nullptr。在这种情况下,产生的值无意义,不该使用该值。检查第74、73行。gcs_message_stage_lz4.cc 74
如果它不能分配所请求的内存块,那么malloc函数将返回一个可以存储到new_buffer变量的空指针。接下来,随着new_payload_ptr变量的初始化,new_buffer指针的值将被添加到变量fixed_header_len和hd_len的值里。对于new_payload_ptr来说,这是一个没有返回的点:如果(如,在另一个函数中),检查它是否为NULL,该检查没有任何意义。因此,在初始化new_payload_ptr之前,先确保new_buffer是非空的是明智的。
你可能会认为,既然malloc未能分配所请求的内存块,检查NULL的返回值也没有多大意义。应用程序不能继续它的正常工作,那么为什么不让它在下一次使用指针时崩溃呢?
由于相当多的开发人员坚持这种方法,它可以被称为合法的——但是这种方法就是正确的吗?毕竟,我们可以尝试以某种方式处理这种情况以保存数据,或者让应用程序以一种“softer way”崩溃。另外,这种方法可能会导致安全问题,因为如果应用程序碰巧处理另一个内存块(空白指针+值),而不是空指针本身,可能会损坏一些数据。所有这些操作都使程序更加脆弱。你必须自己衡量利弊,自己判断哪些是正确的选择。
我推荐第二种方法——V769诊断可以检测这些问题。
如果确信这些函数不会返回NULL,告知分析器,就不会再次收到相同的警告。请参阅Additional Diagnostics Configuration,以了解如何进行诊断。
缺点评分:考虑上面提到的所有内容,MySQL得1分。
潜在空指针的使用
在三个项目中都发现了这种类型的警告(诊断V575)。
下面是Firebird(中确定性)的一个例子:
1static void write_log(int log_action, const char* buff)
2{
3 ....
4 log_info* tmp = static_cast(malloc(sizeof(log_info)));
5 memset(tmp, 0, sizeof(log_info));
6 ....
7}
PVS-Studio警告:V575:潜在的空指针被传递到“memset”函数中。检测第一个参数。检查第1106、1105行。iscguard.cpp 1106
此缺陷与前一项类似——未对malloc函数返回的值进行检查。如果它不能分配所请求的内存块,malloc将返回一个空指针,该空指针将被传递给thememset函数。
下面是MySQL的一个类似的例子:
1Xcom_member_state::Xcom_member_state(....)
2{
3 ....
4 m_data_size= data_size;
5 m_data= static_cast(malloc(sizeof(uchar) * m_data_size));
6 memcpy(m_data, data, m_data_size);
7 ....
8}
PVS-Studio警告:V575:潜在的空指针被传递到“memcpy”函数中。检测第一个参数。检查第43、42行。gcs_xcom_state_exchange.cc 43
这跟Firebird的类似。为了说明问题,这里有一些代码片段,检查发现这些代码片段返回的值malloc不等于null。
下面是来自PostgreSQL的类似片段:
1static void
2e2cpg_filter(const char *sourcefile, const char *outfile)
3{
4 ....
5 n = (char *) malloc(plen);
6 StrNCpy(n, p + 1, plen);
7 ....
8}
PVS-Studio警告:V575潜在的空指针被传递到“strncpy”函数中。检测第一个参数。检查第66、65行。pg_regress_ecpg.c 66
MySQL和PostgreSQL触发了一些高级别的警告,这些警告更有意义。
MySQL的一个实例:
1View_change_event::View_change_event(char* raw_view_id)
2 : Binary_log_event(VIEW_CHANGE_EVENT),
3 view_id(), seq_number(0), certification_info()
4{
5 memcpy(view_id, raw_view_id, strlen(raw_view_id));
6}
PVS-Studio警告:V575 “memcpy”函数不复制整个字符串。使用“strcpy / strcpy_s”函数保存终端null。control_events.cpp 830
memcpy函数用于复制从raw_view_id 到 view_id的字符串;使用strlen函数计算要复制的字节数。这里的问题是,strlen忽略了终止字符null,复制字符串时没有复制null。如果不手动添加,其他字符串函数将无法正确地处理view_id。要确保对字符串的正确复制,请使用strcpy / strcpy_s。
PostgreSQL下面的片段看起来与上述情况非常相似:
1static int
2PerformRadiusTransaction(char *server,
3 char *secret,
4 char *portstr,
5 char *identifier,
6 char *user_name,
7 char *passwd)
8{
9 ....
