
之前分别介绍了机器学习概要、数据预处理以及模型调参。本次重点介绍模型训练与集成。
继续回到之前提到的相亲的数据,在实际业务开展时,发现相亲失败时不仅客户会心情低落,对于组织相亲的人来说,也会很难过。那么是否可以提升模型预测的精确度,增加相亲成功率呢?
逻辑回归可以说是最基础的分类模型,它度量的是Y=1的可能性。对于逻辑回归的原理和实现,本书第三章已经有所介绍。图1为经典逻辑回归的一个例子,自变量包括5个,因变量为“是否女神”。逻辑回归模型利用训练集对不同的自变量赋予不同的权重,这些自变量线性组合得到z。z通过logit函数转换,就得到了“女神的概率”。
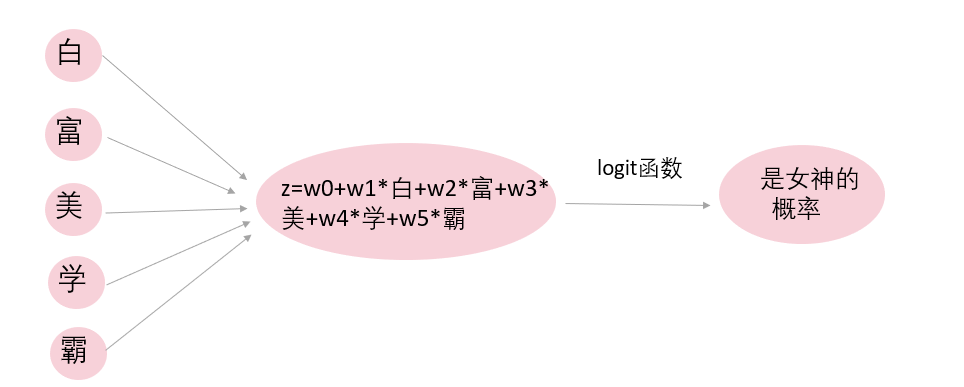
图1 逻辑回归
那么,在caret包中如何实现逻辑回归呢?代码只要3行即可,如下所示:

决策树是机器学习中常用的基础树模型。前面介绍了一个如何判断是否为女神的例子,下面就利用决策树来介绍一个男生追女神的故事(见图2)。首先判断女生是不是女神,如果是,则看女神是否单身。对于单身女神,又可以分为喜欢我的和不喜欢我的。对于喜欢我的单身女神,果断选择追,其他情况下都选择不追。这就是决策树模型的最终输出呈现。
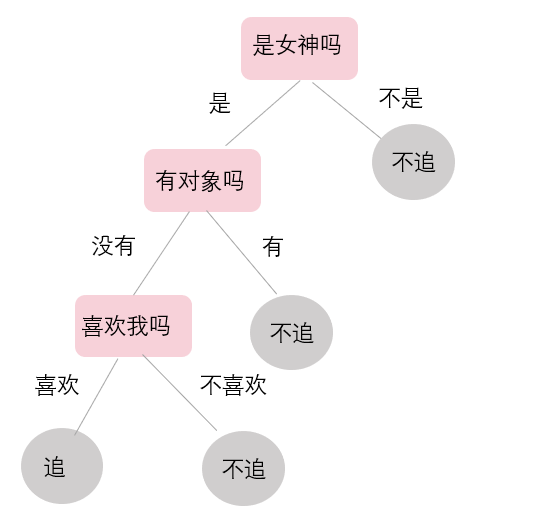
图2 决策树示例
那么,在caret包中如何实现决策树呢?在method中设置参数为”rpart”即可。

