最近业务系统生产环境的IDB在执行事务的过程中出现了ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction 异常。通过相关资料的查询和了解,发现出现这个问题的原因是产生了悬挂事务。整个排查的过程也比较困难,因此和大家分享下排查问题的经过。如果文中有错漏的地方,欢迎大家指正。
首先介绍下事务的相关知识。什么是事务?事务就是用户定义的一系列数据库操作,这些操作可以视为一个完成的逻辑处理工作单元,要么全部执行,要么全部不执行,是不可分割的工作单元。事务的的四大特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。mysql innodb引擎是如何实现上面四个特性的?- 事务的原子性、一致性和持久性由事务的 redo 日志和undo 日志来保证。
mysql的锁主要分为 共享锁(S Lock)、排它锁(X Lock)- 共享锁(S Lock):共享锁又称为读锁,简称S锁,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到最新数据。但是不能执行Update、Delete操作。
- 排它锁(X Lock):排它锁又称为写锁,简称X锁,排它锁不能与其它锁并存,而且只有一个事务能拿到某一数据行的排它锁,其余事务不能再获取该数据行的所有锁。一旦有一个事务获取了该数据的排它锁之后,其余事务对于该数据的操作将会被阻塞,直至锁释放。常见的排他锁:行锁、间隙锁等等。
mysql的重要日志:redo log、undo log和binlog- redo log:重做日志,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log file),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都存到该日志文件中, 用于在刷新脏页到磁盘,发生错误时, 进行数据恢复使用。mysql在进行修改操作的时候并不是直接进行磁盘IO,因为那样效率太低。而是将修改操作写到缓存区(redo log buffer)中,再在适合的时机进行刷页。为了防止缓存区中的数据因为意外错误丢失,所以会将缓冲区的数据写入到redo 日志。
- undo log:主要记录的是数据的逻辑变化,为了在发生错误时回滚之前的操作,需要将之前的操作都记录下来,然后在发生错误时才可以回滚。undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。
- binlog: 归档日志,属于逻辑日志,是以二进制的形式记录的,用于记录数据库执行的写入性操作(不包括查询)信息。binlog不仅会记录insert操作,还会记录对应的反向操作delete,binlog提供基于时间点的数据恢复能力。binlog的主要使用场景:主从复制和数据恢复。对于数据恢复场景,我们可以通过使用mysqlbinlog工具来恢复数据。集团内的IDB的数据追踪功能也是利用binlog实现的,可用于找回被误操作的数据。
- 查询数据若Buffer Pool存在,则输出,不存在则读取磁盘中的数据并放入Buffer Pool;
- 更新操作,会先将数据的旧值写入undo log,以便回滚。(保证原子性);
- 将更新数据写入到Redo Log Buffer(内存中);
- 准备提交事务,会调用fsync将Redo Log Buffer的值刷入到redo log日志文件中,状态为prepare;
- binlog写入成功后,将redo log的状态变更为commit;
- 在合适的时间,将Buffer Pool的数据刷盘;
正常的事务流程 (人为控制事务提交):begin, rollback, commit。正常情况下的流程如下:
beginTransaction();----一顿操作-------if(操作成功) { commit();}else { rollback();}
试想一下,如果我们开启一个事务,但不rollback也不commit这个事务,会发生什么现象。答案是:事务将一直挂起,事务中获得的锁也不会被释放,其他事务也无法操作被锁定的数据,此时就产生了悬挂事务。伴随着悬挂事务的产生,通常会出现ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction 这个错误。下面举个简单的例子:
//事务1set @@autocommit=0;BEGIN;UPDATE student SET age = 11 WHERE id = 2;
//事务2set @@autocommit=0;BEGIN;UPDATE student SET age = 11 WHERE id = 2;
事务1会获得id=2的行锁,然后一直不释放,事务1的会话将一直存在。事务2也要获得id=2的行锁,这时,事务2开始等待id=2的行锁释放,到了默认的超时时间50s(mysql的默认超时时间参数:innodb_lock_wait_timeout=50),事务2抛出异常:ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction 。事务1除了人为commit或者杀死该进程,否则事务1的进程永远处于挂起状态(即sleep状态)。
▐ 悬挂事务产生的问题
如果一个数据库连接中开启事务且未显式提交或回滚,在不考虑其他因素的前提下,只有在连接断开的时候才会回滚或者将该事务的进程杀死,该事务才会被回滚。这样一来,悬挂事务将会带来两个非常严重的问题。
悬挂事务不回滚,随着用户操作越来越多,悬挂事务也会不断堆积,整张表被锁的数据行也会越来越多。最终会导致这个表被完全锁住。所有的后续事务都无法获取锁而导致获取锁超时,整个系统彻底崩溃。
悬挂事务回滚,当前这段时间内,用户提交的数据是无法找回的。参考上面的事务执行过程,这个事务其实是被认为失败了,被rollback掉了,也无法通过binlog找回丢失的数据。
在前半部分,我分享了有关悬挂事物的相关知识。下面我将分享一例生产环境中的关于悬挂事务的案例。
▐ 起因
某日中午,钉钉报警群里面开始零星出现 Lock wait timeout exceeded; try restarting transaction异常(如下图所示)。立即开始排查问题,到了下午的时候,钉钉报警群开始大量出现无法获得数据库链接和获取锁超时异常,系统开始出现用户无法提交数据的情况。我立即和团队内的小伙伴的开始紧急处理这个问题。


一开始的时候,通过查阅相关资料,已经定位到产生问题的原因是产生了悬挂事务。那么悬挂事务怎么产生的呢?Spring提供了两种实现事务的方式,@Transactional 注解 和 调用事务管理器的getTransaction方法。值得注意的是getTransaction需要自己控制commit和rollback逻辑。而@Transactional注解则不需要。我们立即排查了最近上线的几个需求是否使用了getTransaction这种人工控制事务的方式,因为手动控制事务的方式,极有可能会出现事务不commit的情况。通过排查,最近上线的需求没有使用getTransaction这种人工控制事务,初步排除是最近上线的需求导致的。
我们再次开始排查系统中使用了getTransaction这种人工控制事务的方式的代码,系统中大概有7-8处使用了这种方式,这些代码最后一次提交日期大概是2020年,大致走查下来,也没发现什么问题。其实很难通过这种方式排查出原因。
