
向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT数据分析 公众号: datadw
前言
之前在知乎上看到这么一个问题:在实际业务里,在工作中有什么用得到深度学习的例子么?用到 GPU 了么?,回头看了一下自己写了这么多东西一直围绕着traditional machine learning,所以就有了一个整理出深度学习在我熟悉的风控、推荐、CRM等等这些领域的用法的想法。
我想在这边篇文章浅入浅出的谈谈这几个方面,当然深度学习你所要了解必然不仅仅如此,后面如果有机会我会一篇篇的完善:
CNN/RNN理解
Attention理解
深度学习(CNN和RNN)传统领域的简单应用
关于深度学习的一些想法
大概会将全文分为以上几块,大家可以跳读,因为本文理论上应该会冗长无比,肯定也包括数据块+代码块+解析块,很多有基础的同学没有必要从头在了解一遍。好了,让我们正式开始。
CNN/RNN理解
CNN
CNN,卷积神经网络,让我们先从一个简单的网络结构来梳理一下:

输入层
假如,我们有car,plane,desk,flower等等一共十类的图片,需要让电脑识别图片是哪种的话,自然需要把图片变成电脑理解的了的一种方式,比如:RxGxB(图片的高度、宽度和深度)也就是上面输入层32x32x3,至于什么是RGB,请自行阅读RGB百度百科。
卷积层一/卷积层二
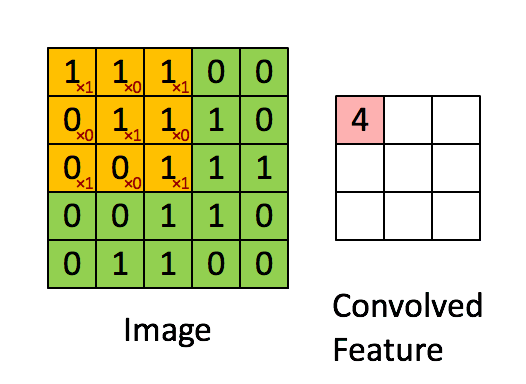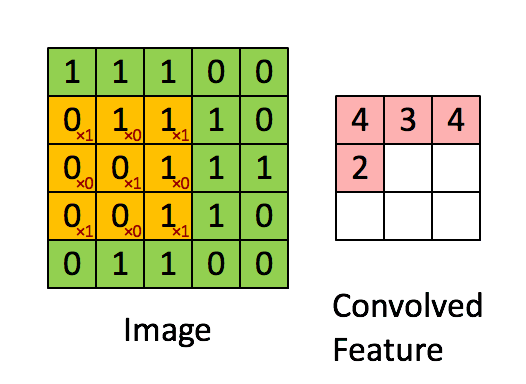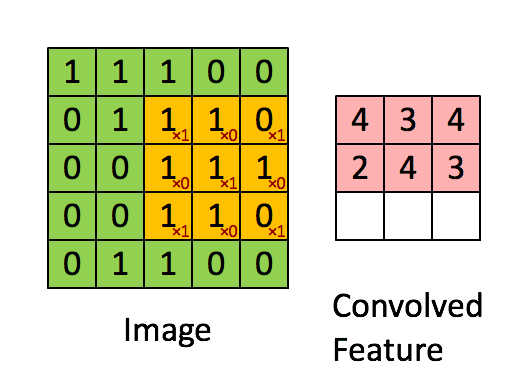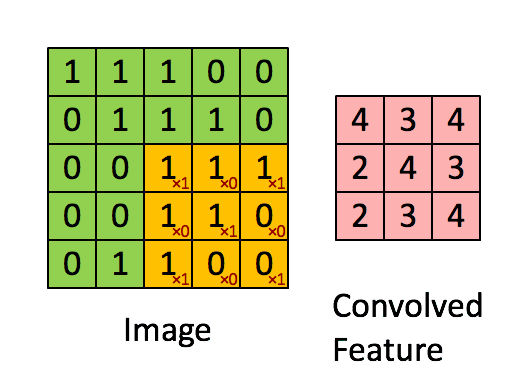
卷积过程
这张图片我觉得形象的不能再形象了,让我们结合代码和图形来理解这个卷积到底是什么意思。tensorflow中卷积的集成代码如下:
filter_weights = tf.Variable(tf.truncated_normal([window_size, embed_dim, 1, filter_num], stddev=0.1),name="filter_weights")
conv_layer = tf.nn.conv2d(item_embed_layer_expand, filter_weights, [1, 1, 1, 1], padding="VALID",name="conv_layer")
filter_weights的shape是window_sizexembed_dimx1xfilter_num,window_sizexembed_dimgx1就是类似于gif图中的黄色区域的大小,这边就可以看作window_size=embed_dim=3,filter_weights第三维的1是指HRG中的第三维度:
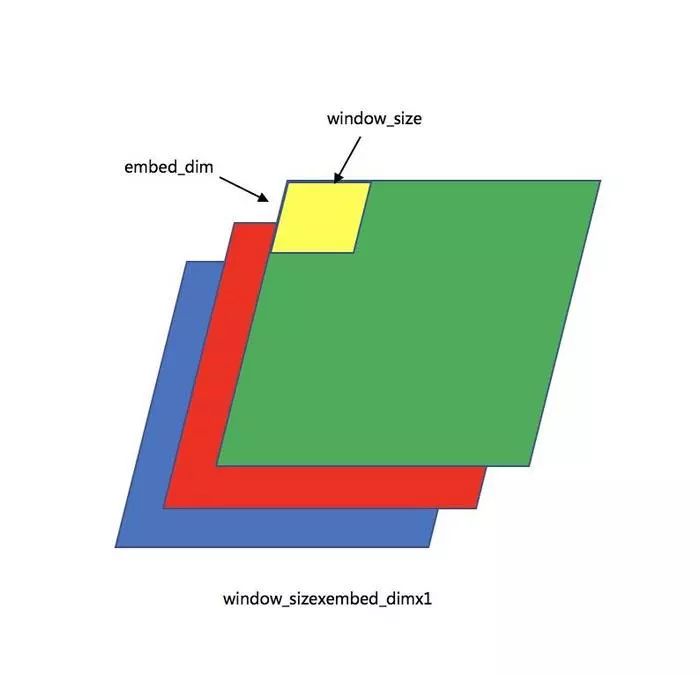
