机器学习方法是每一个生物信息从业人员都绕不开的能力要求,可以说生物信息领域研究,对生物医学数据的挖掘和解析大都得益于有效的机器学习算法的选择和应用。随着近年来计算机算力的提升和硬件发展,机器学习的重要分支——以神经网络为基础的一众深度学习模型再度走进大家的视野,并且在生物医学研究领域取得了广泛应用和迅猛发展。深度学习模型避免了人为干预的特征选择过程,能够自行完成对原始数据特征的表示学习,从而提取有效的特征,这一点对于识别有效的生物标志物十分关键,已经在复杂疾病诊断、预测和预后相关领域取得了广泛应用。
目前,已经有不少的研究者开始探索将深度学习模型应用于开发精准的生物标志物,帮助有效的疾病管理。发表在Genomics Proteomics Bioinformatics(Q1)的研究Denoising Autoencoder, A Deep Learning Algorithm, Aids the Identification of A Novel Molecular Signature of Lung Adenocarcinoma. 就给我们提供了很好的借鉴思路。作者采用无监督度学习算法,自编码器(Auto decoder)模型的拓展模型——去噪自编码器(Denoising Autoencoder)直接处理高维的基因表达特征,从而构建鲁棒的疾病生物标志物。自编码器(Auto decoder)是一种较为成熟的无监督深度学习算法,能够基于反向传播与最优化方法算法,利用输入数据本身作为监督,完成原始特征矩阵的非线性特征转换,提取的低维特征能够较好的反映原数据的特征。去噪自编码器是自编码器的拓展模型之一,会在输入数据中引入噪声,从而迫使编码器的隐藏层捕捉更鲁棒的特征。生物标志物的构建流程如下:
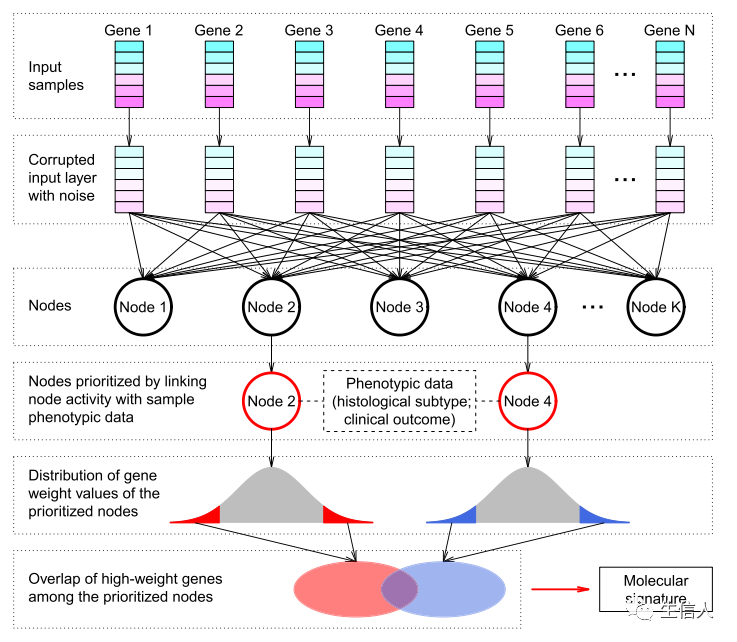
接下来我们借鉴该研究机器学习的方法设计了创新性新思路,对分析方法创新性、文章水平有更高要求的粉丝们要注意记笔记了!

机器学习个性化定制服务扫码占位
一、 构建去噪自编码器模型,进行特征提取
1、系统收集疾病样本的转录组数据,进行多套数据ComBat批次矫正后整合。统计收集样本的组织学亚型,给出临床信息的统计表格。
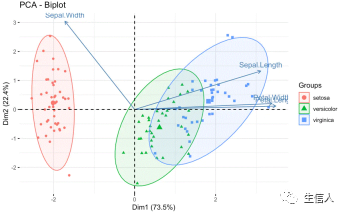
2、基于整合后的表达谱进行PCA降维,观察不同数据集之间是否仍有显著差异。
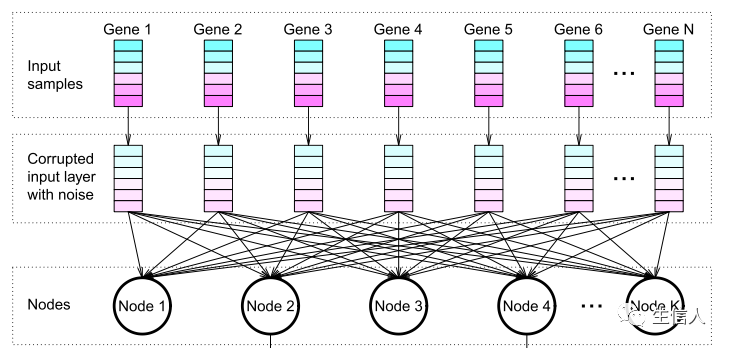
3、基于ADAGE package构建去噪自编码器模型(DAE)。提取特征节点。
二、 筛选预后相关特征节点
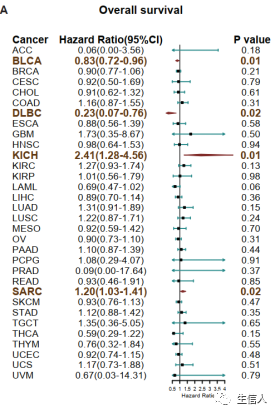
