- Python3.6.5
- OpenCV-Python 4.x
- Tesseract-OCR 5.0.0-alpha.20201127
- Win10 64
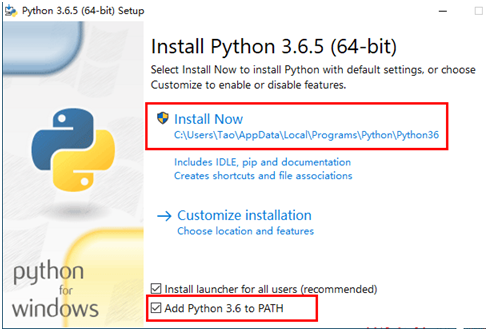
安装Python SDK选择默认安装,同时勾选最下面得红色矩形框内容。
安装opencv-python开发包
pip install opencv-python
安装Tesseract-OCR Python SDK支持
下载Tesseract-OCR 5.0.0-alpha.20201127安装包并安装!然后在环境变量中添加
C:\Program Files\Tesseract-OCR
安装与配置好OpenCV-Python与Tesseract-OCR之后,需要进一步通过代码验证正确性。打开Pycharm IDE,新建一个python项目与python文件,输入以下代码
import pytesseract as tessprint(tess.get_tesseract_version())print(tess.get_languages())
运行结果如下:

第一行是版本信息,第二行是支持的语言信息,默认只支持英文。
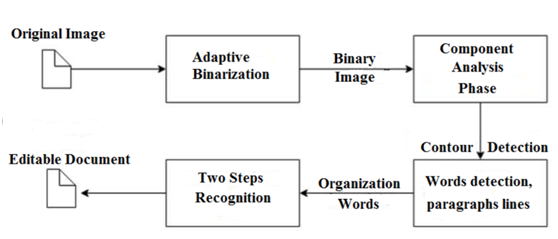
开源的OCR识别引擎,高版本识别基于LSTM,其整个处理流程如下:
检测与识别文本函数:
检测:
def image_to_boxes(image,lang=None,config='',nice=0,output_type=Output.STRING,timeout=0,)
返回所有识别文字的Box框坐标,每一行为一个BOX信息输出
每行的前五个值分别是,识别的字符、BOX框的左上角与右下角坐标
识别
def image_to_string(image,lang=None,config='',nice=0,output_type=Output.STRING,timeout=0,)
输入的图像通道顺序是RGB,OpenCV默认为BGR,返回的是识别结果
必输入的参数是image,其它可选
Tesseract-OCR默认支持英文与数字识别,有输入图像如下:
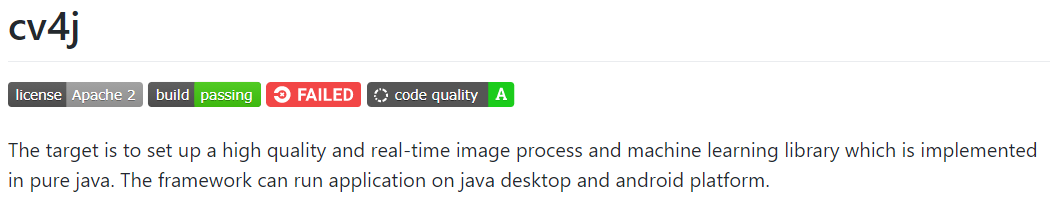
Python代码如下:
image = cv.imread("D:/cv4j.png")
image_rgb = cv.cvtColor(image, cv.COLOR_BGR2RGB)
text = tess.image_to_string(image_rgb, lang="eng")
content = text.replace("\f", "").split("\n")
for c in content:
if len(c) > 0:
print(c)
h, w, c = image.shape
boxes = tess.image_to_boxes(image)
for b in boxes.splitlines():
b = b.split(' ')
image = cv.rectangle(image, (int(b[1]), h - int(b[2])), (int(b[3]), h - int(b[4])), (0, 255, 0), 2)
cv.imshow('text detect', image)
cv.waitKey(0)
cv.destroyAllWindows()
运行结果如下:
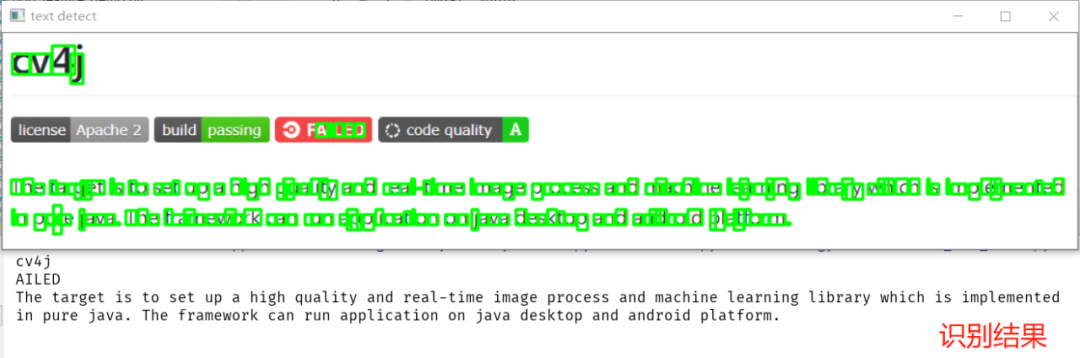
英文识别对无干扰的背景效果非常好!
默认情况下Tesseract-OCR不支持中文识别,需要下载中文识别的模型文件,然后放置到安装路径的tessdata目录下:
C:\Program Files\Tesseract-OCR\tessdata
然后在运行语言检查支持代码,运行结果如下:

其中chi_sim表示中文简体支持,eng表示英文支持!
以下图为例:

识别代码
image = cv.imread("D:/yanxishe.png")
image_rgb = cv.cvtColor(image, cv.COLOR_BGR2RGB)
text = tess.image_to_string(image_rgb, lang="chi_sim")
print(text)
h, w, c = image.shape
boxes = tess.image_to_boxes(image)
for b in boxes.splitlines():
b = b.split(' ')
image = cv.rectangle(image, (int(b[1]), h - int(b[2])), (int(b[3]), h - int(b[4])), (0, 255, 0), 2)
cv.imshow('text detect', image)
cv.waitKey(0)
cv.destroyAllWindows()
运行结果
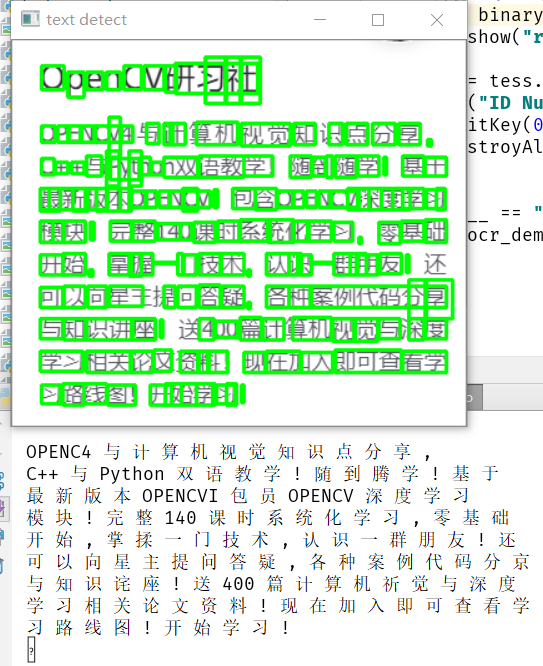
正确率还不错,需要进一步处理一下,直接放大两倍,然后再测试一波
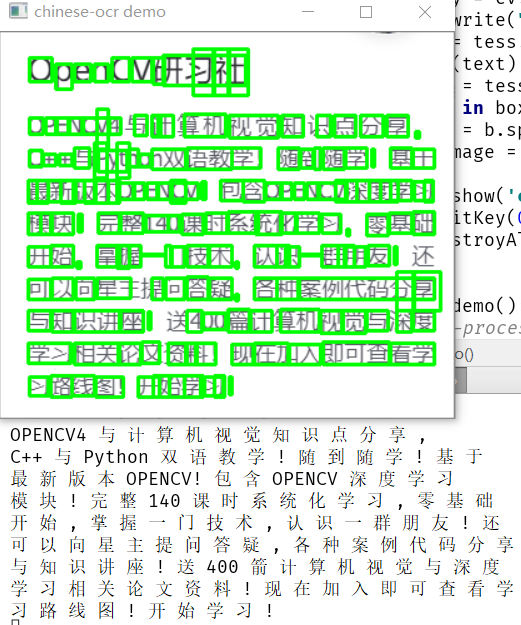
发现错误识别大大减少,基本可用!
总结一下:使用OpenCV预处理可以大大降低Tesserct-OCR的误识别率!
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~