随机森林是通过将多棵决策树集成的一种算法,它的基本单元为决策树。图3为随机森林建模的步骤,这里依然沿用男生追女神的例子。
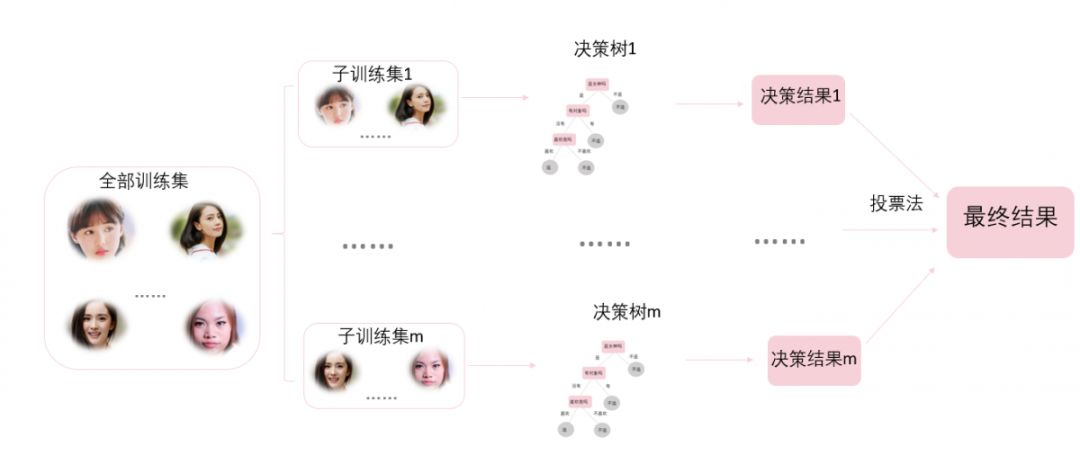
图3 随机森林
首先,从训练样本中重抽样m组样本,每组样本都是一个子训练集;然后,对每个子训练集样本都构造出一棵决策树,每棵树都有一个决策结果。最后,使用投票法决定最终输出结果。N棵树会有N个分类结果,根据“少数服从多数”原则,投票次数最多的类别为最终的输出。
比如现在有3棵决策树:一棵树认为追女神A,两棵树认为不追女神A,那么根据投票法,到底追不追女神A呢?
那么,在caret包中如何实现随机森林呢?只需要在method中设置为”rf”(random forest的缩写),就可以了。

一个分类器学习可能会犯错,但是多个分类器一起学习可能会取长补短,这是模型集成的思想,一句话概括就是“三个臭皮匠顶个诸葛亮”。
常用的模型集成方法分为投票法、平均法和堆叠集成。其中投票法适用于分类问题,平均法适用于回归问题。其中,平均法的结果由几个分类器的结果平均而得,可以采用简单平均和加权平均。
1.投票法
投票法的思想是“少数服从多数”,“群众的眼光是雪亮的”。和随机森林的思路很像,只是这里的分类器可以是不同的分类器,不仅仅是决策树(见图4)。假设分类器1认为杨幂是女神,分类器2认为杨幂是女神,分类器3认为杨幂不是女神。那么最后这3个分类器经过开会投票表决,决定最终结果为杨幂是女神。这就是投票法的思想。
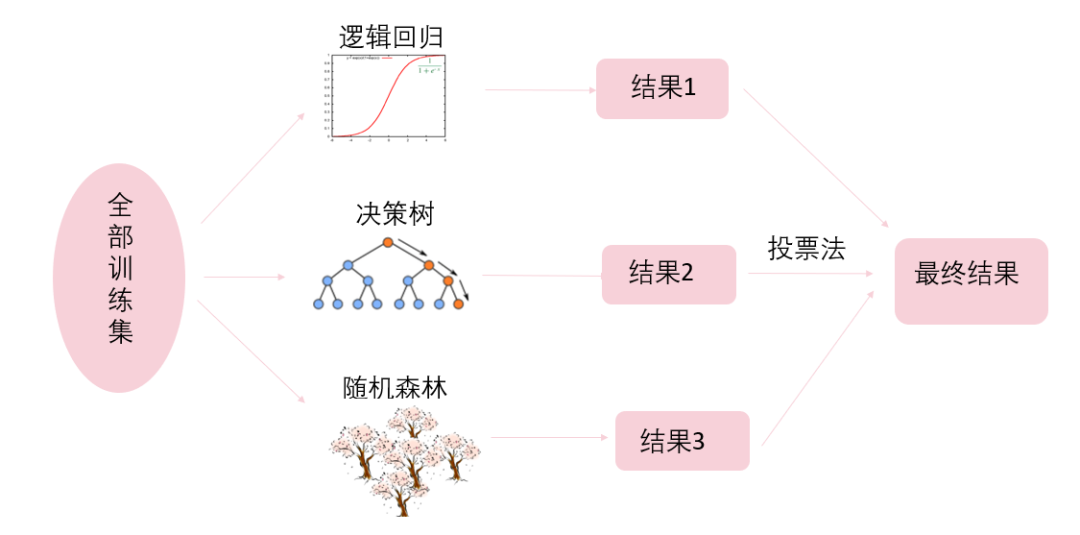
图4 投票法
那么在R中如何实现呢?