随着时间的流逝,由于悬挂事务的存在导致其他正常的事务也无法执行,数据库中的活跃会话越来越多,越来越多的用户无法提交数据。我们可以从活跃会话得到当前正在执行的sql,导致这些sql无法提交的原因是前面的悬挂事务导致的,无法从当前众多的活跃会话中提取到更多的有效信息。我们立即联系DBA,协助解决问题。DBA确认了悬挂事务的存在(部分事务执行了3个多小时一直未提交),由于这些进程处于sleep状态,DBA也无法找出关联的sql。事后,查阅了相关资料,发现下面的方法可以找出“可能”的悬挂事务。我们请求DBA将这些悬挂事务的进程全部杀掉(即使不杀掉,这些事务也无法被 commit)。
//查询mysql当前的所有进程SHOW PROCESSLIST;
//查询出执行时间超过10s未提交的事务SELECT t.trx_mysql_thread_id
,t.trx_state
,t.trx_tables_in_use
,t.trx_tables_locked
,t.trx_query
,t.trx_rows_locked
,t.trx_rows_modified
,t.trx_lock_structs
,t.trx_started
,t.trx_isolation_level
,p.time
,p.user
,p.host
,p.db
,p.command
FROM information_schema.innodb_trx t
INNER JOIN information_schema.processlist p
ON t.trx_mysql_thread_id = p.id
WHERE t.trx_state = 'RUNNING'
AND p.time > 10
AND p.command = 'Sleep'
随着悬挂事务的进程被清理掉之后,数据库活跃会话开始逐渐减少,系统开始正常工作。然而,好景不长,因为一直没找到产生悬挂事务的根源,大约10分钟后又开始出现了Lock wait timeout exceeded; try restarting transaction异常。我尝试从SLS日志(我们系统的所有日志均会被采集到SLS日志系统中)出发,看看能否找到错误日志从而定位到问题。我重点查看了系统恢复到再次发生问题的这段时间的所有日志,终于发现下图这个异常。其实这段时间内系统的乱七八糟异常信息很多。能重点注意到这个异常的主要的原因主要是在第2步的时候,我对这段代码(AddServiceToCart)有点印象,记得这段代码好像使用的是手动事务控制事务的。
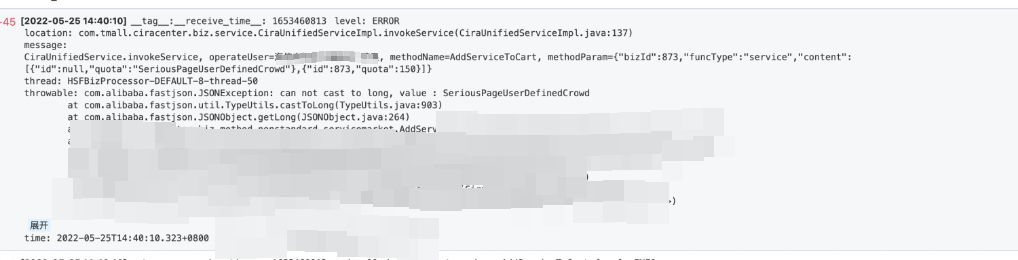
重点查看AddServiceToCart这段代码,立即发现问题。这段代码大致下面这样的方式实现的。
DefaultTransactionDefinition definition = new DefaultTransactionDefinition();TransactionStatus status = transactionManager.getTransaction(definition);Long quota = jsonObject.getLong("quota");transactionManager.commit(status);
在jsonObject.getLong("quota")时,quota不是Long型,jsonObject.getLong抛出RuntimeException,由于异常没有被捕获,事务的rollback和commit都没被执行,这样这个事务就会一直存在。除了应用重启和人工杀掉该事务的进程,让这个事务回滚,没有其他办法。而这样做带来的后果是这段时间内用户提交的数据都会丢失。如果想要找回,可能只能自己通过应用日志,自己将丢失的数据找回,然后人工将数据重新录入。通过mysql的binlog是无法直接找回的。
从前面的实践篇章节中,我们很容易知道两个事务要操作相同行的数据会产生锁等待的情况。那么是不是意味着上面的代码只会影响到自己事务里面的表呢?现在假设上面的代码只会用到A表,那么是不是同一数据库中的其他的B、C、D表是不是不受影响呢。先揭晓答案:会受到影响,B、C、D表的数据行也会被锁。这是为啥?
