| 本文作者:陈俊熹,腾讯云数据库研发工程师,主要负责腾讯云MySQL数据库研发工作。
Innodb存储引擎是目前MySQL最主流的存储引擎,学习Innodb, 可以先从其最基础的数据结构开始。Innodb的数据结构主要包括内存数据结构(In-MemoryStructures),如buffer pool, change buffer, log buffer等, 磁盘数据结构(On-DiskStructures),如索引Index, 表空间及日志结构等。
Buffer Pool
Buffer Pool主要是对Innodb存储引擎中的数据表(Table)和索引数据(Index)的一个缓存,它使得MySQL可以直接对一些热数据在内存中进行读取。Innodb BufferPool的作用和操作系统中的Page Cache类似,作为缓存子系统,它们在设计和实现上有很多类似的地方。比如,Buffer Pool也使用page作为管理数据页的最小基本单元,同时使用链表来管理内存页,并且页框的淘汰回收算法都使用了LRU。不同的地方在于,Linux的页框回收算法中使用inactive和active两个链表来管理数据页pages,而在Innodb中,所有的数据页pages都在一个链表上,它通过一个中间点(MidPoint)指针将链表分为“new”和“old”两个子链表。
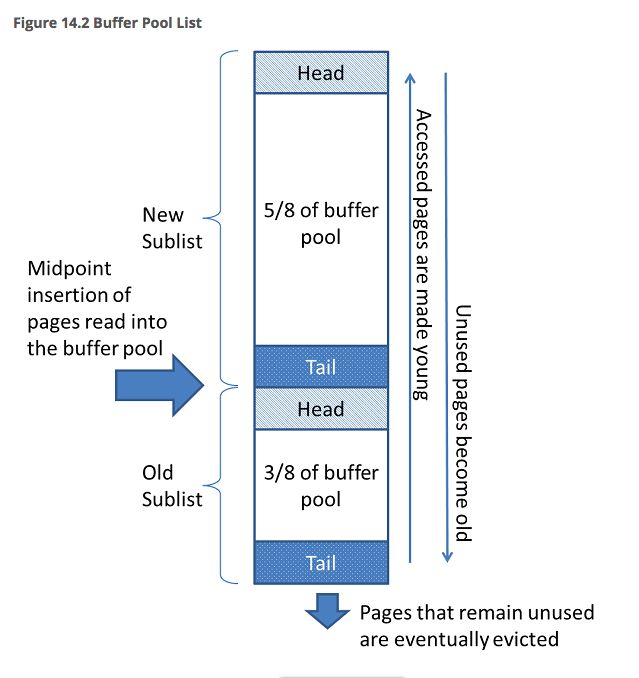
Buffer Pool链表结构
如上图所示,当数据页第一次被访问读入内存时,它被插入到MidPoint的位置,也就是“old”子链表的头部。通常来说,数据页被读入内存可能是因为一个query操作,或者是Innodb的预读操作。一个数据页如果是因为query操作被读入内存的,则它会被移动到整个链表的头部。有的数据页是被预读进来的,它不一定会立即被访问,此时它会一直存在于“old”链表内,直到它被淘汰。基于LRU的淘汰策略都存在一个瞬时访问命中率下降的问题。例如,MySQL在进行全表扫描时,会将大量的数据页读入内存,这些数据页几乎都不会再被上层查询所使用,因此又会快速的成为“old” pages被淘汰出内存。所以全表扫描的开销非常大,并且会污染Buffer Pool中的热数据。Innodb提供了一些设置来缓解这种情况。首先,你可以通过设置参数“innodb_old_blocks_pct”来控制LRU链表中“old” pages的比例,其默认值是37,即有3/8的内存数据页会作为淘汰算法的候选页。“innodb_old_blocks_pct”的可设置范围为[5, 95],将该参数设成一个较小值,可以减轻全表扫描对内存热数据的影响,此时Buffer Pool中只有很少一部分空间会进行淘汰,而真正的热数据会被一直保留。另外一个参数“innodb_old_blocks_time”设置了一个时间窗,来规定一个数据页被插入到MidPoint之后,在多少时间后可以被移动到“new”子链表头部。例如,将“innodb_old_blocks_time”值设置为1000ms(即1s),那么一个数据页被读入内存后,它在1s内无论被访问多少次,也不会成为热数据页。这个参数值可以缓解全表扫描引入的缓存污染问题。比如像全表扫描或预读load进内存的数据页,它们在很短一段时间内被访问后就不会再被访问了,那么此时他们仍然在“old”链表中,可以更快速的被淘汰出内存。