首先将几个分类器得到的结果整合在一个数据框中,然后对每行样本都进行投票表决,得到最终结果。但问题是,投票法得到的预测精度还不如随机森林,为什么呢?
这里预测精度降低的原因很简单,就是有个别分类器在拉后腿。所以需要更有效的方式来进行模型集成,即堆叠集成法。
2.堆叠法
堆叠集成思路是,首先利用机器学习的不同模型得到不同预测结果,不同模型得到的预测结果就像组装前的零部件。然后将预测结果作为自变量输入模型进行拟合,也就是将这些零部件组装在一起,而如何组装就取决于不同的模型了(见图5)。
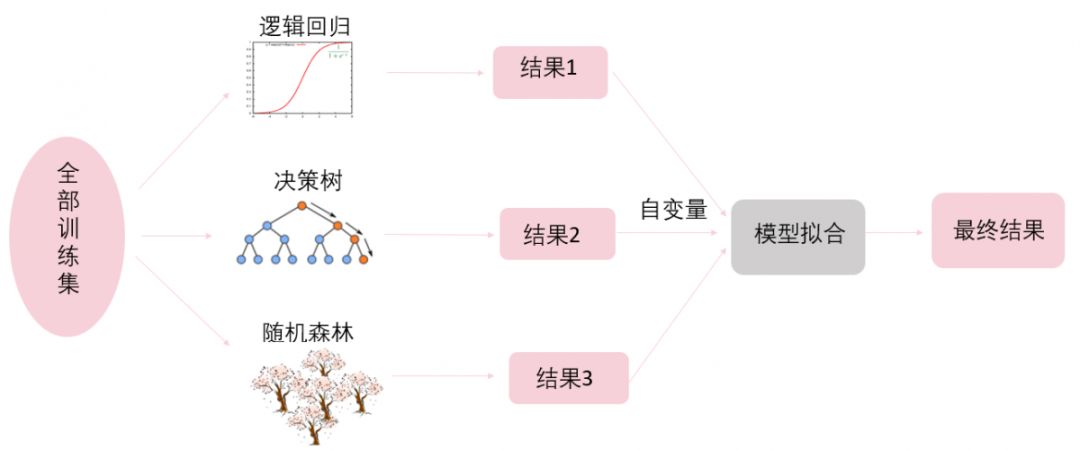
图5 堆叠法
那么在R中如何实现呢?首先将各个模型得到的分类结果及真实的分类组合成一个数据框;然后将各个模型的分类结果作为自变量,真实的分类作为因变量,利用模型进行拟合预测。这里,在组装这个阶段利用随机森林模型。

3.AdaBoost
AdaBoost算法的核心思想是:区别对待不同训练样本。首先,秉承“人人平等”的原则,对所有训练样本都赋予相等的权重。然后,对每个训练样本都进行训练,得到训练精度。秉承“帮助弱者”的原则,对训练精度低的样本赋予更大的权重,让模型能更注意提高这部分样本的训练精度。最后,将各个样本训练出来的结果进行加权投票或加权平均。

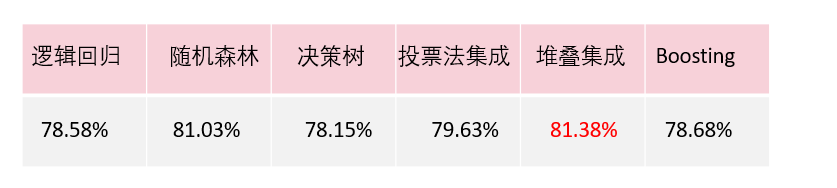
最后,用表1来总结一下本节用到的模型及模型集成的预测精度。可以看出,堆叠集成法是提高预测精度的利器。
表1 不同算法的预测精度对比
本章从实例分析的角度介绍了简单机器学习方法的概述和实现,对于原理等本章并没有过多涉及,感兴趣的朋友可以阅读机器学习相关的经典教材。机器学习是一件“利器”,往往能够在预测问题中出奇制胜。希望读者能够在实践环境中多多练手,积累实战经验。
请扫描以下二维码/点击链接购买
《R语言:从数据思维到数据实战》


https://detail.tmall.com/item.htm?spm=a220z.1000880.0.0.0A6pvS&id=581845865737