filter_weights第三维如果是2的话:
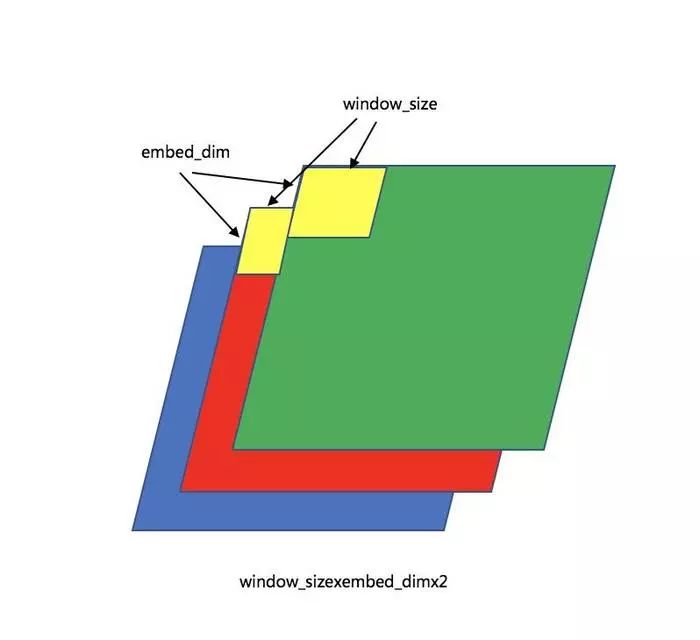
想到于多了一维的并行处理,接下来看filter_weights的filter_num,最上方的gif的动图解释了卷积层的计算形式:
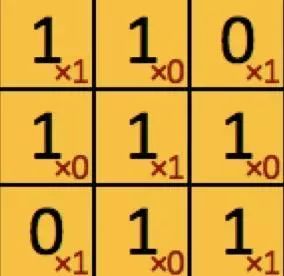
黑色字体的1/0矩阵是原来图像的像素值,红色的1/0是上面设置filter_weights值,他们的分别计算后的累计值即为一次扫描计算结果,比如黄色区域即为1x1+1x0+0x1+1x0+1x1+1x0+0x1+1x0+1x1.将所有的像素值所在的位置都进行一次扫描后就可以得到:
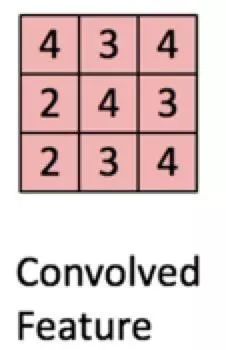
当然,除了随机生产filter_weights,图像操作中,指定不同的filter_weights会起到不同的作用:

但是这里面存在两个问题:
边界扫描(padding="VALID")
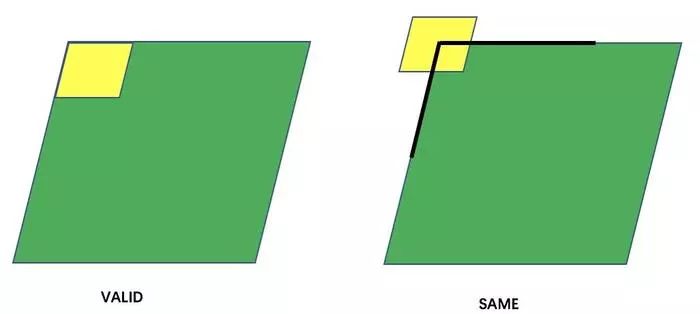
VALID模式如上图所示,对原始图像进行卷积,卷积后的矩阵只有3×3阶,比原来的图片要小了。
SAME模式要求卷积后的feature map与输入的矩阵大小相同,因此需要对输入矩阵的外层包裹n层0,然后再按照VALID的卷积方法进行卷积。
n的求法如下式:
SAME:
edge_row = (kernel_row - 1) / 2
edge_cols = (kernel_cols - 1) / 2
VALID:edge_row = edge_cols = 0
其中,edge_row是包裹0的行数,edge_cols是包裹0的列数 , kernel_row就卷积核的行数。
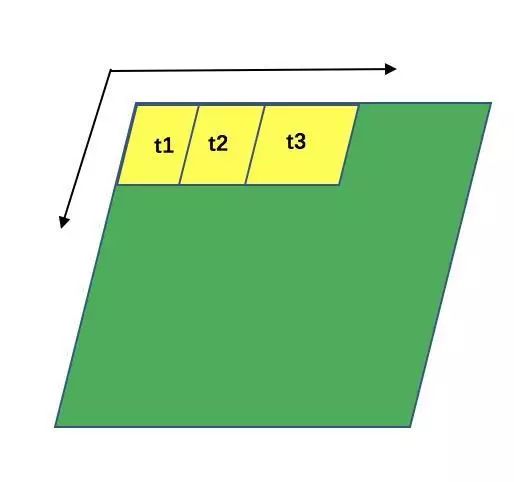
扫描速度(tf.nn.conv2d中的[1,1,1,1])
这个概率也是最好理解的了,就是图中的黄色方框位移的速度:
回到最上面filter_num,filter_num的值就是重复上述流程的次数,随着次数的增加,会增加后面pooling层的基础数据层数:
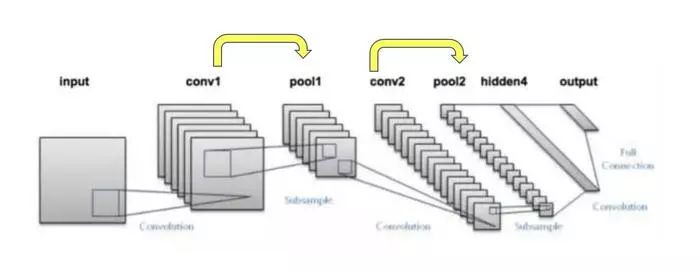
每次黄色箭头后的pool层的层数就是filter_num。
到此为止,卷积层就简单的梳理完了,主要是要清楚几个概念:filter_weights的作用,filter_num的定义,padding的差异,还有扫描的速度。这些主要是围绕着下面我要实际应用的场景梳理的卷积神经网络的知识点,如果要深刻透彻的了解还需要更多更深入的解读。
池化层一/池化层二
先从数学角度来看,它的操作步骤:
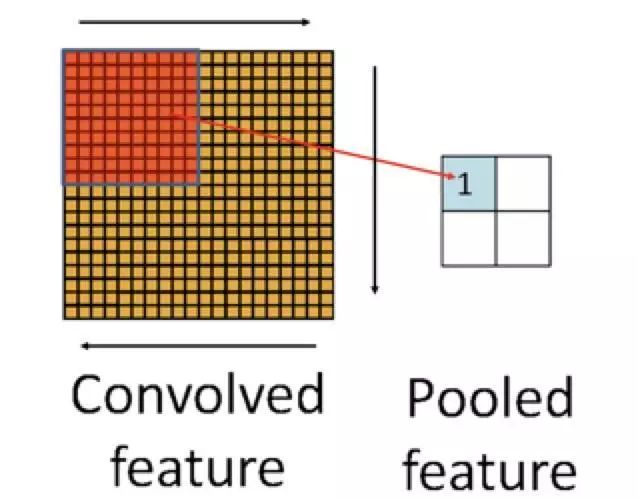
