
来源:混沌巡洋舰
灾难性遗忘指的是:不像人类,当深度学习模型被训练完成新的任务时,他们很快就会忘记以前学过的东西。8月13号的自然通讯论文Brain-inspired replay for continual learning with artificial neural networks,介绍了如何通过在模拟大脑中的“回放”机制,解决该问题。
灾难性的遗忘出现,并不是由于网络容量有限,为了完成新任务(区分牛和羊),不得不忘记旧任务(区分猫和狗)。同样的网络可以学习如果单独训练,可以完成新旧两类任务(区分猫和牛)。然而,在现实世界中,训练样本并没有交错出现,而是先呈现任务A,再呈现任务B的训练样本。
如果能够存储以前遇到的示例,并在学习新东西时重新访问它们。那就能够避免灾难性遗忘。然而这种解决方案,在大数据集上的可扩展性受到了质疑,因为不断重新训练所有以前学过的任务是非常低效的,而且需要存储的数据量会变得无法快速管理。
在大脑中,一种被认为对维持记忆很重要的机制是:代表这些记忆的神经元活动模式会被重新激活,这被认为对于稳定新的记忆非常重要。大脑显然已经实现了一种高效且可扩展的持续学习算法。这种记忆回放由海马体调控,一般发生在刚刚睡眠和即将醒来的时间段。
在人工神经网络中,类似的记忆回放可以被称为“生成性回放”,本文提出的,正是这样一种受大脑启发,改进后回放机制,使训练数据中内部被隐藏的特征,而不是数据本身被回放(重复训练)。被回放的表征是由网络自身的、上下文调制的反馈连接生成的。

传统的回放以及本文提出的基于生成模型的回放
上图中左边为传统的回放机制,即在训练神经网络做新的分类任务时,在训练数据中随机加入之前任务的训练数据;而右图代表的生成式的回放机制,即随机加入的,不是原有的训练数据,而是由生成器(另一个训练好的神经网络)产生的代表了原训练数据特征的数据。
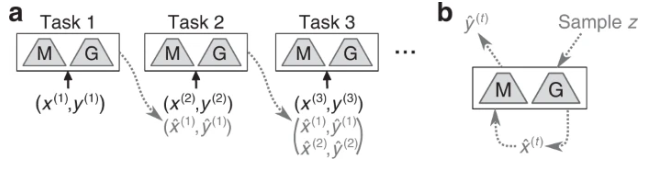
具体的训练过程,如上图所示。在任务1时,训练一个分类模型M,一个生成模型G(例如变分自编码器),之后训练任务2时,训练数据在原本的数据集之外,加上了随机抽样产生的包含任务1特征的模拟数据,以及前一步生成器产生的对数据的标签,依次类推。
之所以生成式的模型能够应对大数据量,是由于生成模型产生的回放数据,不需要有原数据集那么高的像素,且为避免灾难性遗忘的出现,所需的训练数据的样本数也少于使用用原数据进行回放,从而减少了计算量。而这背后的根本原因,在于生成的数据已经对数据特征进行了提取,因此其能够用更少的数据,训练分类模型区分前一任务所需提取的模式。

本文还在基础版的生成式回放基础上,提出了几项改进方案。首先是让生成器和分类器共用最初的特征提取层,从而在生成器和分类器之间,建立起双向的反馈,图中的橙色部分,可以看成是VAE的输出,经过了softmax分类得到的标签,被当成回放数据集用于之后训练。这项改进模仿了大脑的结构,大脑中,负责回放的海马体会将信号传给脑特征提取的皮质。

第二项改进是针对每一类数据,分别训练一种生成模型,从而可以根据特定条件,选择不同类型的数据回放。具体的做法是,将生成器的输入的输入,由一个从标准正态分布中的随机抽样,变成数据聚类后,每一类数据对应的高斯分布中进行抽样。

第三项改进,为了避免生成的数据,带有原训练数据中背景所对应的偏差,从而对回放造成干扰。可以每次生成回放数据时,随机的关闭ANN中的部分神经元,从而以类似dropout的方式,避免生成的回放数据产生过程中所带的背景偏差。

第四项改进,是在隐藏层就加入回放数据,而不是像之前那样,将生成的图像与对应的标签重新训练。这么做能够减少运算量。之所以能够这样做,是由于最初的特征提取,不论何种任务都是相同的。
除了利用神经科学的认知,来提升人工神经网络的持续学习能力,这项工作的另一个目的是说明大脑中的重放机制,对人类智能所起到的意义。本研究首次证明重放可能确实是大脑对抗灾难性遗忘的一种可行的方法。文中假定大脑中的回放是一个生成过程。这一猜想与越来越多的实验工作报告一致,即大脑中重复出现的表征并不直接反映经验,而是可能是世界学习模型的样本。
笔者分享该论文,是由于该研究是类脑计算,即通过模仿大脑,提升神经网络的典型案例。且文中的回放机制,让我想起温故而知新,可以为师矣。人脑中的记忆机制,决定了回顾往事的过程,是重新建构而不是百分比的回放。这最初看来,是大脑的缺陷,但从避免灾难性遗忘来看,却是不可或缺的。另一个脑洞是,睡眠时做梦,往往会出现类似但不完全相同的回放,这是否是进化赋予我们的“持续学习”能力了?
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”