首先介绍一下Spring的事务的实现机制。
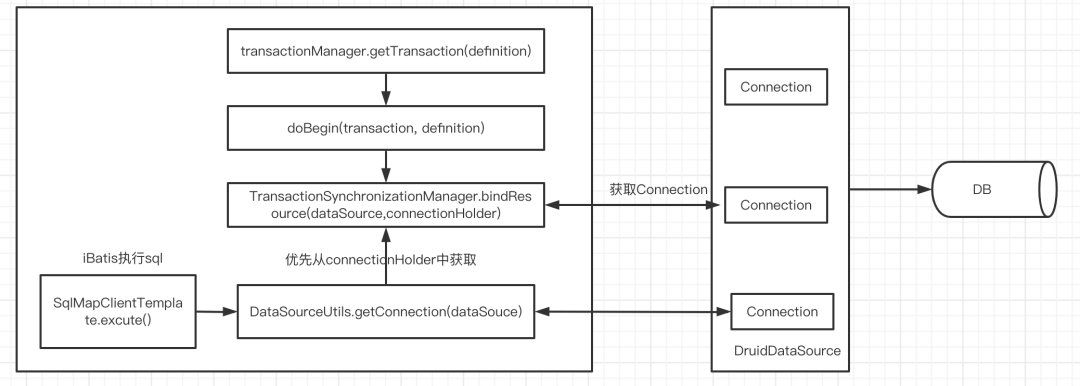
Spring事务是如何保证iBatis执行sql时,这些sql用的是相同的Connection?答案是:ThreadLocal。在执行完doBegin方法后,其实是通过bindResouce方法将从DruidDataSource连接池中获得的链接放入当前线程的TheadLocal,这里的TheadLocal中存放的是一个Map, key是dataSouce,value是connectionHolder(connectionHolder中持有Connection的引用。近似认为connectionHolder和Connection是一回事)。
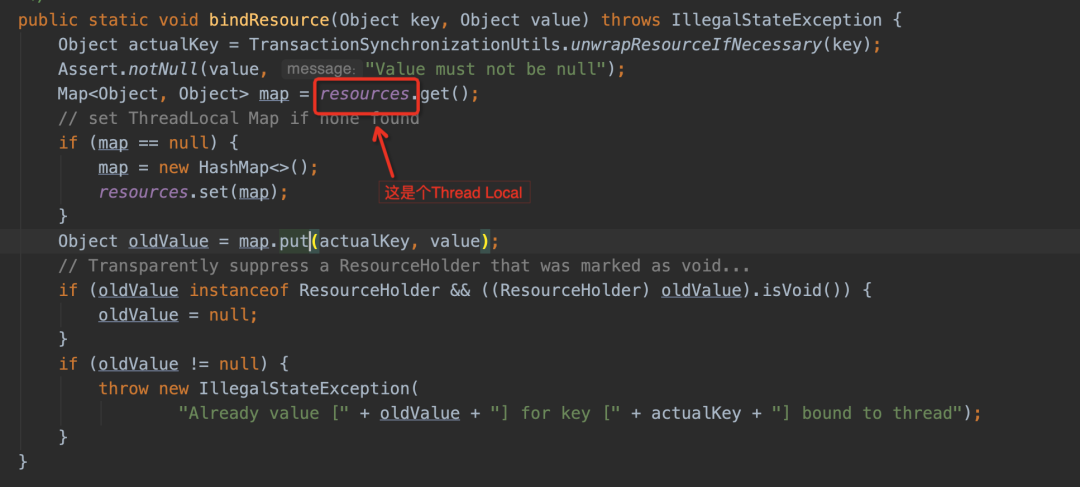
IBatis在执行sql时,通过DataSourceUtils.getConnection获取数据库链接。这里会优先从当前线程的ThreadLocal中获取,如果获取不到,从数据源中获取。
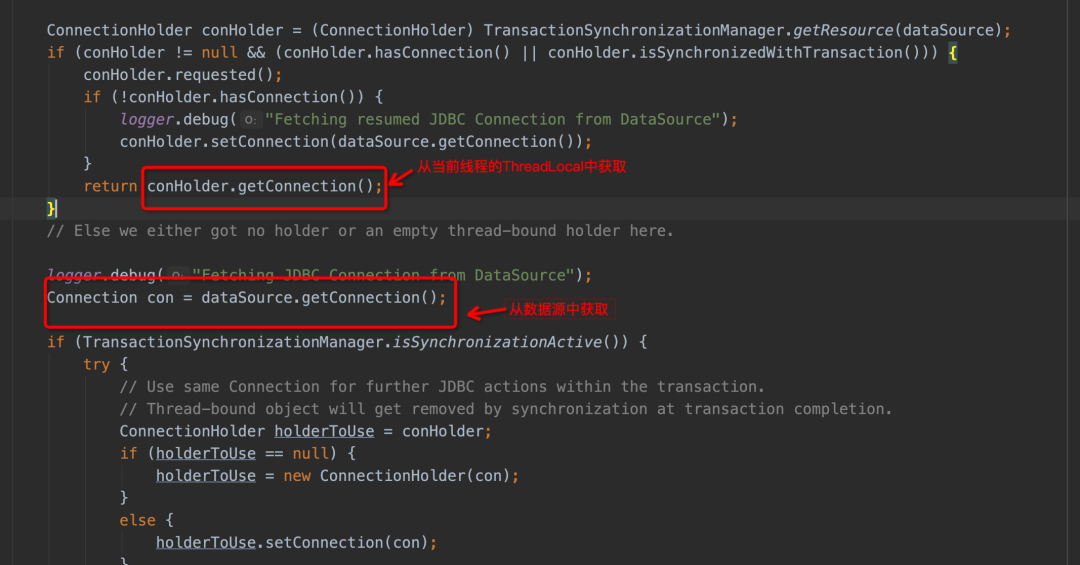
ThreadLocal中的变量什么时候会被清除呢?当commit和rollback的时候,ThreadLocal中的变量会被清理掉。
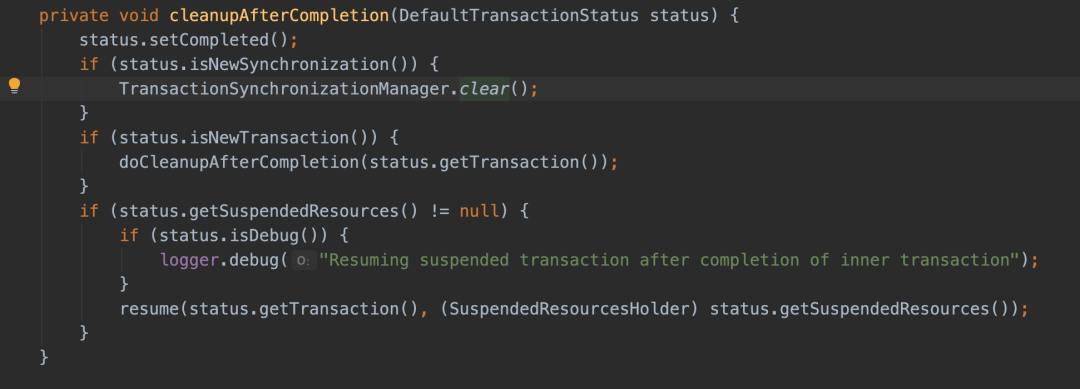