这张图看起来,和卷积层中的image --> Convolved feature非常类似,也是确定一个shape之后,对shape内的数据进行操作,但是差异就在:卷积层中是采取对image里面的像素点逐点计算后汇总,相当于加权了每个像素点的作用;而池化层通常采用最大/最小/均值/求和等方式汇总Convolved feature。
罗列出来就是:
池化层数学的操作比较简单,在实际工程中的理解比较让人困惑,其实,意义主要在三点:
其中一个显而易见,就是减少参数。通过对 Feature Map(通过的手段是聚合计算) 降维,有效减少后续层需要的参数
一个是 Translation Invariance。它表示对于 Input,当其中像素在邻域发生微小位移时,Pooling Layer 的输出是不变的。这就使网络的鲁棒性增强了,有一定抗扰动的作用
另一个是以区块的角度代替逐个点进行计算,降低每个点对最后结果的影响,避免了过拟合的现象
全连接层/输出层
这个就比较简单了,全连接层(FC)构造如下:
tf.layers.dense(brand_embed_layer, embed_dim, name="brand_fc_layer", activation=tf.nn.relu)
简单的来说,通过activation增加了特征的非线性的拟合能力;如果不设置activation的话,就增加了特征的线性拟合能力。
但是,我们要知道,全连接层会有很多缺陷:
在一定程度上,可以通过增加全连接的层数提高train data的准确率,但是如果过分的增加,会造成过拟合,所以如果是自己写的网络,一定程度上,如何控制还好全连接层的数量决定了valid data了准确率的波动。其实,完全可以通过pool层代替全连接层,17年年初很多论文指出:GAP(Global Average Pooling)的方法可以代替FC(全连接)。思想就是:用 feature map 直接表示属于某个类的 confidence map,比如有10个类,就在最后输出10个 feature map,每个feature map中的值加起来求平均值,然后把得到的这些平均值直接作为属于某个类别的 confidence value,再输入softmax中分类, 更重要的是实验效果并不比用 FC 差,所以全连接层的分类器的作用就可以被pool层合理代替掉。
而且,全连接层参数冗余(仅全连接层参数就可占整个网络参数60%-80%),计算量会集中在这些参数的计算上,而且随着你的层数的增加,你的计算成本越来越大,如果是非GPU的机器在计算的过程中会非常非常吃亏。
之所以,现在的很多很多流行网络还是以FC参与计算的原因:
上面就简单了梳理了CNN里面的简单的网络结构,是不是真的就是这么简单呢?让我们看看上面叫做相对成熟的网络:
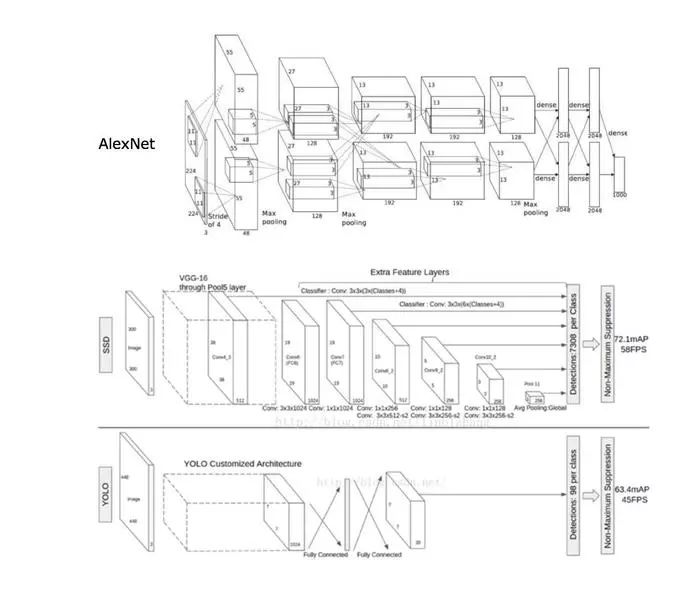
图像中几年前的技术,Alexnet,SSD,Yolo,还有去年的RCNN,fast-RCNN等等,网络结构都远远比我们想象中的要复杂,在对数据操作的行为中,无非也是上面这些操作的一些组合。
再次强调,本文重点不在介绍CNN,而是利用CNN作为传统机器学习做协助,所以,如果想要深入了解CNN的同学建议从头开始学习,不建议阅读我这种跳讲的内容作为入门。
