pdf文件是办公中非常常见的文件,而且为了保密,常常加水印并且加密,你无法直接复制内容出来。
直接复制出来的效果如图所示。
贯,署,纵,川(:)2022 。一、工作思路2022 “”。:“、聚焦”“1 2333”,绕,“41 2”
通常情况下pdf转word可以直接用word打开pdf文件,另存为word来解决。
import win32com.client as win32import os word = win32.gencache.EnsureDispatch('Word.Application')word.Visible =Falseoutput = word.Documents.Add() output.Application.Selection.InsertFile('111.pdf')output.SaveAs('111.docx') output.Close()
然而强如微软出来的依然是乱码:

普通的pdf转word的python工具包同样无效。
from pdf2docx import Converterpdf_file = 'demo.pdf'docx_file = 'demo.docx'cv = Converter(pdf_file)cv.convert(docx_file, start=0, end=None)cv.close()
他的效果是将pdf每一页作为图片全部粘贴到word内,你同样达不到复制文字的效果。
这里我们唯一的办法就是利用python去掉水印并生成图片,再利用百度的ocr人工智能服务将图片精确转化为文字。
我们资料的水印如图所示。

我们用前面讲过的方法先把水印干掉再说。
资料有水印?不存在的,马上python表演消失术
from PIL import Imagefrom itertools import productimport fitzimport os
def remove_pdf(): page_num = 0 pdf_file = input("请输入 pdf 地址:") pdf = fitz.open(pdf_file); for page in pdf: pixmap = page.get_pixmap() for pos in product(range(pixmap.width), range(pixmap.height)): rgb = pixmap.pixel(pos[0], pos[1]) if(sum(rgb) >= 520): pixmap.set_pixel(pos[0], pos[1], (255, 255, 255)) pixmap.pil_save(f"pdf_images/{page_num}.jpg",quality=100,dpi=(1800,1800)) print(f"第{page_num}水印去除完成") page_num = page_num + 1
remove_pdf()
因为pdf转图片的时候,如果不设置参数,会非常的模糊,利用quality和dpi参数我们尽量把图片质量进行优化。经过实测,如果不优化,就连百度ocr有时候识别也犯迷糊。
此时我们得到了去除水印的高清图片,一共95页。
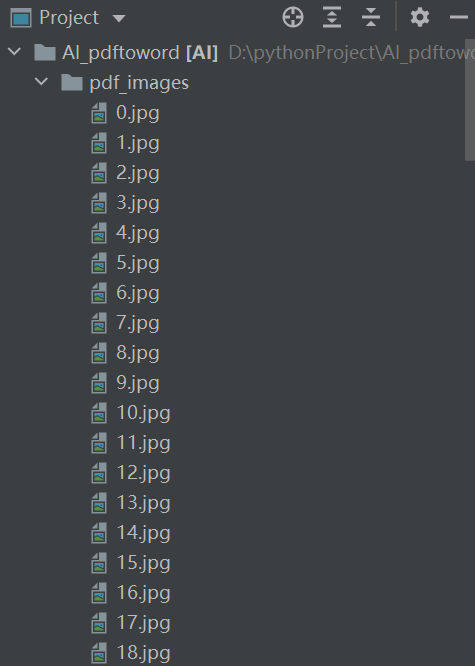
得到图片后,我们只需要一张张送入百度OCR模型进行识别,将输出的文字进行拼接,最后生成我们想要的txt或word就拿到了我们想要的文字。
首先进入自己的百度智能云后台,点击免费尝鲜把能领的api全部领了,这个api你不领,只会优惠越来越少。
在后台可以按照提示进行开发,首先领(白嫖)额度,创建应用,调用服务。
以前还可以免费领通用OCR场景和增值税发票的免费额度,现在都没有了,所以赶快领,不要有任何的迟疑。
通过查看api文件来领悟如何调用api。
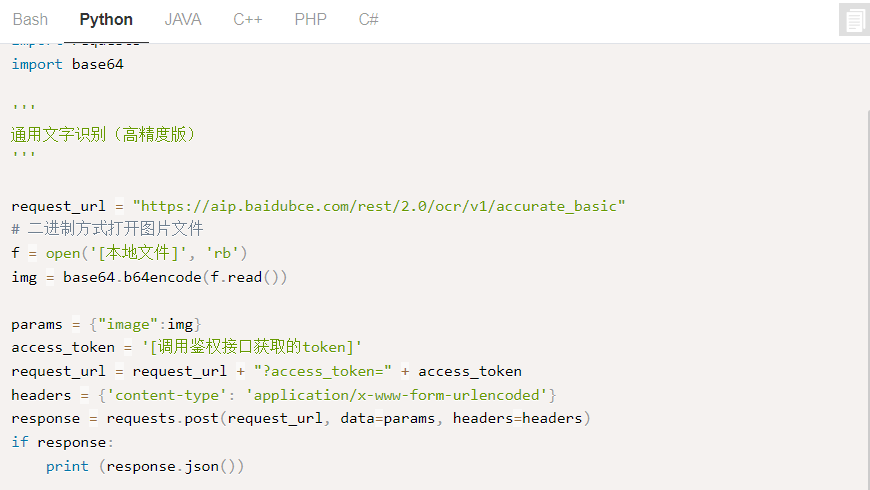
通过此段代码来拿到access_token。
import requests
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=你的ak(创建应用后看得到)&client_secret=你的sk(创建应用后看得到)'response = requests.get(host)if response: print(response.json())

拿到access_token后就可以利用循环调用api识别95次,再把文字拼接起来就完成我们pdf转文字的任务了。
import requestsimport base64
page_num=0words = []
for i in range(96):
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
f = open(f"pdf_images/{page_num}.jpg", 'rb') img = base64.b64encode(f.read())
params = {"image": img}
access_token = '[刚才拿到的access_token复制到这里]' request_url = request_url + "?access_token=" + access_token headers = {'content-type': 'application/x-www-form-urlencoded'} response = requests.post(request_url, data=params, headers=headers)
words_result = response.json()['words_result']
for i in range(len(words_result)): words.append(words_result[i]['words'])
page_num+=1
print(''.join(words))
with open("test.txt","w") as f: f.write(''.join(words))
运行完程序后,我们就将一个带水印且加密了的pdf完全转换成txt纯文本了,经测试,只要你图片质量高,那识别率就是100%。
只要你看懂了这个例子,你就可以利用百度智能云上面的免费api为所欲为了。
看懂的一键三连,没看懂的收藏后慢慢看。

-
- 机器学习交流qq群955171419,加入微信群请扫码











