人工智能越来越火,甚至成了日常生活无处不在的要素。人工智能是什么?深度学习、机器学习又与人工智能有什么关系?作为开发者如何进入人工智能领域?近期我们将连载一个深度学习专题,由百度深度学习技术平台部主任架构师毕然分享,让你快速入门深度学习,参与到人工智能浪潮中。
- 人工智能、机器学习、深度学习三者的关系,并简要介绍了深度学习的发展历史以及未来趋势。
- 介绍构建深度模型的五个步骤,并使用Numpy实现神经网络。
- 原理介绍和代码实践并行,详细介绍了使用Numpy实现梯度下降算法。
- 为什么那么多人看好深度学习,其未来的发展趋势是什么?
首先对第一个问题,以人工智能、机器学习、深度学习三者的关系开始。三者覆盖的技术范畴是逐层递减的,人工智能是最宽泛的概念,机器学习则是实现人工智能的一种方式,也是目前较有效的方式。深度学习是机器学习算法中最热的一个分支,在近些年取得了显著的进展,并代替了多数传统机器学习算法。所以,三者的关系可用下图表示,人工智能 > 机器学习 > 深度学习。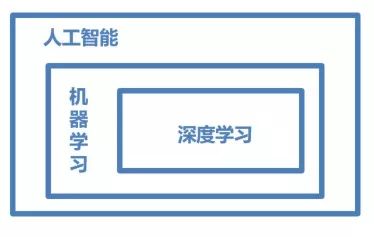
图1:人工智能、机器学习和深度学习三者之间的概念范围举例类比,机器如一个机械的学生一样,只能通过尝试答对(最小化损失)大量的习题(已知样本)来学习知识(模型参数w),期望用学习到的知识w组成完整的模型,能回答不知道答案的考试题(未知样本)。最小化损失是模型的优化目标,实现损失最小化的方法称为优化算法,也称为寻解算法(找到使得损失函数最小的参数解)。参数和输入X组成公式的基本结构称为假设。在中学期间,倾斜滑动法计算重力加速度时,基于对物体重量和作用力数据的观测,我们提出的是线性假设,即作用力和加速度是线性关系。牛顿第二定律的验证过程也是机器学习的参数确定过程。由此可见,模型假设,评价函数(损失/优化目标)和优化算法是构成一个模型的三个部分。 关于第三个问题。在深度学习框架出现之前,机器学习工程师处于手工业作坊生产的时代。为了完成建模,工程师需要储备大量数学知识,并为特征工程工作积累大量行业知识。每个模型是极其个性化的,建模者如同手工业者一样,将自己的积累形成模型的“个性化签名”。
关于第三个问题。在深度学习框架出现之前,机器学习工程师处于手工业作坊生产的时代。为了完成建模,工程师需要储备大量数学知识,并为特征工程工作积累大量行业知识。每个模型是极其个性化的,建模者如同手工业者一样,将自己的积累形成模型的“个性化签名”。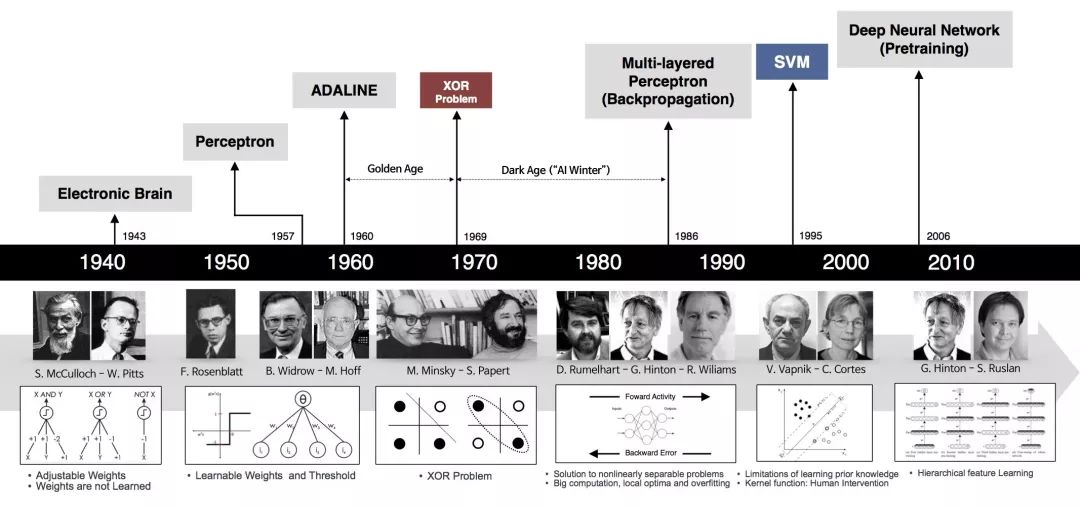
图3:深度学习有悠久的发展历史,但在2010年后才逐渐成熟。
而今,“深度学习工程师”进入了工业化大生产时代。只要掌握深度学习必要但少量的理论知识,掌握Python编程即可以在深度学习框架实现极其有效的模型,甚至与该领域最领先的实现模型不相上下。建模这个被“老科学家”们长期把持的建模领域面临着颠覆,也是新入行者的机遇。
实践出真知,理论知识说得天花乱坠也不如多写几行代码,接下来将介绍使用Numpy构建神经网络、实现梯度下降的具体方法。本次实验实现波士顿房价预测的回归模型。应用于不同场景的深度学习模型具备一定的通用性,均分为五个步骤来完成模型的构建和训练,使用Numpy实现神经网络也不外乎如此,步骤如下:- 数据处理:从本地文件或网络地址读取数据,并做预处理操作,如校验数据的正确性等。
- 模型设计:完成网络结构的设计(模型要素1),相当于模型的假设空间,即模型能够表达的关系集合。
- 训练配置:设定模型采用的寻解算法(模型要素2),即优化器,并指定计算资源。
- 训练过程:循环调用训练过程,每轮均包括前向计算 、损失函数(优化目标,模型要素3)和后向传播这三个步骤。
下面使用Python编写预测波士顿房价的模型,一样遵循这样的五个步骤。正是由于这个建模和训练的过程存在通用性,即不同的模型仅仅在模型三要素上不同,而五个步骤中的其它部分保持一致,深度学习框架才有用武之地。首先进行数据处理,完成数据集划分、数据归一化,以及构建数据读取生成器。代码如下:def load_data(): datafile = './work/housing.data' data = np.fromfile(datafile, sep=' ')
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ] feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num])
ratio = 0.8 offset = int(data.shape[0] * ratio) training_data = data[:offset]
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \ training_data.sum(axis=0) / training_data.shape[0]