RNN
相比CNN而言,RNN要简单而又有趣一些:
几乎所有的讲RNN的技术文章都会有下面这张图,无法免俗,因为确实囊括了RNN的核心:
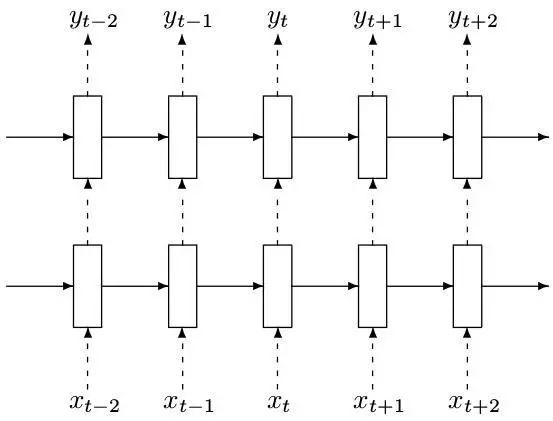
不得不说,nlp是RNN非常优秀的应用场景,我们从nlp的角度去切入,观察RNN在其中所起的作用也是非常好的一个方式:
假设有一句话:“今天天气真的不是很好,让我们去____吧。”
如果用朴素贝叶斯来解决这个填空问题,它的解决思路是:
如果用N-Grams来解决这个填空问题,它的解决思路是:
朴素贝叶斯的方法只考虑每个词出现的结果没有考虑先后顺序,可能导致由意外的非真实排序决定缺失值的问题;N-Grams的方法虽然考虑了每个词出现的可能的同时,也考虑缺失值前N个词的内容,但是由于计算能力的约束,并不能够完整的保留全部的前置语句的信息。
而RNN的出现,利用state层来存储前面t-1刻的信息,并循环传递在每次输出计算中,解决ngram做不到的完整信息保存的问题,如下图:
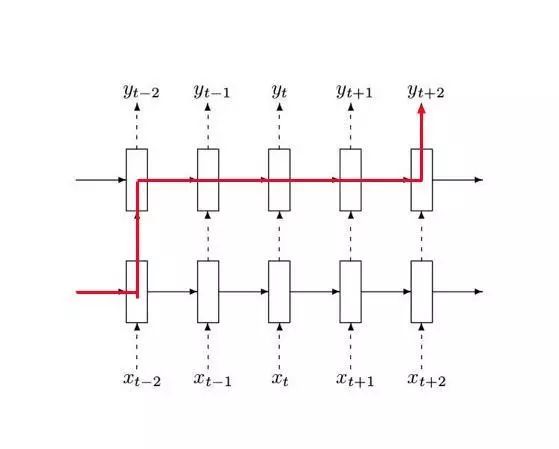
很明显,在对Yt+2的结果预测的时候,考虑到了前面所有前置的信息。
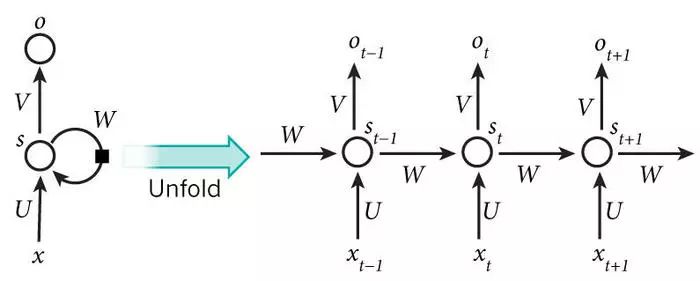
这张图很好的解释了RNN的传递逻辑,将所有前期的信息以state的形式进行传递,在第t次的输出结果计算的过程中,不仅仅考虑第t次的输入值,同时考虑t-1次的state,也就是前t-1层的信息的流动汇总结果。我们知道,最简单最基础的RNN里面,可以通过tanh层来合并t-1时刻的state和t时刻的xt信息的。虽然理论上来说,无论信息是各多远,RNN都能够记得,但是!但是!实际上,我们发现,RNN随着tanh的重复操作,是无法稍远的信息就无法合理的被记忆,幸运的是后面优化出来的LSTM和GRU就能一定程度上缓解这些的问题。
下面让我们以GRU为例子,具体看看RNN是怎么进行一次循环神经网络的计算的:
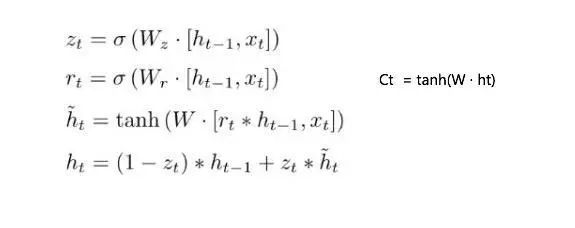
这边大家需要注意,与LSTM不同,GRU将LSTM中的输入门和遗忘门合并成了更新门。而且没有建立中间过渡键memory cell,而是直接通过更新门和重置门来更新state。这样做的好处就是大大的降低了计算的成本,加快了整个RNN训练的速度。同时通过各种Gate将重要特征保留,保证其在long-term传播的时候也不会被丢失,也有利于BP的时候不容易造成梯度消失。
在RNN的官方论文中,我们看到了实测的效果如下:
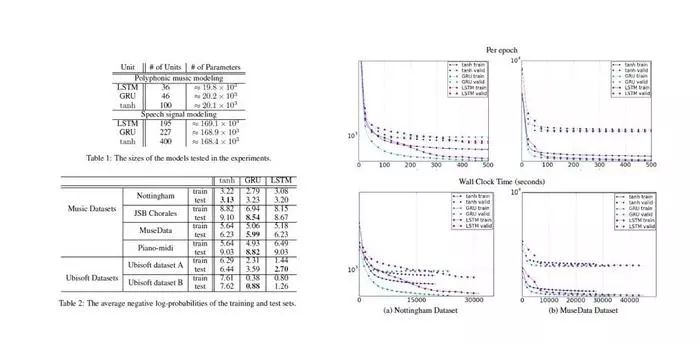
很明显的可以看到,1.虽然GRU减少了一个门的存在,但是效果与LSTM相当,但是几乎每次测试的test效果都要优秀于传统方法。2.GRU是真的肉眼可见的比LSTM快,证实了我们上述说的内容。也是因为这些原因,在后面为实际应用的过程中,我也是选择了GRU来代替了LSTM做向量化及state层提取等等操作。
