
新智元编译
来源:Nature
作者:Sarah Webb
编译:赵以文
【新智元导读】深度学习为分析生物大数据提供了强大的工具。BioRxiv预印本服务器上有超过440篇文章讨论深度学习;PubMed在2017年列出了700多篇与深度学习有关的参考文献。生物学家和临床研究人员之间正在掀起一股使用深度学习相关的工具的浪潮。但是,研究人员在理解和使用这些算法方面仍然面临着挑战。
四年前,谷歌科学家出现在神经科学家Steve Finkbeiner的家门口。Finkbeiner在位于旧金山的格莱斯顿神经病研究所工作,他和他的团队使用一种叫做机器人显微镜(robotic microscopy)的高通量成像策略产生大量数据,专门研究脑细胞。团队正在为无法快速分析数据而发愁。
这几位谷歌的研究人员则在谷歌位于山景城的研究部门Google Accelerated Science工作,这个部门旨在利用谷歌的技术加快科学发现的进展。他们希望将谷歌的“深度学习”方法应用于Finkbeiner团队生成的影像数据上面。
如今,他们的合作已经开始取得成效。Finkbeiner的团队与谷歌的科学家一起训练了一套深度算法,能以很高的精度自动为细胞打标签,相关研究报告已经在期刊发表。Finkbeiner表示,在合作之初,他并不能完全理解深度学习能做什么,只知道自己产生数据的速度超过了自己能分析的速度,但现在,他们的这套算法在预测该给细胞打什么标签方面好得“令人震惊”。
Finkbeiner的成功凸显了深度学习这一人工智能(AI)最有前途的分支之一正在大步迈入生物学领域。算法以人类无法做到的方式潜入数据中,捕获人类可能忽略的特征。研究人员正在使用这些算法对细胞图像进行分类,建立基因组连接,加速药物发现周期,甚至还能将基因数据、成像数据和电子病历这些不同类型的数据联系起来。
BioRxiv预印本服务器上有超过440篇文章讨论深度学习;PubMed在2017年列出了700多篇与深度学习有关的参考文献。生物学家和临床研究人员之间正在掀起一股使用深度学习相关的工具的浪潮。但是,研究人员在理解和使用这些算法方面仍然面临着挑战。
训练智能算法:单个细胞的图像中蕴含的数据如此之多,超乎想象
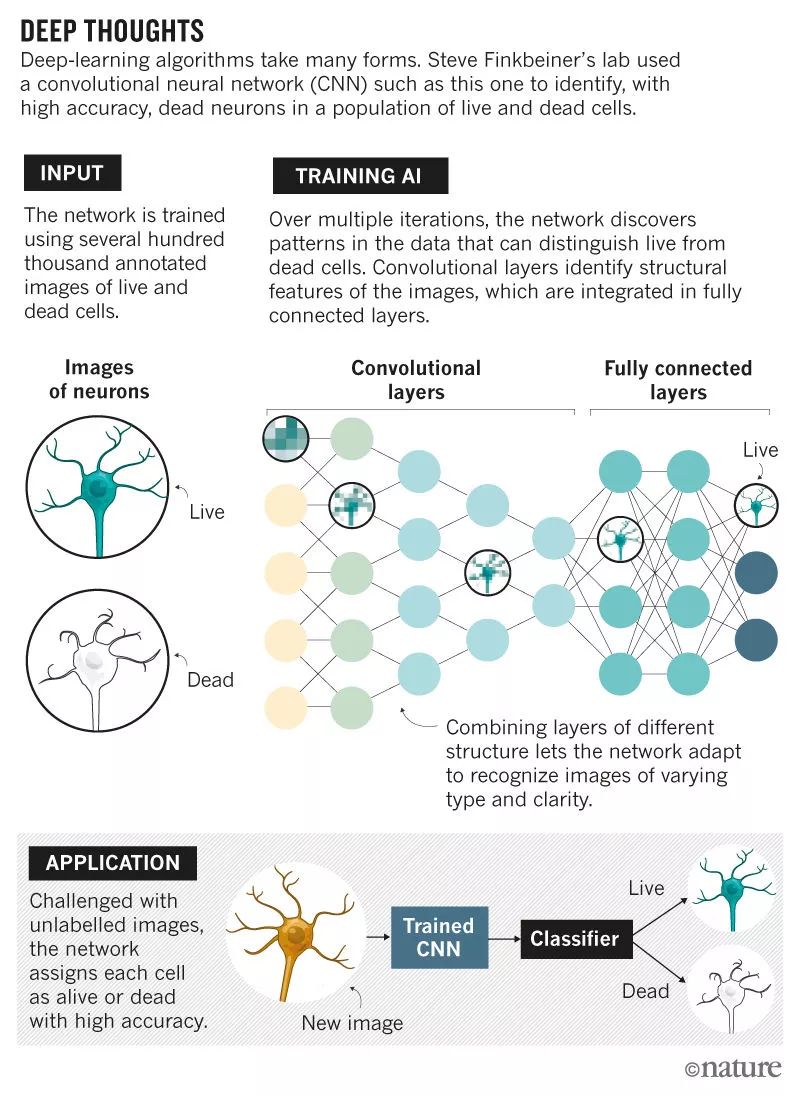