Change Buffer使用了Buffer Pool的一部分空间,它主要对部分不在Buffer Pool中的数据页的写操作(包括插入,更新和删除)进行缓存。通常来说,Innodb所更新的一个数据页不在Buffer Pool中时,需要将数据页读入内存再进行更新操作,但是这会带来额外的IO开销。使用Change Buffer可以将这部分更新操作先进行缓存,当下次读入这些数据页时,更新操作会merge到数据页上。也有可能系统没有访问这些数据页,此时Change Buffer中的更新操作会被系统定期的sync到磁盘。
值得注意的是,Change Buffer只缓存对二级索引的更新操作。因为相较于主键索引的连续有序且唯一性,二级索引通常是不唯一的,且更新二级索引会有大量的随机IO操作,这对系统性能的影响很大,因此对这部分更新操作进行缓存的收益更加明显。另外一个需要关注的问题是Change Buffer中的操作是如何持久化。在Innodb中,Change Buffer的更新操作和普通数据的更新操作类似,也会写redo log。最开始Change Buffer使用的是系统表空间,当数据页读入内存并进行merge操作后,系统会记录该数据页redo log并将其标记为脏页,该数据页的变更会被刷回磁盘。因此,Buffer Pool中的更新操作最终都会持久化到磁盘中。Redo Log日志文件也需要相应的内存数据结构来进行缓存操作。Log Buffer就是用于缓存日志文件的内存空间,其空间大小可以通过数“innodb_log_buffer_size”来设定。通常来说,日志文件的每次更新都应该刷会磁盘,不然就会有数据丢失或不一致的风险。“innodb_flush_log_at_trx_commit”参数用于设置日志刷回磁盘的频率,其默认值为1,即每次事务提交时,都会记录日志,并将其刷回到磁盘。该参数值为0时,日志写入和刷回磁盘的操作为每秒1次;该参数值为2时,每次事务提交时都会写入Log Buffer,但Log Buffer更新到磁盘的操作为每秒1次。
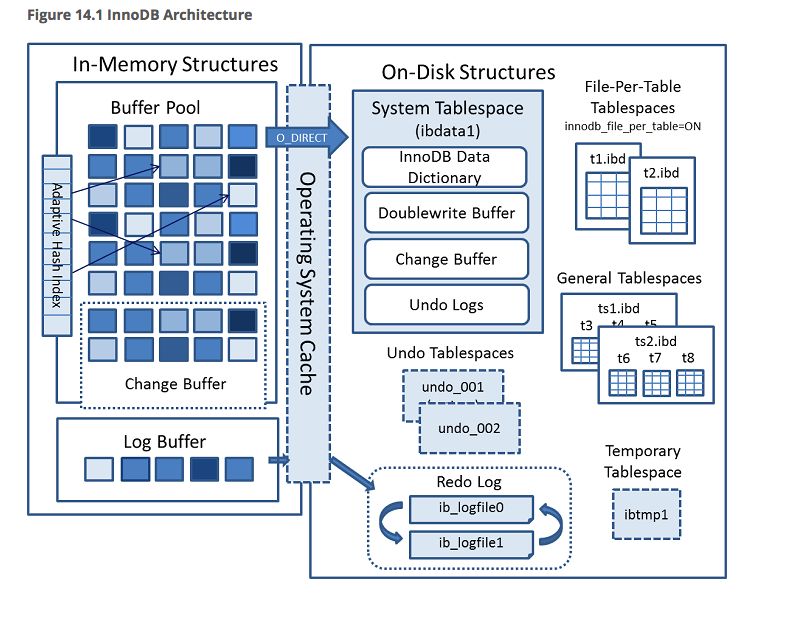
Innodb系统架构
上图是Innodb内存数据和磁盘数据结构的示意图,左边就是本文主要学习的内存数据结构。之前也提到,Buffer Pool在Innodb中的作用类似于操作系统中的Page Cache,在图中也可以看到,Buffer Pool绕过了系统缓存,通过O_DIRECT方式来读写数据。所以对Buffer Pool的管理,相当于是Innodb为数据库这种存储系统设计的缓存管理。而Log Buffer并没有使用Buffer Pool的空间,使用的是系统缓存。本文简要描述了Innodb Buffer Pool, Change Buffer, LogBuffer这三种内存数据结构,作为记录Innodb存储引擎的开篇内容相对基础,有疑问或感悟欢迎在留言区讨论。
叶老师新课程《MySQL性能优化》已经在腾讯课堂发布,本课程讲解读几个MySQL性能优化的核心要素:合理利用索引,降低锁影响,提高事务并发度。下面是报名小程序码,厚着脸皮请求大家推荐给需要的小伙伴们。

下面是本课程内容目录
点“在看”给我一朵小黄花