从上面的分析过程中,可以看出,当事务没有被commit和rollback的时候,当前线程可能会有上次残留的ThreadLocal的。因为当前线程是从线程池中获取的,线程是会被复用的。如果当前线程之前执行的事务没有被正确commit或者rollback的话,现在继续要获取链接并执行sql,由于上次是开启了事务且未提交,这次的sql也会被认为进入事务,这些sql也会锁住相应的数据行,这样就造成数据库中大面积的表被锁。
尽量不使用getTransaction这种人工控制事务(这种方式比较容易埋坑,推荐使用@Transactional ),如果要使用,请务必要try catch。一定注意提前return的问题(由于提前return导致rollback和commit都没被执行,这种case也很常见)。否则万一出问题,可能真的很头大;
参数校验一定要严谨,任何类型转化的地方不做类型检查可能都会产生异常;
我们是阿里巴巴大淘宝技术的新品平台技术团队, 依托于淘宝天猫正在建立一套完整的涵盖消费者洞察、宏观及细分市场分析、竞争分析、市场策略研究、产品创新机制等的新品研发和创新孵化平台, 为品牌、商家及行业提供规模化的新品孵化和运营能力, 沉淀新品孵化机制和运营策略, 最终建立起一套基于数据驱动的从市场研究、新品研发到新品投放营销的全链路新品运营平台。












