点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
编辑:中国统计网
在一场科技会议上,演讲者询问观众,“有谁为自己的业务开发过机器学习或者人工智能模型?”80%到90%的人都举起了手。
“那么,你们当中有谁将它投入生产了呢?”演讲者继续发问。几乎所有的人都放下了手。显而易见,几乎每个人都想在他们的业务中引入机器学习,但是这些人也遇到了一个大问题:让模型可持续发展十分困难,尤其是在云架构的基础上。
medium上一位博主也指出了这个问题,并提出了将机器学习模型投入生产的4个常见陷阱。
不要重新造轮子
大家对这句话早已耳熟能详,却并没有什么改进,我们可以看到过太多因为拒绝使用已有的解决方案而失败的案例。
比如,Amazon Web Services(AWS)和Google Cloud有着性能强大的机器学习套件和产品,且简单易用,虽然他们不适用于每个案例,但是它们绝对是很好的一个入门平台,特别是当公司员工没有丰富的机器学习经验的时候。
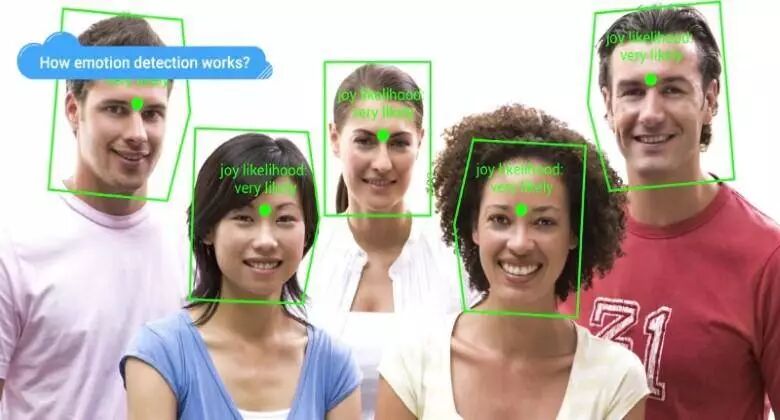 使用Google Vision API进行情感检测,图片来自TheNextWeb
使用Google Vision API进行情感检测,图片来自TheNextWeb
上面就是可以利用Google Cloud的Vision API提取信息的一个示例。假设有顾客对产品的反映的图片或者视频的数据,并且想根据他们的面部表情来了解他们对产品的态度。那么就可以简单地将图片或者视频作为数据提交给Google Vision进行处理,从而得到每张脸所呈现的大致情绪。
通常,AWS和Google Cloud上的产品的性价比就已经不错了。此外,由于平台会处理版本更新,功能添加等问题,因此维护工作也十分简单。
对于较小的项目,这种简单易行的方法可能足矣。但是对于更大的项目而言,要么成本过于昂贵,要么需要更多的自定义功能。
这种项目通常需要定制解决方案。就像之前提到的,有许多项目因为做得太多而失败,同样地,也有许多项目因为做得太少而失败。我们需要保持“增量收益”的心态,即在不牺牲长期目标的前提下从我的产品中尽可能多地提取短期价值,但有时这种行为会破坏产品设计。
可以通过下述途径来解决这个难题:
(1)确保足够了解当前问题以及期望的业务价值
(2)进行必要的研究。
对于第一种途径,如果团队一开始就在技术细节上陷入困境,那么很可能见树不见林。你必须时刻提醒自己“我真正想要完成的是什么?”
第二种途径稍微有点复杂。可以先在谷歌学术上进行研究,梳理一下相关的学术出版物或博客文章,看看别人是如何解决我遇到的问题的。如果没有满意的结果,那么接下来试着找下相似的问题(可能是不同领域),直到找到一个不错的线索。届时,再寻找现成的解决方案,看看它们能否满足需求。
如果满足的话就实施该方案。如果不能,就需要构建更多的自定义项。

在开发出一个很棒的解决方案之后,很多时候我们忘了这些模型固有的风险。当人们说“我们并不真正理解模型是如何工作的”,某种程度上来说确实如此。可解释的AI是一个快速发展的领域,致力于确切地回答这类问题:“为什么这个模型是这样运行的?”
但是当我们能够确切解释模型是怎样运行这个问题之前,我们不得不采取一些必要的预防措施。
了解模型之间的特征和相关性
通常,我们不希望我们的模型基于种族、性别、收入水平等因素进行决策,所以我们不将它们作为输入。这样就万事大吉了吧?不一定。我们必须确保这些因素不会渗入到我们正在使用的其他特征中。例如,邮政编码是一个很强的人口统计指标,据此可以推断其所在区域。因此,在每个项目开始之前,我们必须花大力气来探索数据。
是否允许模型在生产中不断发展?
当我向一些人提到“机器学习”时,他们通常认为那就是说模型会随着人机交互而实时变动。虽然有些模型做到了这一点(改天撰文详谈),但是也有很多模型并没有做到,而且理由很充分。即使缺少必要的检查和监控,在输入数据急剧变化的情况下,模型也不会失控。
但事实并非如此。假设你有一个根据市场趋势动态更新的股票交易模型。在正常的市场中,它的效果很好,但是如果发生了某些不可预测的事(通常会在最糟糕的时候发生),模型可能会为了适应新环境而过度补偿,从而完全放弃了原先训练的策略。
这个问题并没有标准答案。它完全取决于你的问题和建模技术,但是尽早弄清这一点还是很重要的。你应该有一个标准的更新方法和策略,原因很简单:你怎么知道你的模型是在提升还是在下滑?
假设我有一个75%准确率的模型投入了生产。我怎么确定准确率是75%呢?通常,我会使用部分历史数据作为验证集(通常是20%)进行验证。
现在假设我一个月后更新了模型,发现我的准确率居然达到了85%(多棒,快夸夸我)!于是我很开心地将更新推送到了平台上。但是,我突然发现结果大幅度下降了,我的客户也不停地抱怨。到底啥情况?
原因很简单:如果我没有保存我的验证集(用来测试准确率的原始数据),那么我就不是拿苹果和苹果进行对比了。我不能确定更新后的模型性能是否比初始模型要好,这就会引起很多麻烦。
尽管这么说有点伤人,但是这很可能是你阅读本文后的最大收获。尽管机器学习被认为是当今计算机科学最酷的领域之一,但人们往往会忽略这样一个事实:它只是皮带上的工具,并不是皮带本身。
你不会用手提钻来钉钉子,所以当你能用基本的Python脚本完成任务时,不要使用机器学习。能够使用尖端技术对我们来说诱惑力太大了,我也深知这一点,但是如果没有必要的专业知识,你可能会造成不必要的失败。
我见过太多这样的例子了,人们在设计产品之前往往进行这样的头脑风暴:“我们怎样使用一个聊天机器人?”,“你认为我们可以用面部识别做些什么?”……但是事实是,这些想法基本上都没啥用。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~