问题来了,虽然我知道LSTM和GRU在最后实测的效果上是比直接用tanh的简单RNN效果要好的,但是我也无法解释和理解为什么这样的构造就能够有这样的提升,这就比较尴尬了。
另外要提的一点就是,在GRU实际计算的过程中,采取了学习参数拼接的方式,比如上面的Wz,Wr等是通过拼接的方式存储的,在需要的计算的时候再拆分开进行计算:
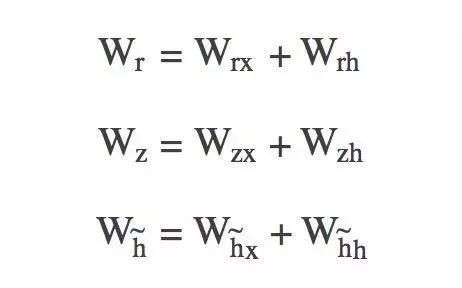
这也是让我在学习GRU过程中眼前一亮的点,非常值得玩味的地方。
Attention理解
在篇幅如此冗长的情况下,我依然坚持要和大家讨论一下关于Attention的一些看法和观点,我觉得正是有attention的存在,才让我们能够想到如何更好的去扩展应用这些深度学习的方法。
我之前一直没有找到很好的通俗易懂的解释attention的文章,这边我尝试以业务的角度为大家分析一下,尽可能的抛开数学的角度让大家浅入浅出一下。
假设存在用户A,及他的各种行为A_actions,如果我不做任何操作简单的把他的各种行为A_actions当成变量进行模型训练可以得到模型AM。但是,如果我知道,他可能是一个2年前流失近期活跃的用户,我选择剔除他两年前的A_actions,而只考虑他近期的行为,这样的过程其实就是一个Attention的过程,因为我们要预测他近期可能买什么,所以我们应该把关注点集中在了他近期的部分信息而不是全部信息上。
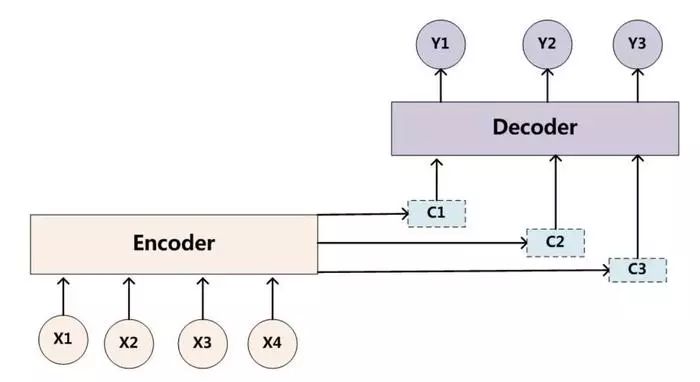
而在深度学习运用的过程中,我们也应该考虑attention的问题,比如用户商品点击流为A-->B-->A-->C-->D,我们常规操作是什么样的?无非是:
以上就是一个非常简单的Encoder-Decoder过程。
仔细想想其实就会发现很多不合理的地方,比如我在B商品停留了2mins,而其他商品均只停留了不到10s;再比如,我有购买C商品的历史,ABD商品均为第一次接触等等。其实,对于ABCD而言,简单的理解就是它们为不是等权的。而且我们发现,随着你的信息量的增加,也就是item点击流的长度增加,encoder的信息丢失就会变得非常严重,decoder的难度会大大的提升。
回过头来看上述的流程,如果变成:
生成4xembed_dim的embedding层
将ABCD四个商品编号为0123
找到对应商品在embedding层中的向量表示
Xa,Xb,Xc,Xd = ∑(aiA,biB,ciC,diD)
通过RNN或者其他深度学习网络进行非线性Decoder输出对应的可能结果
换句话说,就是在坑爹的Encoder到Decoder过程中,增加了缓冲计算Ci,通过构造Ci代替Encoder结果进行Decoder的过程,让深度学习的过程更加的合理。
数学的形式就是:
y1=f1(C1)
y2=f1(C2,y1)
y3=f1(C3,y1,y2)
...