深度学习算法依赖于神经网络,神经网络是一种在20世纪40年代首次提出的计算模型,其中由类似神经元的节点组成的网络层模仿人类的大脑对信息进行分析。费城宾夕法尼亚大学计算生物学家Casey Greene说,直到大约5年前,基于神经网络的机器学习算法依赖研究人员将原始信息处理成更有意义的形式,然后才将其输入计算模型。但随着数据集规模的扩大,同时也得益于算法的创新,现在必须由人类完成的工作有所减少。 机器学习中的这一进步——深度学习中“深”的这部分——迫使计算机而非人类程序员找到深藏于数据之下的有意义的关系。随着神经网络中的各层网络对信息进行筛选、过滤和排序,它们还能相互通信,让每个层优化前一层的输出。
最终,这个过程能够得到一个训练好的算法,这个算法能分析一个从未见过的图像,并正确识别它。但是,减少了人类的参与,研究人员也无法再控制分类过程,甚至无法准确解释软件正在做什么。虽然深度学习网络在预测时可能非常准确,但正如Finkbeiner所说:“有时候,要弄清楚网络是看到了什么才做出如此精确的预测,仍然很有挑战性。”
尽管如此,包括成像学在内的许多生物学分支学科,都正在从深度学习做的预测收到回报。十年前的自动生物图像分析软件,一般专注于测量一组图像中的单个参数。例如,2005年,Broad研究所的计算生物学家Anne Carpenter发布了一个名为CellProfiler的开源软件包,帮助生物学家定量测量各种特征,比如显微镜视野里荧光细胞的数量,或者斑马鱼的长度。
但深度学习让她的团队走得更远。Carpenter说:“我们一直在朝着这个方向努力,那就是去测量生物学家没有意识到他们想要在图像中测量的东西。”将染色DNA、细胞器的纹理和细胞空白空间的质量这些视觉特征记录下来并进行组合,可以产生数千个“特征”,其中任何一个都能揭示新的见解。最新版本的CellProfiler已经有一些深度学习元素,Carpenter的团队希望在明年能够添加更复杂的深度学习工具。
Carpenter说:“大多数人都很难弄清这些问题,但单个细胞图像中就是有这么多的信息,实际上可能更多,就像细胞群的转录组分析一样。”
这种类型的处理使得Carpenter团队可以采取较少监督的方法,将细胞图像转化为与疾病相关的表型,然后再对其进行分析。Carpenter也在犹他州盐湖城的制药公司Recursion Pharmaceuticals担任科学顾问,该公司正在利用深度学习工具,针对稀有单基因疾病进行药物开发。
挖掘基因组数据:谷歌和Hinton担任顾问的Deep Genomics都在努力
深度学习需要大量的数据,但也不是只要是数据都行。深度学习通常需要的,是大量的标注良好的数据集。因此,成像数据就成了很自然的好选择,基因组数据也一样。
