
全网TOP量化自媒体
公众号决定从2020年7月开始,每周一将推出一期有关全球对冲基金、量化投研、金融机器学习、机构招聘等方面的周刊。为大家带来最新、最前沿的投研、资讯内容,希望各位读者能够喜欢。

欢迎大家多提意见,我们完善到最优。
今天这篇文章来自一家量化交易公司的某位研究员。他们试图通过大规模的机器学习技术来发现新颖的中频交易策略。
今天这位研究员来为大家分享一些他在工作中遇到的问题,仅供大家参考。
在这里,我们列举一些金融数据方面的挑战,以及为什么用机器学习建模会如此困难。
1、低信噪比
2、特征向量非独立性
3、标准损失函数不适合交易目标
4、机会的稀疏性(对于某些策略)
5、非平稳性
6、数据缺乏
假设我们想用机器学习来创建一个只做多的模型,来预测5天的收益率否大于某个最小收益率(比如50bps)。
1、创建标签,识别交易机会
我们将标记:
5天收益率>= 50bps with 1 和 < 50bps with 0
2、为模型创建特征
请注意,我们并不主张使用技术指标,下面的特征只是为了说明,并不是有意选择的。
3、训练模型
4、评估
5、完整代码
bars = getOHLC ("SPY")
close = bars["Adj Close"].values.flatten()
# 创建特征
df = bars.copy()
df["rsi"] = talib.RSI(close, timeperiod=14)
df["roc5"] = talib.ROC(close, timeperiod=5)
...
# 创建 { 0, 1 } 标签, where 1 means 5 day return >= 50bps
df["label"] = (df["roc5"].shift(-5) >= 0.50) * 1.0
# 特征的columns
features = ["rsi", "roc1", "roc5", "roc10", "roc20", "oc", "hl"]
# 数据集分割
icut = int(df.shape[0] * 0.70)
training = df.iloc[:icut].dropna()
testing = df.iloc[icut:].dropna()
# 训练模型&特征
clf = RandomForestClassifier(n_estimators=500, random_state=1, n_jobs=-1)
model = clf.fit (training[features], training.label)
#分别用模型对训练集和测试集的标签进行预测
pred_train = model.predict(training[features])
pred_test = model.predict(testing[features])
现在让我们看一下用于通过我们训练的模型进行训练和测试的混淆矩阵。对于交易,我们希望最大化TP(true-positive,盈利的交易)和最小化FP(false positives,亏损的交易):
在交易方面,我们不太关心TN(true negative)和FN(false negative)。false negative意味着错过了机会,但是没有损失。
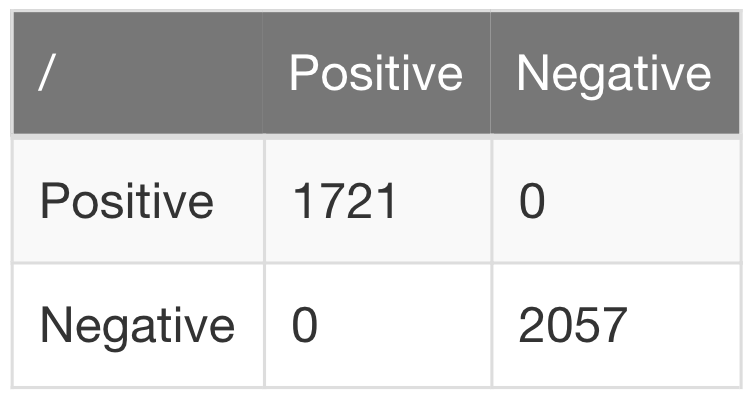
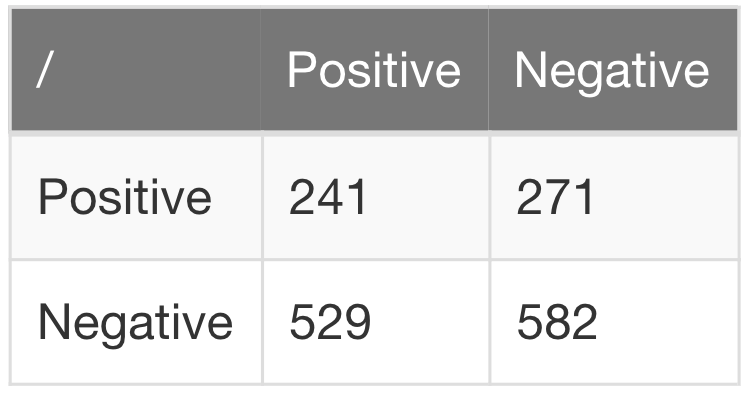
现在,让我们根据训练数据和测试数据来评估模型的混淆矩阵。我们希望样本外的测试数据能够提供类似于训练的准确性,并且TP与FP的比值较高。
confusion_matrix(training.label, pred_train)
confusion_matrix(testing.label, pred_test)
结果表明,我们的训练周期有一个完美的契合(FN=0和FP=0)。这是一个很明显的过拟迹象:
而且在样本外测试中,损失的精度很差:
上面的例子说明了我们将在后续文章中讨论的一些问题:
1、标签有噪声
2、特征是嘈杂的
3、样本不是独立的
我们的特征集中的每一行都不是独立于相邻的行。最长的特征有一个20bar的lookback窗口。因此,每个特征行将与其他40个特征重叠(20个在过去+20个在未来)。许多机器学习算法由于非独立性而利用了信息泄露模型,在训练中产生了一个过拟合模型。
4、错误的损失目标
我们倾向于优化TP和FP(精度)之间的平衡,而不是平衡精度和召回率。
在后续的文章中,我们会更深入地讨论这些问题,并提出一些可以对算法、数据集等改进的方案。
量化投资与机器学习微信公众号,是业内垂直于Quant、MFE、Fintech、AI、ML等领域的量化类主流自媒体。公众号拥有来自公募、私募、券商、期货、银行、保险资管、海外等众多圈内18W+关注者。每日发布行业前沿研究成果和最新量化资讯。