比如我在B商品停留了2mins,而其他商品均只停留了不到10s时,我们就可以构造缓冲C=g(0.1xf(A)+0.6xf(B)+0.1xf(C)+0.1xf(D)),这意味着A-->B-->A-->C-->D-->?,对于?的判断,B起了比ACD都要重要的作用。
大名鼎鼎的RNN在attention的机制下就会变成:
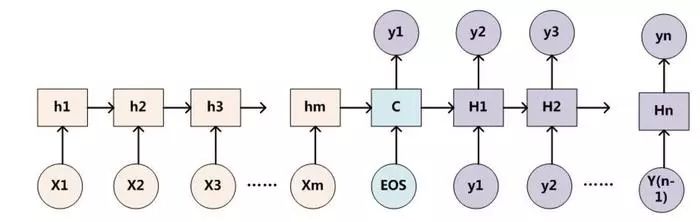
那么具体如何构造缓冲C呢,我们看下面这个流程:
首先,在RNN最初参数设置的时候,我们会确定init memory,不妨记为z0;hi为当前时刻输出的隐层输出向量,所以对每个商品ABCD都有一个z0与hi的相似度∂0i:
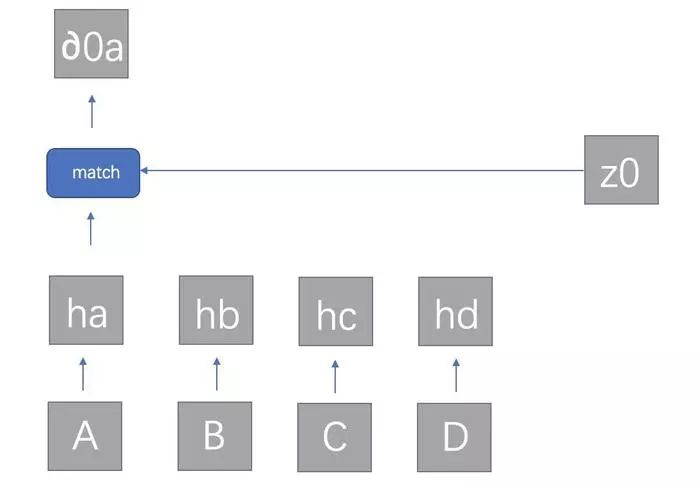
在每次循环之前,相当于考虑了当前所有的输入(比如此刻的ABCD)与initmemory的匹配度,至于匹配度match在论文中的计算方式为:矩阵变换α=hTWz (Multiplicative attention,Luong et al., 2015) ,其实简化为余弦相似度也是可以的,只要能判断两者之间的相似程度都行。算出所有的∂0a,∂0b,∂0c,∂0d后归一化后的值即可作为ABCD对应的隐层ha,hb,hc,hd的权重:
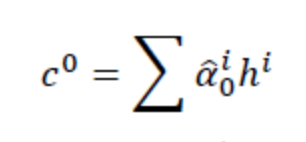
c0即可作为rnn的输入,有c0和z0,我们非常容易可以算出z1,得到z1后,重复上述的过程可以得到c1...,如此循环,直到结束。论文中的计算方式如下:
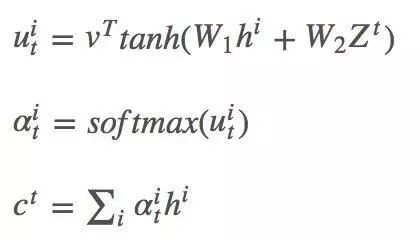
和nlp中构造方式对比起来,还是有一定的差异,nlp的训练集往往是确定的。比如:“我爱学习”翻译为“i love studying”,我翻译为i,所以我确定一定要对“i”进行翻译的时候,需要提高对应i的权重。而我在商品点击流预测购买概率的时候,只能通过停留时长,历史是否购买过来建立约等的关系,但是这个约等的关系是不存在强成立的前提的。
attention的机制最初理解起来有点绕,但是如果能够搞懂并在我们做深度网络设计中应用起来,理论上收益还是非常之大的,建议大家把上述为贴的论文详读一边,真的是写的非常不错的一篇文章。
深度学习传统领域的应用
我们先来回想一下,我们做传统有监督是怎么做的,如果记不得了,可以回顾这篇文章:提升有监督学习效果的实战解析,我认为有几点传统有监督学习不是很友好:
特征工程
想必有过特征工程项目经验的同学可能是对数据预处理及特征筛选过程心有余悸:
是不是用户信息,商品信息,用户历史信息,商品信息统计属性刻画,用户行为整合每一块写hive都要很久很久?跑数据的时间更久?
是不是数据好不容易跑出来了,各种垃圾信息,各种格式问题,pandas,numpy来回折腾到几百行的代码?
是不是好不容易数据处理完,一跑结果auc0.6?修改都不知道怎么修改?
是不是四处看别人整理的调参心得,比如这个家伙的Kaggle&TianChi分类问题相关纯算法理论剖析,然后发现优化后就提升了1个点?
是不是上线之后发现数据量一旦一大,你本地跑的脚本全部都报出:MemoryError?
是不是立项一周后产品经理过来问什么时候上线的时候,你连数据还没整理完?
诸如这样坑爹的事情实在多的不能再多,相对而言,无论是是CNN还是RNN或者其他深度学习网络的input都是非常简单很清晰的,我这边给出一些简单的例子:
你在构造卷积神经网络的时候,只需拿出商品的基础属性,然后用不同性质的向量化方法embedding成不同的向量对象进行channel叠加就行了:
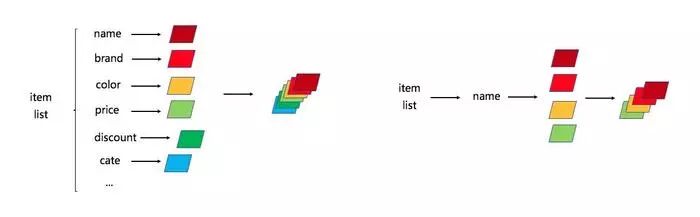
你在构造循环神经网络的时候,只需拿出用户商品的点击流,然后构造一个流通的点对点的循环网络即可:
卷积网络的原始数据只需要整理item与attribute对应关系,循环网络的原始数据只需要整理item与clickflow对应关系,相比复杂的传统方法的各种技巧,特征工程的提取整理的时间会大大减少,而且在线上数据处理过程中发生Memory Error的可能也无限变小。
实效性
这个就比较好理解了,如果我们需要知道用户在app上每一刻的下单概率分布,如果用传统方法实现难度比较大,比如汇总前若干长时间内的信息再处理加工成模型需要的形式,再通过模型判断概率,可能就不是实时概率预估了。
而如果按照上述深度学习特征梳理方法,离线训练训练好用户的点击信息商品信息,再利用训练好的模型加用户在app上的实时行为,去预测用户在app上每一步操作对目标变量的影响,虽然我在离线训练的时间会付出的更多,但是我在线上预测会更加快捷。