Verily Life Sciences(前身为Google Life Sciences)就是一家使用这类数据的生物技术公司。Verily是谷歌母公司Alphabet的子公司,Verily研究人员开发了一种深度学习工具,DeepVariant,可以比传统工具更准确地识别一种叫做“单核苷酸多态性”的常见遗传变异。DeepVariant软件将基因组信息翻译成像图像一样的表示(representations),然后对其进行分析。Mark DePristo在Verily负责基于深度学习的基因组研究,他认为DeepVariant对于研究非主流生物体特别有用,尤其是那些基因组质量低且识别遗传变异体的错误率高的对象。他的同事Ryan Poplin在植物领域与DeepVariant合作,将错误率从20%降低到了接近2%。
加拿大多伦多Deep Genomics公司的首席执行官Brendan Frey也专注于基因组数据,但他们努力的目标是预测和治疗疾病。 Frey在多伦多大学的学术团队开发了关于健康细胞基因组和转录组数据的算法。这些算法针对RNA事件构建预测模型,例如剪接、转录和聚腺苷酸化。应用于从未见过的临床数据时,训练好的算法能够识别突变并将其标记为是否具有致病性(pathogenic)。在Deep Genomics公司,Frey的团队正在使用相同的工具来识别该软件发现的疾病机制,并开发短核酸序列衍生的治疗方法。
药物发现是另一个拥有大量数据集等待深度学习去发掘的学科。在药物发现领域,深度学习算法正在帮助解决分类的挑战,筛选形状和氢键等分子特征,从而确定排列这些潜在药物的标准。位于旧金山的生物技术公司Atomwise,开发了将分子转换成三维像素网格的算法。这使Atomwise的研究人员能以原子精度解释蛋白质和小分子的三维结构,对碳原子的几何形状等特征进行建模。这些特征之后会被翻译成数学向量,算法可以用来预测哪些小分子可能与给定的蛋白质相互作用。
Atomwise正在利用这一策略推动其新的AI驱动的分子筛选计划,该计划扫描1000万个化合物库,为学术研究人员提供多达72种潜在的小分子粘合剂,用于粘合研究人员感兴趣的蛋白质。
深度学习工具还可以帮助研究人员对疾病类型进行分层(stratify),了解疾病亚群,找到新的治疗方法,并将其与患者进行匹配从而进行临床测试和治疗。例如,Finkbeiner所在的一个叫做Answer ALS的组织,致力于将1000多人的基因组学,转录组学,表观基因组学,蛋白质组学,影像学,甚至多能干细胞生物学等数据与神经退行性疾病肌萎缩侧索硬化结合在一起。“这是我们第一次有一个数据集,可以应用深度学习,并观察深度学习是否可以揭示我们能在细胞培养皿中测量的事物与该患者身上发生的事情之间的关系,”Finkbeiner说。
任重道远:具有高度可解释性的深度学习模型何时出现?
