
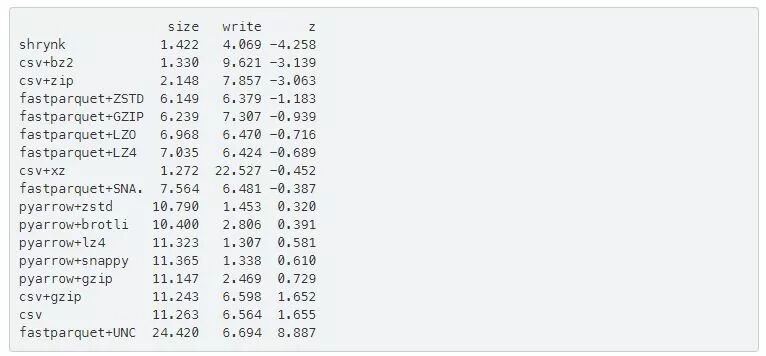
与使用单一最佳策略相比,减少了30%的磁盘需求。
当我正在存储压缩CSV文件时,我的存储着加密货币数据的服务器就开始溢出。为了找到一个快速的解决方案,我认为我应该切换到一个更有效的压缩算法(它是使用gzip存储的)。但如何快速找出哪个更好呢?
快进:我用机器学习创建了用于压缩的包shrynk !它可以通过选择(并应用)格式来帮助你压缩你的dataframe、JSON或一般的文件。
给定示例数据后,与最好的单一压缩算法相比,通过机器学习使用一个混合策略,它能够压缩总磁盘空间的30%(意思是:选择任何其他单一压缩算法来压缩所有内容将更糟糕)。
你可以在https://shrynk.ai 自行尝试它。
好处: 如果算法出错,数据的特征(如行数、列数,但不是数据本身)将在下一个版本中会被添加到该python包中!这使得算法可以学习何时应用哪种压缩算法。
接下来,我将解释压缩、机器学习和我用Python构建的这个库。你还可以使用下面的链接跳转到其中一个部分。
压缩
压缩就是减少数据的大小。这样做的明显原因是为了能够存储更多的数据。由于IO /Networking(到磁盘或通过internet)常常是瓶颈,而不是CPU处理过程,所以在数据传输之前压缩数据,然后再进行解压缩是有意义的。
不同的算法为不同类型的数据而存在,比如图像、视频、音频,还有文本和通用文件。只要有一个模式可以使用,任何数据都可以被压缩。例如,一个压缩算法可能会发现,在图像中有许多重复地方:会存在有相同颜色的像素区域,使用压缩就可以不用单独地存储每个像素。
在视频中,它不仅仅是“2D”,也有时间维度,一个成功的压缩方法可能是只存储帧与帧之间的增量,也就是说,只存储与上一帧不同的视频。而另一个例子就是空白,它可以被压缩到JSON文件中。
压缩表格数据
shrynk的第一种情况与矩阵/表格数据有关:数据的行和列。下面是一个名为toy_data.csv的示例文件:

我们只关心性别变量。对于每一行,存储female 或 male都不是最优的,因为我们知道这是这一列中惟一的值。一种改进是获取列中的所有值,并执行一个替换:F表示female,M表示male。字符串越短越好,对吧?当然,为了解压,你需要添加额外的数据,即F表示female,M表示male,但是像这样,你只需存储一次“较长的”字符串。这是字典编码的一部分,并在Parquet格式中被使用。
Parquet的另一个优化是使用行程长度编码,它利用的是对相同的值经常按顺序出现的观察。过度简化一点,我们可以将性别列编码为3F2M。对其进行解压缩,就会将其展开回原始数据。
注意,与此同时,你可能会认为Parquet模式不一定更适合浮点值(如pi),因为这些值通常是惟一的,所以我们不能使用这些技巧。
Python中的表格数据
对于表格数据,我们通常使用pandas.read_csv从磁盘读入数据并生成一个DataFrame。
然而,csv通常是未压缩的。不过,使用压缩我们可以轻松地将一个dataframe写回到磁盘。这里有几个可用的压缩和不压缩选项:
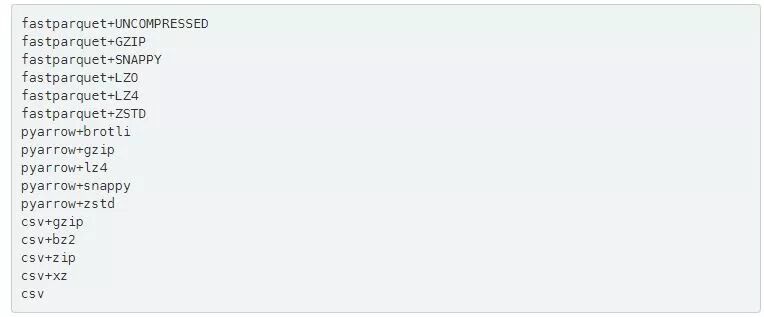
+之前的第一部分是“引擎”(csv是由df.to_csv处理的,并且pyarrow和fastparquet是用于df.to_parquet的不同库),而后者是正在使用的压缩。
事实证明,很难找出何时使用哪种格式,也就是说,要在这么多选项中找到正确的“边界”,这取决于很多因素。
如果能知道哪种压缩方式最好就太好了,不是吗?
运行基准测试
首先,shrynk可以帮助你为自己的文件运行基准测试,当然也可以为一组文件运行基准测试。
我采用了之前的性别/年龄玩具数据,并在下面显示了如何获得一个文件的每个压缩方式的实际分析结果。
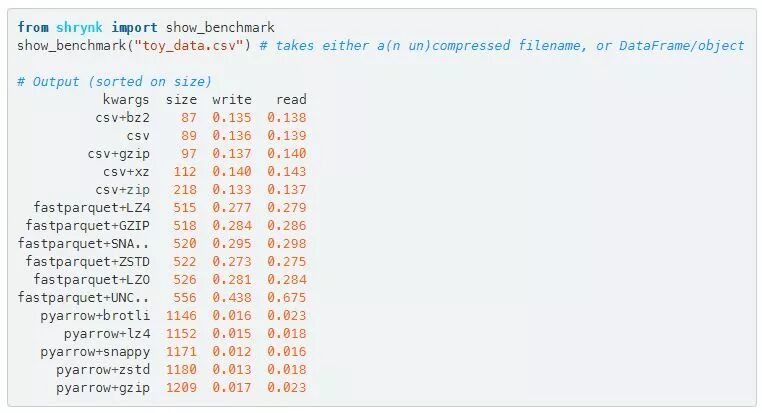
在这个文件的例子中,你可以看到这个过程,我建议你将数据存储为csv+bz2,因为它在磁盘上会生成一个非常小的文件(并且它会使用默认设置)。
在我的笔记本电脑上运行所有的压缩基准测试只需要3秒钟,这可能会让你好奇为什么我们不能不断地运行基准测试呢?对于任何规模较大的dataframe,你不希望必须去运行基准测试,因为这可能需要很长时间—特别是对于一个不幸的压缩算法,它需要很长时间来处理手头的特定数据。同时,既然我们可以预测,为什么还要运行基准呢?进入机器学习。
机器学习
计算机擅长于自动化人类的决策。为了在不需要显式地对其进行编程的情况下进行决策,它将会利用历史数据(如特征和实际决策)来预测未来新特征的最佳决策。
例如,机器学习可以基于用户过去已经标记的大量要么是垃圾邮件要么不是垃圾邮件的其他邮件(决策)来帮助我们决定一个新的电子邮件是否是垃圾邮件,并使用频繁出现在垃圾邮件中(例如“Nigerian Prince”)或非垃圾邮件中(例如“Hi John”)的单词(它们的特征)来驱动决策。好吧,假设那个人的名字实际上是John,当然,否则的话它可能又是垃圾邮件。
机器学习通常的缺点是收集正确的决策是非常昂贵的——它通常是由人们的手工劳动完成。
机器学习对压缩来说的最酷之处在于,我们可以尝试对一个文件进行所有的压缩,从而找出最优的决策是什么,而不需要花费太多的成本(除了时间)。
在这种情况下,~3000个文件被用来进行压缩建模。它们的特征都被记录下来了,我们要学着尽量减少的事情有:
它们会变多大 (在磁盘上的size),
一次写入需要多长时间 (write time) 和
一次读取需要多长时间 (read time)
这个过程可能是,基于一些数据,比如5000行和10列的价格数据,压缩A的大小是最好的,但如果它涉及到500行和100列的时间数据时,压缩B是最好的。这也可能取决于其他因素,例如文本列的数量,情况将再次不同。
为了提供更多的示例特性,目前它将考虑percentage of null values(空值百分比)、average string length(平均字符串长度)和变量的不同程度(cardinality),甚至更多。这些都是用来确定在一个类似的上下文中应用哪种压缩的。点击这里查看使用的特性概述。
使用Shrynk进行机器学习
请注意,还有其他使用机器学习来进行压缩的尝试,尤其是在压缩图像方面。Shrynk使用一个元方法来代替,因为它只使用现有的压缩方法。
对于每个文件,它将应用压缩并收集每个压缩算法关于大小、写入列和读取列的值,并将它们转换为z分数:这使它们在每个维度上都具有可比性,据我所知,这是一种新颖的方法。给定用户权重的z分数的最小和会作为一个分类标签被选择。我们来看看慢动作。
首先看看转换成z分数是如何进行的:

你可以看到,规模并不重要,但相对差异却很重要:(1,2,3)和(100,200,300)得到了相同的分数,尽管它们要大100倍。还要注意,这里我们忽略了单位(字节vs秒)。
这里是一个虚构的例子,显示了一个想象的文件的3个压缩分数,并且只考虑大小和写入:

将每列转换成Z分数:

然后将z分数与用户权重相乘(Size=1, Write=2):

在最后一列中,你可以看到行数的总和,以获得每个压缩的加权z分数。
给定示例数据s=1和w=2,compression B的z分数之和最低,因此是最好的!这意味着该数据的特征(如num_rows等)和标签compression B将被用于训练分类模型。
最后,每个文件的输入将是这个结果(因此,样本大小为number_of_files,不是number_of_files * number_of_compression)。
一个样本数据集可能看起来像这样(完全编造的):

基于用户权重,一个简单的RandomForestClassifier将在包含3000个文件的基准数据上进行训练。
了解了这一点,让我们来看一些用法示例。
用法
保存(预测最佳类型)和加载的基本示例:

如果你只是想要预测,你也可以使用infer:

为了获得更好的控制,你可以直接使用shrynk类:
安装之后,你也可以通过shrynk命令使用它。
使用它自动对文件进行压缩、解压和运行基准测试:

自带数据
注意,数据是自带在shrynk中的:这是一个特性,而不是一个bug。它允许人们提供自己对大小、写和读速度的要求。然后它会立即训练一个模型(如果没有提前训练的话)。
我也希望包括数据可以鼓励其他人看看他们是否可以提高压缩分数:)
你还可以使用它来验证对算法的改进,或通常的方法。
它的效果如何?交叉验证
我已经内置了一个validate函数,所有的shrynk类都可以使用这个函数,这样你就可以测试自己的策略,或者在自己的数据上进行训练并验证结果。
它会对给定的类使用可用的数据,并产生用于交叉验证的结果;同时会考虑用户定义的权重。
验证是一个艰难的过程,主要是因为我花了一段时间才弄明白,在允许使用权重时,如何用一种有意义的方式来表达结果。最后,我选择保留感兴趣的维度,即 size、 read和write,并显示shrynk对每个对象的预测的总和(按比例)与选择始终使用单一策略进行比较。我希望这个例子能说明问题。
参见下面的代码:

注意,在下面的例子中,shrynk不仅在大小上(查看箭头处)要好31%,而且在读写时间上也比总是应用最佳策略csv+xz好得多。1.001值表示它只偏离了如果它总是为验证集中每个文件选择最好的压缩时获得的大小效果的0.1%。与此同时,它与总是选择最佳压缩时的读取时间相比要慢6.653倍。毕竟这是对大小的优化。
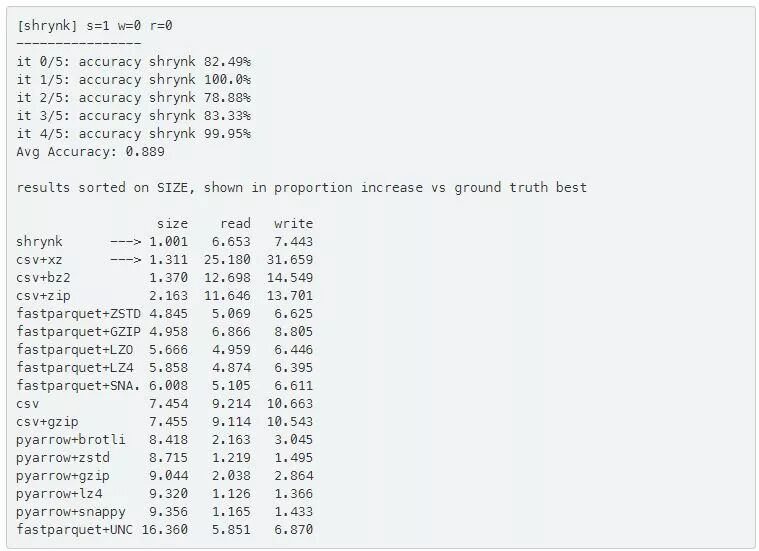
最后,让我们看看size=3和write=1的用户权重时的一个混合方法:
结论
由于我们必须为何时使用哪个压缩而提出一些手工规则,这将非常复杂,并且花费时间,所以这是机器学习的一个很好的例子。它的可扩展性很强,当一种新的压缩算法出现在市场上时,shrynk将能够对该算法进行基准测试,而无需制定新的规则。
注意,与只使用单一最佳策略相比,它当前需要的磁盘少了30%(实际上,你甚至可能不会总是使用单一最佳策略,而是会使用更糟糕的策略)。当然,这是在相当异构的数据上来说的:小的、大的以及非常通用的,例如文本和缺失字符。为了防止偏差,它是在将所有压缩算法的出现平衡到最佳的情况下进行训练的。
当你能够以低廉的成本获取(甚至创建)数据时,你就已经知道自己在机器学习领域将取得胜利。
它还演示了一种增强编码的绝妙方法:让计算机去预测“做某事”的最佳方法——在本例中是压缩。
下一步
如果你喜欢这个项目,可以随时在github上关注我,并在github上为shrynk留下一颗星星。
如果你还没有尝试过它,你可以在https://shrynk.ai看到它的实际效果
如果你对此感兴趣,请帮忙改进,我们欢迎任何尝试性的合并请求:这是一个python项目,由社区提供,为社区服务。
进一步研究哪些变量最具预测性(且计算成本低)
一旦我们进一步研究了哪些特征是最成功的,统计数据的计算过程可能也会加快。
向框架添加其他的数据类型(最近已经添加了JSON和Bytes)
我一直在开发一个生成人工数据的包。想象一下,根据需求或者现有的数据框架创建一些细微的变化,让数据朝着我们希望更好地了解边界的方向发展!
其他改进?
英文原文:https://vks.ai/2019-12-05-shrynk-using-machine-learning-to-learn-how-to-compress
译者:好酒不上头