具体效果我们以订单预估为例,深度学习预估方法下我们会很容易看到一个用户从开始一个session到结束一个session的过程中,购买欲望的分布:
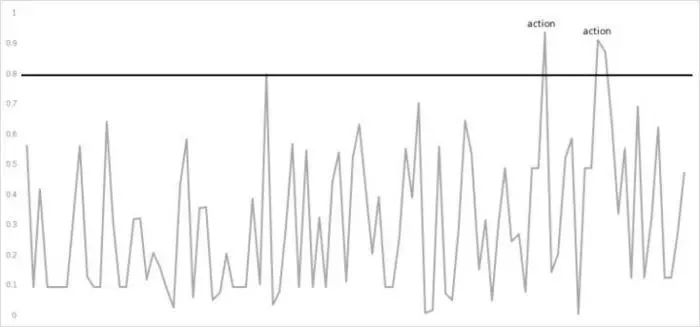
在用户购买欲望特别高涨的时候,通过相应的push或者文案提醒,促进用户下单,提高成单率。
除此之外,我们还可以观察到每一刻全平台用户的购买欲望分布:
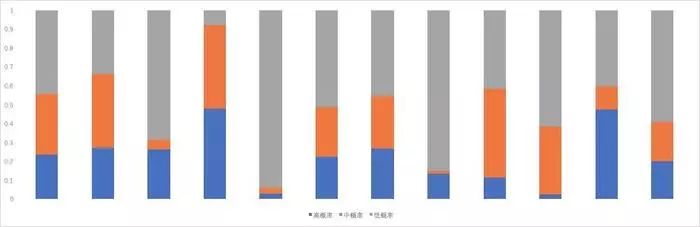
数据解析能力
在围绕构造特征的时候,我们在对过去的数据整理的过程中,其实构造的最多的就是“过去N天”,“历史上”,“最后一次”,“第一次至今”,等等。其实,这些构造方法要么是汇总整合一段时间的信息,要么是单点的考虑某个时刻的信息量。但是,深度学习一定程度上会选择的汇总过去的信息的累积,根据实际对最终结果的影响,改变单次行为上的权重,避免单次行为对因变量的错误影响。比如RNN中的state,上面RNN中的文章我也介绍了,它的生成其实就是保留了前t-1次中的部分信息。
知乎上有这么一个问题RNN方法能够捕捉到 传统时间序列回归中的 trend ,seasonality么?,其实我也很好奇,在引入深度学习的fc层到machine learing做stack的时候,确实绝大部分都能提高auc,但是是不是因为这些深度学习方法能捕捉到传统的数据里面的类似trend这些难以统计描述的性质?
案例
说了这么多,我觉得还是以具体的例子来剖析比较有说服力,因为深度学习的模型相对比传统的模型代码要长很多很多,我这边只截取我认为比较重要的地方解释一下,想要看demo的去看我的GitHub吧。
https://link.jianshu.com/?t=https%3A%2F%2Fgithub.com%2Fsladesha%2Fdeep_learning
我给出的例子都是最简单的网络设计,如果实际要应用大家可以按照自己业务的需求增加网络的深度,改变网络的结构,这边只是给大家一个方向。此外,数据的处理也并没有因为深度学习模型的出现而变得不重要,Garbage In, Garbage Out!!!
RNN方案的思路是来自于Domonkos Tikk和Alexandros Karatzoglou在《Session-based Recommendations with Recurrent Neural Networks》
它构造了embedding层来把原始的输入item映射为一个长度定义好的向量:
embedding = tf.get_variable('embedding', [self.n_risks, self.rnn_size], initializer=initializer)
通过把user浏览或者点击过的item进行index编号X,然后根据编号去embedding层去找对应的vector,后续只要用用户接触到了该item就重复以上的embedding过程就行了。
inputs = tf.nn.embedding_lookup(embedding, self.X)
再构造了简单的GRU层来学习每次用户的点击先后顺序之间的关系:
cell = rnn_cell.GRUCell(self.rnn_size, activation=self.hidden_act)
drop_cell = rnn_cell.DropoutWrapper(cell, output_keep_prob=self.dropout_p_hidden)
stacked_cell = rnn_cell.MultiRNNCell([drop_cell] * self.layers)
它的网络结构一点也不复杂:
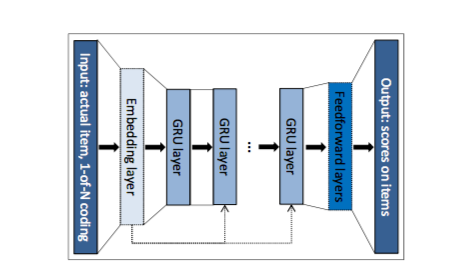
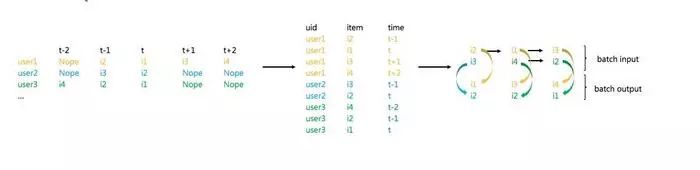
首先,需要把数据集构造成中间的uid+item+time的格式:
然后通过用户自身点击item的顺序,以时间靠前的item项预测时间靠后的item项,训练完成后记录每条数据对应的out和state。
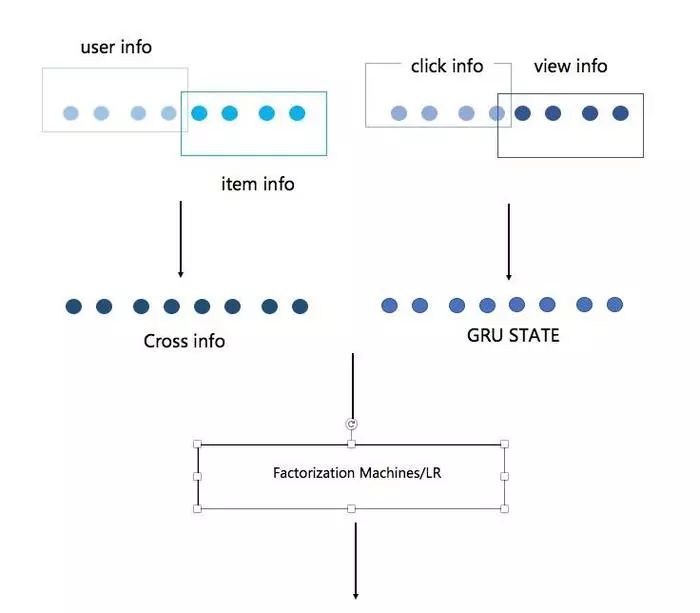
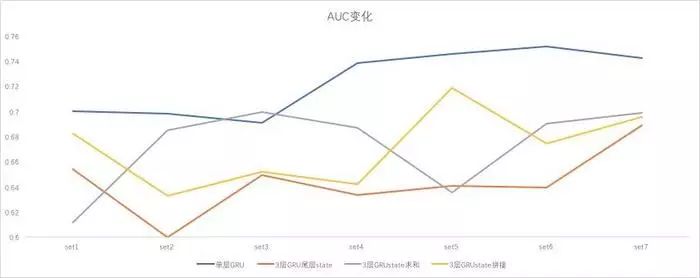
但是我实测了多层GRU和单层GRU,因为我们需要进行stacking的过程,不建议做多层的GRU,层数越多每层的信息量越稀薄,我通过sum,mean处理后仍不如单层:
CNN的方案通常可以采取以下通用的网络形式:
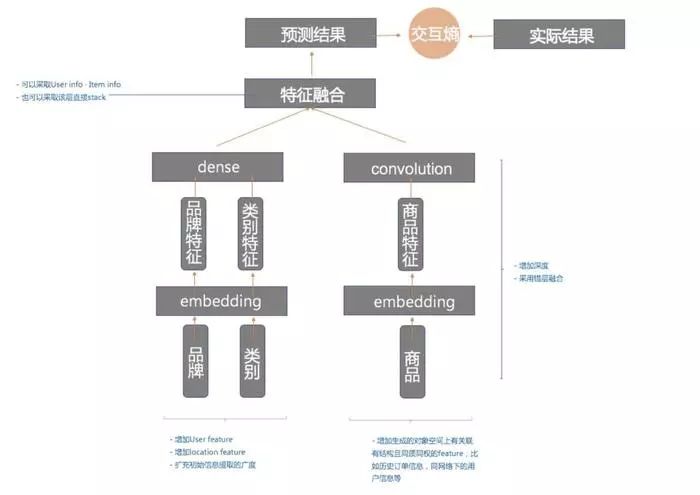
