
周末带孩子正准备玩积木的时候,手机响了,死磕 Elasticsearch 技术群里在探讨 Elastic 认证中聚合考点,我想起关于 Elasticsearch 聚合,我之前写过 2-3 篇文章,跨度也得有3年。但是,或多或少都是官方文档的东西,不够深入浅出。再看到手里的这堆积木,灵感来了,就带着孩子摆了各种积木造型,然后就有了这篇文章。

数据来源——积木

图1
来个视频,看看有多凌乱。
数据(也就是积木)特点也就有了:
小朋友喜欢积木的原因就是:可以任想象力肆意自由发挥,堆出各种自己喜欢的造型。
但这和聚合有啥子关系呢?
别急,慢慢来......

把玩一下积木吧
下图 2 是我们家小宝的作品。

图 2
下面图3、图4是我摆的。

图 3

图 4
看出什么区别?
成年人的世界已被社会打磨(cui can)的没有棱角、缺少了天马行空,只剩下中规中矩(开玩笑)。
图3、图4有什么特点呢?

拆解聚合
由图 1 到 图 3、4 的本质:杂乱无章->基本有序。这个聚集的过程抽象提炼一下就是聚合。
第一次听聚合可能不好理解,看了上面的图能好理解一些。
再聚焦一下聚合的分类。
3.1 分桶聚合(bucket)
分桶聚合中桶的概念,它是翻译的词汇。本质就是聚合、数据汇聚的一种方式。
先上积木,然后再数据建模 DSL 过一遍就很容易理解了。
原始数据都是:图1。

图5
图 5 就是基于图1杂乱数据,按照颜色聚合的结果。
聚合结果是:
红色一桶
黄色一桶
蓝色一桶
绿色一桶

图6
图 6 就是基于图1杂乱数据,按照形状聚合的结果。
聚合结果是:
-
而如上内容,对应 Elasticsearch 中哪些聚合呢?
官方文档中的:Aggregations -> Bucket aggregations -> Terms。
数据建模实现一把:
PUT toy_demo_001
{
"mappings": {
"properties": {
"color":{
"type":"keyword"
},
"name":{
"type":"keyword"
}
}
}
}
POST toy_demo_001/_bulk
{"index":{"_id":1}}
{"color":"red", "name":"red_01"}
{"index":{"_id":2}}
{"color":"red", "name":"red_02"}
{"index":{"_id":3}}
{"color":"red", "name":"red_03"}
{"index":{"_id":4}}
{"color":"green", "name":"green_01"}
{"index":{"_id":5}}
{"color":"blue", "name":"blue_02"}
{"index":{"_id":6}}
{"color":"green", "name":"green_02"}
{"index":{"_id":7}}
{"color":"blue", "name":"blue_03"}
POST toy_demo_001/_search
{
"size":0,
"aggs": {
"color_terms_agg": {
"terms": {
"field":"color"
}
}
}
}
上述基于颜色的聚合结果如下:

key:代表的基于颜色的分桶。
doc_value: 每个桶中积木数量。
其他 bucket 聚合,参见官方文档:Aggregations -> Bucket aggregations 。
3.2 指标聚合(Metric)

图 7

图 8
由 图 7 到 图 8,发生了什么?
图8:获取了图 7 中积木的最小值、平均值,最大值。
映射到 Elasticsearch,本质上就是发生了指标聚合。怎么破?看个实例:
PUT toy_demo_002
{
"mappings": {
"properties": {
"size":{
"type":"integer"
},
"name":{
"type":"keyword"
}
}
}
}
POST toy_demo_002/_bulk
{"index":{"_id":0}}
{"size":0, "name":"red_0"}
{"index":{"_id":1}}
{"size":1, "name":"red_1"}
{"index":{"_id":2}}
{"size":2, "name":"green_2"}
{"index":{"_id":3}}
{"size":3, "name":"yellow_3"}
{"index":{"_id":4}}
{"size":4, "name":"green_4"}
{"index":{"_id":5}}
{"size":5, "name":"blue_5"}
{"index":{"_id":6}}
{"size":6, "name":"yellow_6"}
{"index":{"_id":7}}
{"size":7, "name":"blue_7"}
{"index":{"_id":8}}
{"size":8, "name":"green_8"}
{"index":{"_id":9}}
{"size":9, "name":"green_9"}
POST toy_demo_002/_search
{
"size":0,
"aggs": {
"max_agg": {
"max": {
"field"
:"size"
}
},
"min_agg":{
"min":{
"field":"size"
}
},
"avg_agg":{
"avg":{
"field":"size"
}
}
}
}
指标聚合结果如下:

指标聚合使用了浮点数,精度原因,所以和积木结果不完全一致。
有的读者说了,一个 stats 不就全搞定了,是的,如下:
POST toy_demo_002/_search
{
"size": 0,
"aggs": {
"size_stats": {
"stats": {
"field": "size"
}
}
}
}
stats 指标聚合结果如下:

更多指标聚合内容参见官方文档:Aggregations > Metrics aggregations。
3.3 管道聚合/子聚合(pipeline)
上积木:

图 9
图 9 的积木相对复杂了,有了:带孔积木,有了颜色区别,有了数字大小的区别。
按照有孔与否,聚合结果如下图 10 所示, 左侧有孔,右侧没有孔。

图 10
进一步,在图 10 的基础上,按照颜色分桶,结果如下图 11 所示。

图 11
再进一步,在图 11 的基础上,各自颜色桶内按照数字大小排序如下图 12 所示。
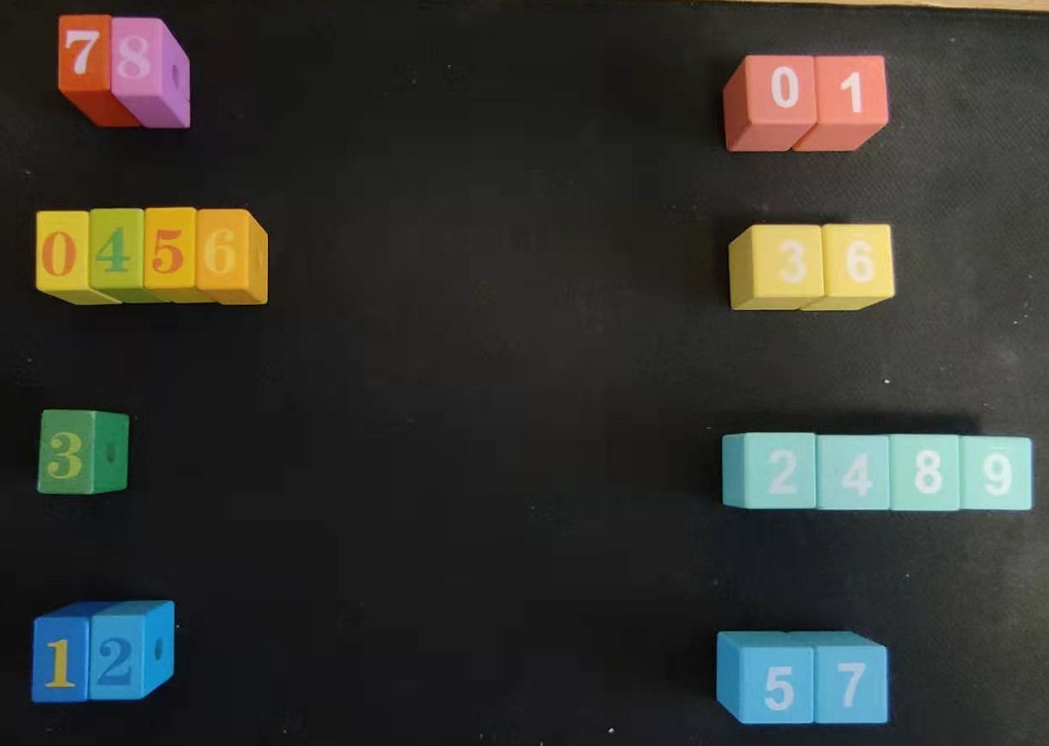
图 12
在图 12 的基础上,获取数字最大的值及其所在的桶,如下图 13 所示:

图 13
如下的数据建模,完整复现了图 9 - 图 13 积木组合。
- name:积木名称(以颜色+数字命名,以标定唯一)
PUT toy_demo_003
{
"mappings": {
"properties": {
"has_hole": {
"type": "keyword"
},
"color": {
"type": "keyword"
},
"size": {
"type": "integer"
},
"name": {
"type": "keyword"
}
}
}
}
POST toy_demo_003/_bulk
{"index":{"_id":0}}
{"size":0, "name":"red_0", "has_hole":0, "color":"red"}
{"index":{"_id":1}}
{"size":1, "name":"red_1","has_hole":0, "color":"red"}
{"index":{"_id":2}}
{"size":2, "name":"green_2","has_hole":0, "color":"green"
}
{"index":{"_id":3}}
{"size":3, "name":"yellow_3","has_hole":0, "color":"yellow"}
{"index":{"_id":4}}
{"size":4, "name":"green_4","has_hole":0, "color":"green"}
{"index":{"_id":5}}
{"size":5, "name":"blue_5","has_hole":0, "color":"blue"}
{"index":{"_id":6}}
{"size":6, "name":"yellow_6","has_hole":0, "color":"yellow"}
{"index":{"_id":7}}
{"size":7, "name":"blue_7","has_hole":0, "color":"blue"}
{"index":{"_id":8}}
{"size":8, "name":"green_8","has_hole":0, "color":"green"}
{"index":{"_id":9}}
{"size":9, "name":"green_9","has_hole":0, "color":"green"}
{"index":{"_id":10}}
{"size":7, "name":"red_hole_7","has_hole":1, "color":"red"}
{"index":{"_id":11}}
{"size":8, "name":"red_hole_8","has_hole":1, "color":"red"}
{"index":{"_id":12}}
{"size":0, "name":"yellow_hole_0","has_hole":1, "color":"yellow"}
{"index":{"_id":13}}
{"size":4, "name":"yellow_hole_4","has_hole":1, "color":"yellow"}
{"index":{"_id":14}}
{"size":6, "name":"yellow_hole_6","has_hole":1, "color":"yellow"}
{"index":{"_id":15}}
{"size":5, "name":"yellow_hole_5","has_hole":1, "color":"yellow"}
{"index":{"_id":16}}
{"size":3, "name":"green_hole_3","has_hole":1, "color":"green"}
{"index":{"_id":17}}
{"size":1, "name":"blue_hole_1","has_hole":1, "color":"blue"}
{"index":{"_id":18}}
{"size":2, "name":"blue_hole_1","has_hole":1, "color":"blue"}
以下聚合实现了:图 11的积木内容。
先按照是否有孔聚合,再按照颜色聚合。
这属于聚合内嵌套聚合,本质属于:分桶聚合章节内容,这里要说明一下。
POST toy_demo_003/_search
{
"size": 0,
"aggs": {
"hole_terms_agg": {
"terms": {
"field": "has_hole"
},
"aggs": {
"color_terms": {
"terms": {
"field": "color"
}
}
}
}
}
}
聚合结果如下:

以下聚合实现了图 12、图 13 内容(非严格匹配)。
- 嵌套在内层的聚合:取最大值,本质是取的有孔、无孔两个桶里的最大值。
- max_bucket 可以理解成子聚合或者pipeline 管道聚合,它是进一步再上面聚合的基础上,取出有孔、无孔两个桶的最大值及其最大值所在的桶。
POST toy_demo_003/_search
{
"size": 0,
"aggs": {
"hole_terms_agg": {
"terms": {
"field": "has_hole"
},
"aggs": {
"max_value_aggs": {
"max": {
"field": "size"
}
}
}
},
"max_hole_color_aggs": {
"max_bucket": {
"buckets_path": "hole_terms_agg>max_value_aggs"
}
}
}
}
聚合结果如下:

更多 pipeline 基于聚合的聚合内容参见官方文档:Aggregations > Pipeline aggregations。

小结
临时结合小朋友玩具,联想到 Elasticsearch 聚合问题。
聚合内容博大精深,我就只图解解了其中最基础的部分。
实战中经常用到的聚合重点见下面的脑图:
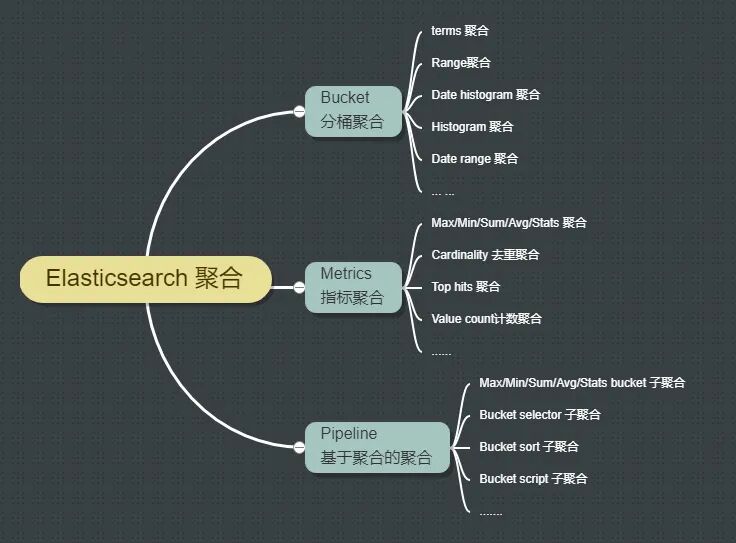
算作抛砖引玉吧,涉及聚合的更多细节还得结合官方文档去学习、去实践,相信有了积木的案例,后面再学习聚合会更好理解一些。
不知道本文是否讲透了聚合?欢迎留言反馈交流。
4月23日晚8点,欢迎来到CSDN直播间,与资深行业专家雷明老师一起探讨机器学习所必须掌握的数学知识。