for i in range(feature_num): data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
training_data = data[:offset] test_data = data[offset:]return training_data, test_data
构建神经网络
将波士顿房价预测输出的过程以“类和对象”的方式来描述,实现的方案如下所示。类成员变量有参数 w 和 b,并写了一个forward函数(代表“前向计算”)完成上述从特征和参数到输出预测值的计算过程。 def __init__(self, num_of_weights): self.w = np.random.randn(num_of_weights, 1) z = np.dot(x, self.w) + self.b
目前已经实现了房价预测模型的前向过程,但是如何知道预测的结果呢,假设预测值为而真是房价为,这时我们需要有某种指标来衡量预测值跟真实值之间的差距。
对于回归问题,最常采用的衡量方法是使用均方误差作为评价模型好坏的指标,具体定义如下:上式中的(简记为: ) 通常也被称作损失函数,它是衡量模型好坏的指标,在回归问题中均方误差是一种比较常见的形式。由于实现的房价预测模型的权重是随机初始化的,这个权重参数处在模型极小值的概率几乎为0,我们需要使用梯度下降算法不断更新权重,直到该权重处于模型的极小值或最小值附近。
前文已提到,构建机器学习模型的首要是从一个假设空间,构建算法,去达到这个假设空间的最优值。以下图为例,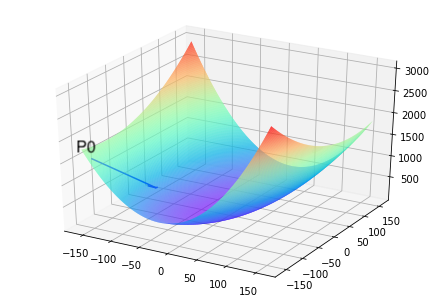
从随机初始化的点达到坡底(最优值)的过程,特别类似于一位想从山峰走到坡谷的盲人,他看不见坡谷在哪(无法逆向求解出Loss导数为0时的参数值),但可以伸脚探索身边的坡度(当前点的导数值,也称为梯度)。那么,求解Loss函数最小值可以“从当前的参数取值,一步步的按照下坡的方向下降,直到走到最低点”实现。现在我们要找出一组的值,使得损失函数最小,实现梯度下降法的方案如下:上面我们讲过了损失函数的计算方法,公式定义损失函数如下:从导数的计算过程可以看出,因子被消掉了,这是因为二次函数求导的时候会产生因子,这也是我们将损失函数改写的原因则可以在Network类中定义如下的梯度计算函数。
借助于Numpy里面的矩阵操作,我们可以直接对所有 一次性的计算出13个参数所对应的梯度来。公式看不懂没关系。且看下述代码如何实现梯度计算,网络训练和参数更新。def gradient(self, x, y): z = self.forward(x) gradient_w = (z-y)*x gradient_w = np.mean(gradient_w, axis=0) gradient_w = gradient_w[:, np.newaxis] gradient_b = (z - y) gradient_b = np.mean(gradient_b) return gradient_w, gradient_b
def update(self, graident_w5, gradient_w9, eta=0.01): net.w[5] = net.w[5] - eta * gradient_w5 net.w[9] = net.w[9] - eta * gradient_w9
def train(self, x, y, iterations=100, eta=0.01): points = [] losses = [] for i in range(iterations): points.append([net.w[5][0], net.w[9][0]]) z = self.forward(x) L = self.loss(z, y) gradient_w, gradient_b = self.gradient(x, y)
gradient_w5 = gradient_w[5][0] gradient_w9 = gradient_w[9][0] self.update(gradient_w5, gradient_w9, eta) losses.append(L) if i % 50 == 0: print('iter {}, point {}, loss {}'.format(i, [net.w[5][0], net.w[9][0]], L)) return points, losses
运行代码后,从下面这个图里可以清晰的看到损失函数的下降过程。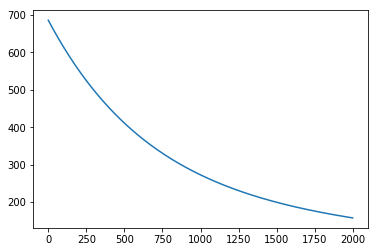
总结一下,本文以机器学习深度学习概述开篇,讲解了深度学习的基础知识,通过使用Numpy实现房价预测模型,详细讲解了构建深度学习模型的五个步骤,以及梯度下降的基本原理、如何使用Numpy实现梯度下降等内容,希望对你入门深度学习有帮助。