10 uint8 *cryptvector;
11 ....
12 cryptvector = palloc(strlen(secret) + RADIUS_VECTOR_LENGTH);
13 memcpy(cryptvector, secret, strlen(secret));
14}
PVS-Studio警告:V575:“memcpy”函数不会复制整个字符串。使用“strcpy / strcpy_s”函数来保存终端null。auth.c 2956
与前面的例子一个有趣的区别。cryptvector变量类型是 uint8 *。虽然uint8是无符号字符(unsigned char)的别名,但是程序员似乎使用它显式地指出这些数据不是作为字符串处理的;因此,考虑到上下文,这个操作是有效的,并且不像之前的情况那样可疑。
一些被报告的片段看起来并不安全。
1int
2intoasc(interval * i, char *str)
3{
4 char *tmp;
5
6 errno = 0;
7 tmp = PGTYPESinterval_to_asc(i);
8
9 if (!tmp)
10 return -errno;
11
12 memcpy(str, tmp, strlen(tmp));
13 free(tmp);
14 return 0;
15}
PVS-Studio警告:V575:“memcpy”函数不会复制整个字符串。使用“strcpy / strcpy_s”函数来保存终端null。informix.c 677
这个问题遵循相同的模式,但更像是MySQL的例子:处理字符串的操作,并将字符串的内容(除了null字符)使用外部函数复制到内存中。
缺点评分:Firebird得1分,PostgreSQL和MySQL各得3分(一个中确定性警告得1分,一个高确定性警告得2分)。
对格式化输出函数潜在的不安全使用
只有Firebird触发了几个V618的警告。
看下面的例子:
1static const char* const USAGE_COMP = " USAGE IS COMP";
2static void gen_based( const act* action)
3{
4 ....
5 fprintf(gpreGlob.out_file, USAGE_COMP);
6 ....
7}
PVS-Studio警告: V618:以这种方式调用“fprintf”函数是危险的,因为传递的行可能包含格式规范。安全代码的示例:printf(“%s”,str);cob.cpp 1020
使用格式化输出函数fprintf使分析器发出了警告,而字符串是直接写入的,没有使用格式字符串和相关的指定符。如果输入字符串碰巧包含格式指定符,这一操作可能是危险的,甚至会导致一个安全问题(参见CVE-2013-4258)。在本例中,在源代码中明确地对USAGE_COMP字符串进行了定义,并且不包含任何格式指定符,因此可以在这里安全地使用fprintf函数。
其他情况也是如此:输入字符串是硬编码的,没有格式指定符。
缺点评分:考虑到以上所述,我不会给Firebird记任何缺点分。
文章中提到的其他关于漏洞的警告
上述项目都没有触发V642 和 V640 警告。
枚举元素的可疑使用
MySQL的实例如下:
1enum wkbType
2{
3 wkb_invalid_type= 0,
4 wkb_first= 1,
5 wkb_point= 1,
6 wkb_linestring= 2,
7 wkb_polygon= 3,
8 wkb_multipoint= 4,
9 wkb_multilinestring= 5,
10 wkb_multipolygon= 6,
11 wkb_geometrycollection= 7,
12 wkb_polygon_inner_rings= 31,
13 wkb_last=31
14};
15bool append_geometry(....)
16{
17 ....
18 if (header.wkb_type == Geometry::wkb_multipoint)
19 ....
20 else if (header.wkb_type == Geometry::wkb_multipolygon)
21 ....
22 else if (Geometry::wkb_multilinestring)
23 ....
24 else
25 DBUG_ASSERT(false);
26 ....