所以可优化的点我均在网络结构中标注了,但是我一直没有找到CNN再传统学习中比较好的应用方式,如果拿最后一个FC层的向量stacking实测效果并不理想,相关代码我也放在了GitHub中了,大家可以作为一个尝试性的demo去看。
一样的item的向量化处理方式:
cate_embed_matrix = tf.Variable(tf.random_uniform([cate_max, embed_dim], -1, 1),name="cate_embed_matrix")
cate_embed_layer = tf.nn.embedding_lookup(cate_embed_matrix, cate, name="cate_embed_layer")
本文来自 微信公众号 datadw 【大数据挖掘DT数据分析】
网络结构中主要是通过构造全连接层和卷积层:
cate_fc_layer = tf.layers.dense(cate_embed_layer, embed_dim, name="cate_fc_layer", activation=tf.nn.relu)filter_weights = tf.Variable(tf.truncated_normal([window_size, embed_dim, 1, filter_num], stddev=0.1),name="filter_weights")
filter_bias = tf.Variable(tf.constant(0.1, shape=[filter_num]), name="filter_bias")
conv_layer = tf.nn.conv2d(item_embed_layer_expand, filter_weights, [1, 1, 1, 1], padding="VALID",name="conv_layer")
relu_layer = tf.nn.relu(tf.nn.bias_add(conv_layer, filter_bias), name="relu_layer")
maxpool_layer = tf.nn.max_pool(relu_layer, [1, sentences_size - window_size + 1, 1, 1], [1, 1, 1, 1],padding="VALID", name="maxpool_layer")
然后再把所有全连接完和卷积完的vector拼接:
cate_fc_layer = tf.layers.dense(cate_embed_layer, embed_dim, name="cate_fc_layer",activation=tf.nn.relu)
brand_fc_layer = tf.layers.dense(brand_embed_layer, embed_dim, name="brand_fc_layer",activation=tf.nn.relu)bc_combine_layer = tf.concat([cate_fc_layer, brand_fc_layer, dropout_layer], 2) bc_combine_layer = tf.contrib.layers.fully_connected(bc_combine_layer, 200, tf.tanh)
最后通过全连接输出结果:
inference_layer = item_combine_layer_flat
inference = tf.layers.dense(inference_layer, 2, kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),kernel_regularizer=tf.nn.l2_loss, name="inference")
关于深度学习一些想法
这篇文章终于要结束了,漫漫长文。图像、语音、自然语言处理这三个领域,深度学习的性能就是比传统方法好得多,无可辩驳。但是传统领域,比如点击率预估,风控概率预估,金融风险预估等等,我不赞成非得和深度学习扯上关系,我们应该想想:
我们有足够大量的数据支撑计算么?
我们的业务需求允许我们进行大量黑盒计算么?
带来的“提高”允许你所付出的成本么?
使用者真的知道自己在做什么么?
最后,我以血和泪的教训知道自己写的网络对模型的效果提升是非常非常小的,建议大家先熟知现有的成熟的网络
https://www.jianshu.com/p/adff4c48c40c
人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注











