所以第一步便是准备一些训练素材了,比如类似这样的:

这里就需要把右侧的验证码缺口找出来,比如标注出目标滑块的左侧偏移位置。
所以,要训练深度学习模型,我们就需要很多样例图片对吧,所以像上一篇文章一样,我需要收集一些这样的图片,然后手工标注一些缺口位置,然后用于模型的训练。
不过,存在的一个问题就是,某验的背景图片花样太少了,就那么几种背景图,只是缺口位置变了变,所以它对于训练一个健壮的模型是不太够用的。
于是我就有了一个想法 —— 自己做标注数据。
也就是说我要自己生成一些类似上面的图片,顺便生成的过程就记录下来了目标滑块的位置了,顺便标注数据也就生成了。
思路
先看下最后我生成的效果吧:

就是这样的,这个图是用代码生成的。
其实很简单,这里就是生成一张背景图,然后贴上左侧和右侧的滑块就好了,左侧的就是源滑块,右侧就是缺口,二者的高度是一样的。另外观察下,左侧的滑块是有黑色阴影和黄色内阴影的,右侧的滑块是有黑色内阴影的。
那这个这么生成呢?
往下看。
获取滑块 RGB
首先,在制作之前其实我是不知道滑块的具体像素 RGB 值的,比如目标滑块我看到它似乎是个半透明的样子,还带有一些纹理,而且滑块和背景是融为一体的,我怎么把它抠出来呢?
比如就这张图:
我想单独把滑块和缺口对应的图层抠出来?怎么做到呢?直接抠可能比较难。
不过这里还有另一个信息,那就是我可以通过检查网页源代码拿到无滑块的原图,如图所示:

具体获取方法从源码里面把 CSS 样式改掉就好了:

所以,很自然地,二者像素做差就行了,代码如下:
import cv2
import numpy as np
image1 = cv2.imread('image1.png')
image2 = cv2.imread('image2.png')
sub = image1 - image2
cv2.imwrite('sub.png', sub)
OK,这里我们使用 cv2 把图片读取为 Numpy 数组,然后二者做差即可,结果如下:

可以看到我们就把二者的不同之处做出来了,比如纯黑色的就是完全一致的,带有一些彩色的可能是因为一些像素偏移导致的,当然最明显的就是两个滑块的的像素内容就单独提出来了。
和我们预估的一样,原始滑块就是带有黑色阴影和黄色内阴影,目标缺口就是带有黑色内阴影。
OK,接下来我就简单用 PS 大法把它们抠出来了,最后效果如下:


这里就是一张原始滑块图、一张目标缺口图,这样缺口图就准备好了。
生成验证码
有了缺口图,那怎么生成验证码呢?很简单,随便找点图,然后裁切成想要的大小就好了。
比如这里就有一张图:

我们就用这张图生成验证码,写个算法裁切一下,裁切成想要的大小:

然后再把刚才的两个滑块和缺口图贴上就好了。
那具体裁切的算法这么写呢?比如扁平的图应该以高为基准放缩,然后从横向中间裁切出来,比如竖高的图就以宽为基准方所,然后纵向从中间裁切出来。这里我先收集了几十张背景图,大小各异:
可以看到有长的、有方的、有竖的、有扁的。
裁切算法实现如下:
import cv2
import os
import numpy as np
from loguru import logger
CAPTCHA_WIDTH = 520
CAPTCHA_HEIGHT = 320
for root, dirs, files in os.walk('input'):
for file in files:
image_path = os.path.join(root, file)
logger.debug(f'image path {image_path}')
image = cv2.imread(image_path, cv2.IMREAD_UNCHANGED)
image_height, image_width, image_dim = image.shape
if image_dim == 3:
b_channel, g_channel, r_channel = cv2.split(image)
alpha_channel = np.ones(b_channel.shape, dtype=b_channel.dtype) * 255
image = cv2.merge((b_channel, g_channel, r_channel, alpha_channel))
if image_width / image_height > CAPTCHA_WIDTH / CAPTCHA_HEIGHT:
image = cv2.resize(image, (int(CAPTCHA_HEIGHT * image_width / image_height), CAPTCHA_HEIGHT))
image_height, image_width, _ = image.shape
image = image[:, int(image_width / 2 - CAPTCHA_WIDTH / 2): int(image_width / 2 + CAPTCHA_WIDTH / 2)]
else:
image = cv2.resize(image, (CAPTCHA_WIDTH, int(CAPTCHA_WIDTH * image_height / image_width)))
image_height, image_width, _ = image.shape
image = image[int(image_height / 2 - CAPTCHA_HEIGHT / 2): int(image_height / 2 + CAPTCHA_HEIGHT / 2), :]
cv2.imwrite(f'output/{file}', image)
logger.debug(f'finish output/{file}')
这里就是读取了 input 文件夹下的所有文件,然后根据长宽比进行了裁切,然后将裁切的结果输出到 output 文件夹,裁切结果如下图所示:
合成验证码
好,现在已经有了合适的验证码背景图了,下面就是拼合一下滑块就好了。
滑块图片命名为 block_source.png,目标缺口图片命名为 block_target.png,合成的时候需要注意位置的随机性,比如上下的随机偏移,但也需要控制下滑块的位置,比如源滑块和缺口的高度需要是一直的,缺口应该出现在图片中,而不能跑出去。
最后实现合成算法如下:
import os
from PIL import Image
import random
import glob
from loguru import logger
CAPTCHA_WIDTH = 520
CAPTCHA_HEIGHT = 320
image_source = Image.open('block_source.png')
image_target = Image.open('block_target.png')
label_offset_x_base = 260
label_offset_y_base = 120
count = 0
total = 1000
root_dir = 'output'
file_paths = glob.glob(f'{root_dir}/*.png')
while True:
file_path = random.choice(file_paths)
offset_y = random.randint(-100, 100)
offset_x = random.randint(-100, 100)
label_offset_x = label_offset_x_base + offset_x
label_offset_y = label_offset_y_base + offset_y
image_path = os.path.join(file_path)
image = Image.open(image_path)
image.paste(image_target, (offset_x, offset_y), image_target)
image.paste(image_source, (0, offset_y), image_source)
label = f'0 {label_offset_x / CAPTCHA_WIDTH} {label_offset_y / CAPTCHA_HEIGHT} 0.16596774 0.24170968'
image.save(f'captcha/images/captcha_{count}.png')
logger.debug(f'generated captcha file captcha_{count}.png')
with open(f'captcha/labels/captcha_{count}.txt', 'w') as f:
f.write(label)
logger.debug(f'generated label file captcha_{count}.txt')
count += 1
if count > total:
logger.debug('finished')
break
这里设定了生成 1000 张图片,然后通过 offset_y 和 offset_x 来控制目标缺口的位置,读取图片之后,通过 image 的 paste 方法指定对应的位置即可,标注结果根据偏移的像素值自行计算。
最后生成到 captcha 文件夹里,images 就是验证码图,labels 就是标注结果,如图所示:
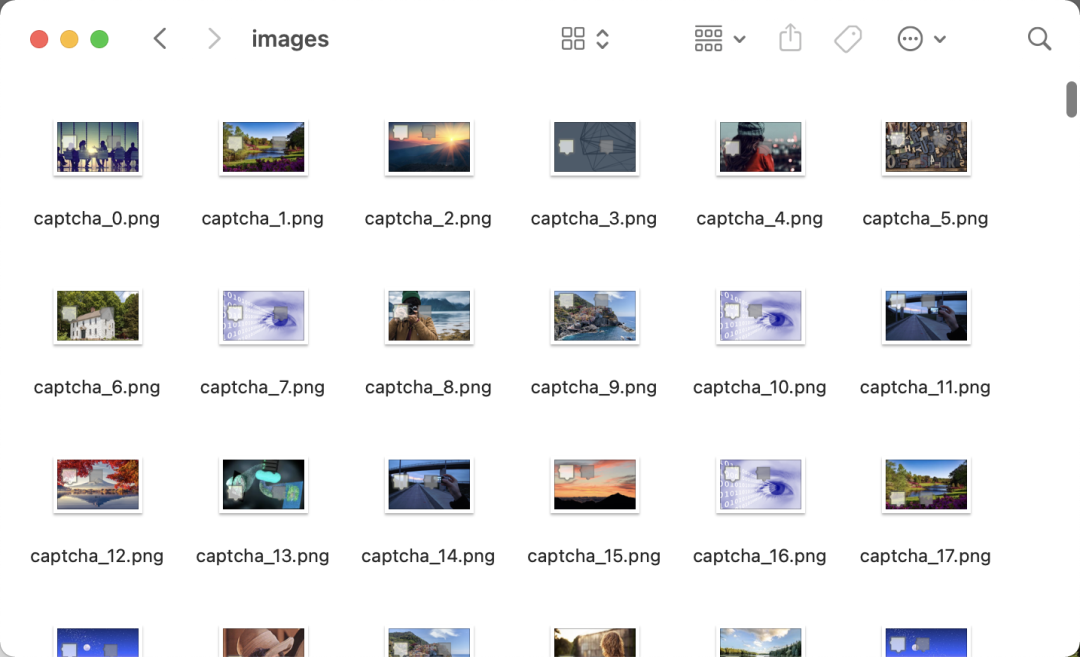
样例验证码如图所示:



这样,背景图片足够丰富,那就足够支撑训练验证码识别模型了,模型也会更加健壮。
训练结果
具体的训练结果我就不赘述了,大家可以参考 https://github.com/Python3WebSpider/DeepLearningImageCaptcha2。
看下模型识别结果:



识别准确率很高,可以完美把想要的缺口标注出来,大功告成。
后记
另外发现缺口的形状也对识别效果有一定的影响,所以滑块和缺口图片也需要多弄几种类型,使模型更加健壮。
- EOF -
觉得本文对你有帮助?请分享给更多人
推荐关注「Python开发者」,提升Python技能
点赞和在看就是最大的支持❤️










