
Python 程序员,特别是做爬虫的同学都知道 HTTP 请求库 Requests,Requests 完美体现了 “for Humans” 这个词要表达的意思。
它的作者是高颜值的摄影爱好者 kennethreitz ,kennethreitz 写过很多的库, 除了 Requests 、还有 pipenv,一个更好的集成了包管理和环境管理的工具。日期时间库 maya 等等。
今天他又搞出一个新项目叫 Requests-HTML,HTML Parsing for Humans ,顾名思义,它是用于解析 HTML 文档的。
以前我们写爬虫,解析 HTML 页面通常会选择 BeautifulSoup 或者是 lxml 库,虽然 BeautifulSoup 的 API 比较友好,但是它的解析性能低下,而 lxml 使用 xpath 语法,解析速度快,但是代码没什么可读性,现在 kennethreitz 搞出来的这个 html 解析库继承了 requests 库的优良传统 —- for humans。
我们知道 requests 只负责网络请求,但不对响应结果进行解析,你可以把 requests-html 理解为可以解析 html 文档的 requsts 库。
Requests-HTML 的代码量其实非常少,目前不到 200 行,都是基于现有的框架进行二次封装,使得开发者使用的时候更方便调用。它依赖于 PyQuery、Requests、lxml 等库。
安装

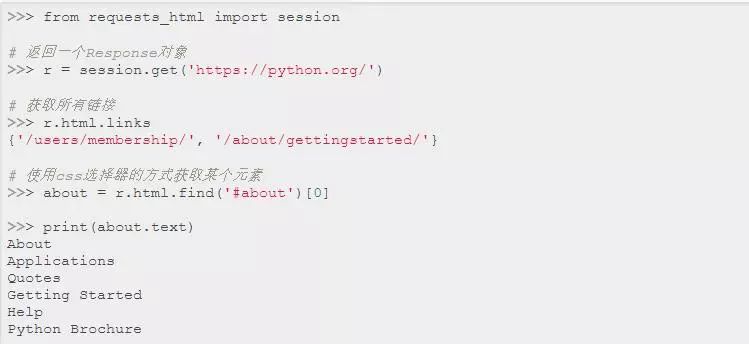
使用方法
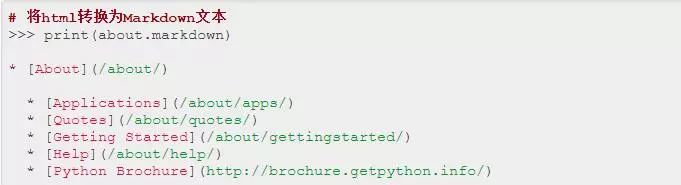
另外,还有一个非常吸引人的特点是,它能将html转换为markdown文本
更多使用方法可以参考文档:
https://github.com/kennethreitz/requests-html
推荐阅读
学Python,关注Python之禅