基于特征得分的特征矩阵,计算每个节点的特征得分与患者OS的关联筛选预后相关的特征节点,绘制森林图。并基于每个节点的特征得分的中值分类样本,绘制K-M曲线和log-rank检验。
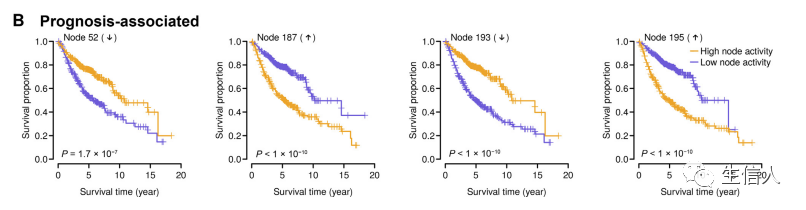
三、 探究预后相关特征节点的临床可解释性
探究肿瘤亚型、性别、分期、年龄分组等临床特征分组之间特征得分是否显著差异。
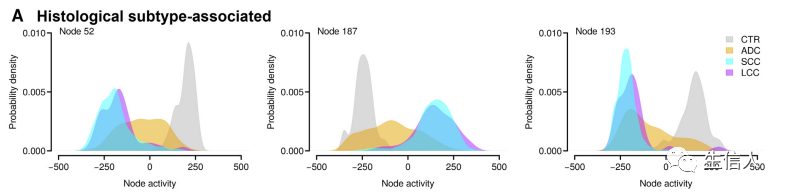
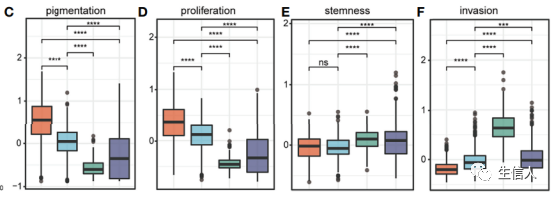
四、 探究预后相关特征节点的生物学解释性
1、 探究基因组层面的关联:探究预后相关特征节点得分与肿瘤突变负荷、同源重组修复缺陷得分(HRD),拷贝数变异负荷,瘤内异质性得分的相关性
2、 基于MSigDB 获得cancer hallmarks基因集合,基于ssGSEA计算hallmarks得分,计算预后相关特征节点得分与cancer hallmarks的关联情况
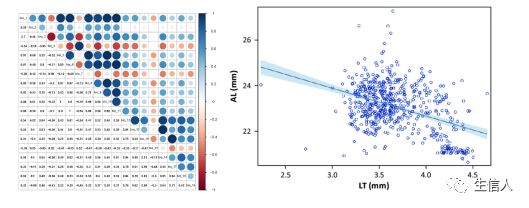
五、 探究特征节点反映的肿瘤免疫(代谢/调控机制)特征
这部分可根据研究关注点以及四中观察到的关联进行灵活调整,是一个深入分析。
以肿瘤免疫特征为例。
1、探究特征节点得分与免疫检查点基因表达水平的关联(spearman)
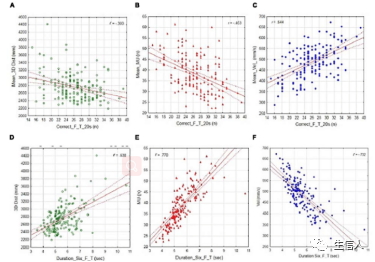
2、基于CIBERSORT或XCell计算免疫细胞浸润,与预后相关节点的关联分析。

六、 基于关键特征节点构建疾病标志物
1、提取关键特征节点
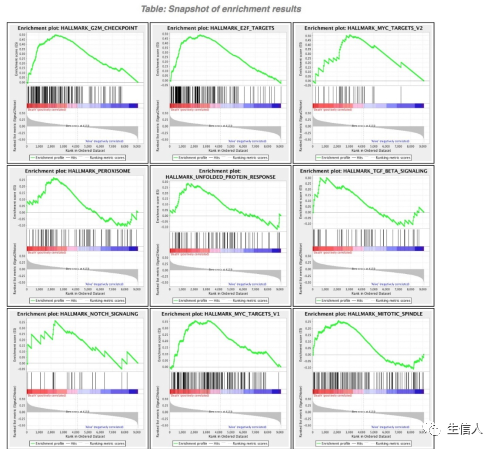
2、提取权重top100的基因进行功能富集。
3、进一步基于生存时长中值分组样本,保留生存分组之间表达差异显著的基因。
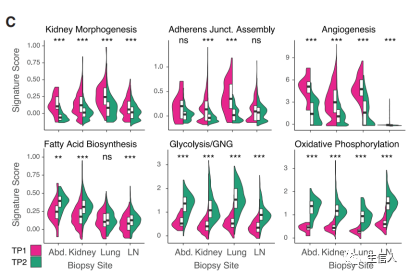
4、构建具有可推广性的预后特征:基于过滤得到基因的表达值与对应在特征节点权重乘积之和作为特征得分构建预后标志物。
七、 标志物的预后效能
训练集、独立验证集,基于单因素、多因素Çox 和 log-rank检验验证预后标志物的效能。
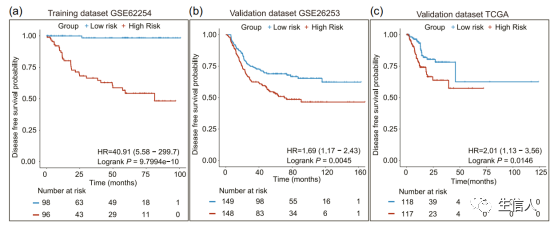
该思路利用成熟的自编码器深度学习模型,对原始的组学数据进行特征提取,并基于基因在新特征空间的映射,开发有效的组织分型和预后标志物。机器学习挖掘手段是很有创新意义的,并且深度学习模型提取特征的也是很值得进一步拓展探究的方向。
深度学习模型提取预后特征
定制化思路
扫码领取
更多生信分析问题咨询:18501230653(微信同号)