27}
PVS-Studio警告:V768:枚举常量“wkb_multilinestring”被用作布尔类型的变量。item_geofunc.cc 1887
这条消息实际上是说了一切。有两个条件表达式将header.wkbtype与Geometry枚举元素进行比较,而整个第三个表达式本身就是一个枚举器。鉴于Geometry::wkb_multilinestring有值5,第三个条件语句的主体将在前两次检查失败时执行。因此,包含对DBUG_ASSERT宏调用的else-分支将永远不会被执行。这表明第三个条件表达式是这样的:
1header.wkb_type==Geometry::wkb_multilinestring
PostgreSQL并没有触发这种类型的警告,而Firebird则触发多达9个警告。然而,这些警告的级别都不那么重要的(中等确定性),并且检测到的模式也不一样。
V768诊断检测到下列错误模式:
· 高确定性:枚举成员被用作布尔表达式。
· 中确定性:枚举类型的变量被用作布尔表达式。
一级警告毫无辩解的理由,但第二等级的警告仍有可讨论的余地。
例如,大多数情况是这样的:
1enum att_type {
2 att_end = 0,
3 ....
4};
5void fix_exception(...., att_type& failed_attrib, ....)
6{
7 ....
8 if (!failed_attrib)
9 ....
10}
PVS-Studio警告: V768:变量“failed_attrib”是enum类型。把它用作布尔类型的一个变量有点奇怪。restore.cpp 8580
分析器发现以上述方式对变量failed_attrib进行值att_type::att_end检查的结果是可疑的。我更喜欢与枚举器进行显式的比较,但不能认为此代码不正确。虽然我个人不喜欢这种风格(分析器也不喜欢),但它仍然是合法的。
两个碎片看起来更可疑。两者都有相同的模式,所以我们只讨论其中的一个
1namespace EDS {
2 ....
3 enum TraScope {traAutonomous = 1, traCommon, traTwoPhase};
4 ....
5}
6class ExecStatementNode : ....
7{
8 ....
9 EDS::TraScope traScope;
10 ....
11};
12void ExecStatementNode::genBlr(DsqlCompilerScratch* dsqlScratch)
13{
14 ....
15 if (traScope)
16 ....
17 ....
18}
PVS-Studio警告: V768:变量“traScope”是enum类型的。把它用作布尔类型的一个变量有点奇怪。stmtnodes.cpp 3448
这个例子与前面的例子类似:程序员也检查traScope变量的值与枚举器成员的非零值是否相同。然而,与前面的示例不同的是,这里没有值为“0”的枚举成员,这使得该代码更加可疑。
既然我们已经开始讨论中确定性警告,我应该再加上针对MySQL发出的10个这样的消息。
缺点评分:Firebird得1分,而MySQL则得2分。
内存块大小的错误确定性
另一个有趣的代码片段。我们在讨论私有数据的清理时已经注意到了这个问题。
1struct win32op {
2 int fd_setsz;
3 struct win_fd_set *readset_in;
4 struct win_fd_set *writeset_in;
5 struct win_fd_set *readset_out;
6 struct win_fd_set *writeset_out;
7 struct win_fd_set *exset_out;
8 RB_HEAD(event_map, event_entry) event_root;
9
10 unsigned signals_are_broken : 1;
11};
12void win32_dealloc(struct event_base *_base, void *arg)
13{
14 struct win32op *win32op = arg;
15 ....