研究人员警告说,虽然起到了很多成效,但深度学习带来了重大挑战。与其他任何计算生物学技术一样,算法产生的结果取决于输入的数据。模型过拟合也是一个问题。另外,深度学习对于数据的量和质量,要求往往比一些实验生物学家预期的还要严格。
深度学习算法需要非常大的数据集,这些数据集都有很好的注释,以便算法可以学会区分特征,对模式进行分类。Finkbeiner指出,在大约15,000个样本之后,他的算法训练效果显著提高。实验需要数百万标记良好的数据。Carpenter说,高质量的“ground truth”数据可能非常难以实现。
为了规避这一挑战,研究人员一直在努力研究如何用更少的数据进行更多的训练。底层算法的进步使得神经网络可以更高效地使用数据。科学家还可以利用迁移学习,也即把神经网络从一种类型的数据获得的分类能力应用于另一种类型。例如,Finkbeiner的研究小组开发了一种算法,最初被用来根据啮齿动物细胞形态变化预测细胞死亡,但首次预测人类细胞图像时,准确率也达到了90%,改善后准确率达到99%。
对于一部分生物图像识别工作,Google Accelerated Science的算法最初使用从互联网挖掘的数亿个消费者图像进行训练。 然后,研究人员完善训练过程,将训练数据缩小到几百张生物图像。
Google Accelerated Science的研究科学家Michelle Dimon指出,深度学习带来的另一个挑战是计算机既不智能又懒惰,在区分生物学相关的差异和正常差异之间缺乏判断力。Dimon指出:“计算机在查找批量变化方面非常出色。因此,获取将被输入到深度学习算法中的数据,通常意味着对实验设计和控制有一个很高的标准。”Google Accelerated Science要求研究人员随机将对照组放置在细胞培养板上,从而解释微妙的环境因素(如孵化器温度),并使用两倍于生物学家可能使用的对照组。
这也强调了生物学家和计算机科学家共同参与实验设计对深度学习生物学实验的重要性。谷歌的一个最新项目Contour,就是将细胞成像数据用全新的方法分类,突出显示趋势(如剂量反应),而不是将它们归入特定的类别(比如是活着还是死亡)。
尽管深度学习算法可以在没有人类先入为主的输入的情况下评估数据,但Greene警告说,这并不意味着算法没有偏见。训练数据可能会出现偏差,例如,仅使用北欧人的基因组数据。这样在训练时引入的偏差会反映在算法的预测中,反过来可能导致对病人护理的不平等。当有人类来验证这些预测时,还算有个防范。但是,如果只剩下计算机来做出关键决定,这就会令人十分不安。Greene说:“把这些方法看作是增强人类而非代替人类要更好。”
此外还有挑战,比如如何正确理解这些算法,它们究竟是如何对数据进行分类的。马里兰州巴尔的摩的Insilico Medicine研究科学家Polina Mamoshina表示,计算机科学家正在通过改变模型中的各个特征,然后研究这些调整如何改变预测的准确性,来应对这个问题。但Greene警告说,虽然是同一个问题,但不同的神经网络会以不同的方式来处理。研究人员越来越关注能够做出准确和可解释的预测的算法,但现在系统仍然是黑盒子。
Greene说:“我不认为具有高度可解释性的深度学习模型将在2018年出现,但如果我错了我会很高兴。”
原文链接:https://www.nature.com/articles/d41586-018-02174-z

【2018新智元AI技术峰会重磅开启,599元早鸟票抢票中!】
2017年,作为人工智能领域最具影响力的产业服务平台——新智元成功举办了「新智元开源·生态技术峰会」和「2017AIWORLD 世界人工智能大会」。凭借超高活动人气及行业影响力,获得2017年度活动行“年度最具影响力主办方”奖项。
其中「2017 AI WORLD 世界人工智能大会」创人工智能领域活动先河,参会人次超5000;开场视频在腾讯视频点播量超100万;新华网图文直播超1200万。
2018年的3月29日,新智元再汇AI之力,共筑产业跃迁之路。在北京举办2018年中国AI开年盛典——2018新智元AI技术峰会,本次峰会以“产业·跃迁”为主题,特邀诺贝尔奖评委、德国人工智能研究中心创始人兼CEO Wolfgang Wahlster 亲临现场,与谷歌、微软、亚马逊、BAT、科大讯飞、京东和华为等企业重量级嘉宾,共同研讨技术变革,助力领域融合发展。
新智元诚挚邀请关心人工智能行业发展的各界人士 3 月 29 日亲临峰会现场,共同参与这一跨领域的思维碰撞。
关于大会更多信息,请关注新智元微信公众号或访问活动行页面(点击阅读原文):http://www.huodongxing.com/event/8426451122400