16 memset(win32op, 0, sizeof(win32op));
17 free(win32op);
18}
PVS-Studio警告:V579:memset函数接收指针及其大小作为参数。这可能是一个错误。检测第三个参数。win32.c 442
注意调用thememset函数时的第三个参数。sizeof运算符以字节的形式返回它的参数的大小,但是这里的参数是一个指针,所以它返回的是指针的大小而不是结构的大小。
即使编译器不会丢弃对memset的调用,也会导致内存清理不完全。
得出的结论是,应该谨慎地选择变量名,尽量避免使用相似的名字。但是并不能完全避免,所以要特别注意这些情况。在C/C++项目中通过 V501诊断以及在C#项目通过V3001诊断检测到的很多错误都是由于变量名命名问题而产生的。
其他两个项目没有发布V579警告。
缺点评分:MySQL得2分。
在MySQL中也发现了另一个类似的bug。
1typedef char Error_message_buf[1024];
2const char* get_last_error_message(Error_message_buf buf)
3{
4 int error= GetLastError();
5
6buf[0]= '';
7 FormatMessage(FORMAT_MESSAGE_FROM_SYSTEM,
8 NULL, error, MAKELANGID(LANG_NEUTRAL, SUBLANG_DEFAULT),
9 (LPTSTR)buf, sizeof(buf), NULL );
10
11 return buf;
12}
PVS-Studio警告:V511sizeof()操作符返回的是“sizeof (buf)”表达式指针的大小,而不是数组的大小。common.cc 507
Error_message_buf是char类型的1024个元素数组的别名。重要的是:即使一个函数签名是下面这样写的:
1const char* get_last_error_message(char buf[1024])
buf仍然是一个指针,而数组大小对程序员来说只是一个提示。这意味着,sizeof(buf) 表达式与这里的指针一起工作,而不是数组。这导致将一个不正确的缓冲区大小传递给函数-4或8,而不是1,024。
在Firebird和PostgreSQL中没有这样的警告。
缺点评分:MySQL得到2分。
失踪的“throw”关键字
这是MySQL中另一个有趣的bug。它是一个小片段,完整展现出来如下:
1mysqlx::XProtocol* active()
2{
3 if (!active_connection)
4 std::runtime_error("no active session");
5 return active_connection.get();
6}
PVS-Studio警告:V596:对象被创建,但没有被使用。“throw”关键字可能会丢失:抛出runtime_error(FOO);mysqlxtest.cc 509
程序员创建了一个std::runtime_error类的对象,但不以任何方式使用它。他们显然是想抛出一个异常,但忘记了编写抛出关键字。这种情况 (active_connection == nullptr)不能如预期的那样处理。
Firebird和PostgreSQL都没有触发这种类型的警告。
缺点评分:给MySQL 2分。
调用错误的内存回收操作符
下面的例子取自Firebird。
1class Message
2{
3 ....
4 void createBuffer(Firebird::IMessageMetadata* aMeta)
5 {
6 unsigned l = aMeta->getMessageLength(&statusWrapper);
7 check(&statusWrapper);
8 buffer = new unsigned char[l];
9 }
10 ....
11 ~Message()
12 {
13 delete buffer;
14 ....
15 }
16 .....
17 unsigned char* buffer;
18 ....
19};
PVS-Studio警告:V611内存是使用“new T[]”操作符分配的,但使用“delete”操作符释放。考虑到这段代码检查。使用“delete [] buffer”可能更好一些。检查第101、237行。message.h 101
缓冲区的内存块(由缓冲区指针指向,是类消息的一个成员),使用new[]操作符,在一个名为createBuffer的特殊方法中被分配,这种分配符合标准。但是,类析构函数通过使用delete操作符而不是delete[]来处理内存块。
在MySQL和PostgreSQL中没有发现这种类型的错误。
缺点评分:Firebird得2分
总结
总结一下缺点,如下:
· Firebird: 1 + 1 + 2 = 4 分
· MySQL: 3 + 1 + 2 + 2 + 2 + 2 = 12分
· PostgreSQL: 3分
得分越少越好。但我会选择MySQL !它有最有趣的bug,它是领导者,这使它成为分析的完美选择!
Firebird和PostgreSQL是比较复杂的。一方面,即使是一个点的边际也很重要;另一方面,这是一个非常小的差别,特别是因为该点是为一个中确定性级别的V768警告而给出的。但是,PostgreSQL的代码库更大,它在自动生成的代码中发出了400个警告。
为了弄清楚Firebird和PostgreSQL这两个项目哪一个更好,我们需要做一个更彻底的比较。我把三个项目按照领奖台的方式呈现。也许有一天我们会更加仔细地将它们进行比较,可能结果会完全不同。
综上,代码质量排名如下:
l 第一名:Firebird和PostgreSQL
l 第二名:MySQL

任何回顾或比较,包括本文,都是主观的。不同的比较方法可能会产生不同的结果(尽管对于Firebird和PostgreSQL来说,本文比较的结果是准确的,但是对MySQL来说,结果可能是不准确的)。
关于静态分析,我希望读完本文,你确信对于各种类型缺陷的检测是有用的。想知道自己的代码库是否存在本文中提到的这些bug,可以尝试PVS-Studio!也可以检测一下自己写的或者同事写的代码是否完全正确。













