作者使用深度强化学习求解组合优化问题(routing problem、scheduling problem)
1、Solve routing problems with a residual edge-graph attention neural network ;
文章链接:
https://www.sciencedirect.com/science/article/pii/S092523122200978X ;
开源代码地址:GitHub - leikun-starting/DRL-and-graph-neural-network-for-routing-problems
大多许多组合优化问题都基于图结构,可以很容易地通过现有的图嵌入或网络嵌入技术来建模,将图信息嵌入到连续的节点表示中。图神经网络的最新发展可以用于网络设计,因为它在信息嵌入和图拓扑的信念传播方面具有很强的能力。这激励我们采用图模型来建立End-to-end的深度强化学习框架。旨在设计近似求解图组合优化问题的通用框架,该框架应用于不同的图组合优化问题只需要做细微的改动,图1概述了该框架的流程。TSP和VRP作为两个经典的组合优化问题,已经在物流运输、遗传学、快递和调度领域得到了广泛的研究。论文以TSP和VRP为求解对象来验证所提通用框架的有效性。
一般而言,TSP定义在一个有多个节点的图上,需要搜索节点的排列,以查找具有最短行驶距离的最优解。带容量约束的车辆路径问题(capacitated vehicle routing problem, CVRP)是VRP的一个重要变体,其要求在不违反车辆容量限制的约束下,寻找行驶距离最短的路径,并满足所有客户的需求。由于TSP和CVRP的NP-hard性质,即使在二维欧几里得的情况下也很难找到最优解。一般来说,这样的NP-hard问题可以表示为图上的顺序决策任务,因为它具有高度结构化的性质。
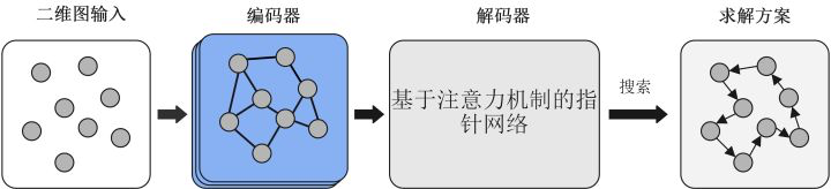
图4 所提出框架求解TSP的流程
本文设计的框架中,首先将问题的图表示(如TSP的节点坐标)输入到模型中,然后采用GNN对原始特征进行编码。在解码过程中,通过注意力机制预测未选择节点的概率。通过搜索策略基于该概率分布进行节点选择,如贪婪搜索或采样的解码策略。本文的编码器是对GAT的改编,改编版本考虑了图结构中的边信息和层之间的残差连接。本章将所设计的编码器网络称为残差-边-图注意力网络(residual edge graph attention network, RE-GAT)。除了对节点的原始状态进行编码外,RE-GAT还对边的信息进行编码更新。边的特征可以为学习策略提供与优化目标相关的更多的直接信息(如加权距离)。路径优化问题的目标是在相应的约束条件下寻找最短的加权路径,因为边提供的权重信息(本章选择图中节点之间的距离)不由节点提供。此外,同时输入节点和边缘信息有利于挖掘不同节点之间空间邻接关系的特征。本文的解码器是基于Transformer模型设计的。训练算法使用近端策略优化算法 (proximal policy optimization, PPO)和改进的REINFORCE算法。
所提出的框架无论在训练(training)还是在测试(testing/inference)阶段都具有线性(O(N))运行时间复杂度结合神经网络的批(batch)处理能力,能够非常快速的给出一个次优解,相比于启发式算法和精确算法都有一定优势,在运行时间和求解精度上属于trade-off。
具体方法实现和实验结论请参考原文链接。
2、A Multi-action Deep Reinforcement Learning Framework for Flexible Job-shop Scheduling Problem ;文章链接:https://www.sciencedirect.com/science/article/pii/S0957417422010624; 开源代码地址:https://github.com/leikun-starting/End-to-end-DRL-for-FJSP ;https://github.com/leikun-starting/Dispatching-rules-for-FJSP
柔性作业车间调度问题作为典型的NP-hard组合优化问题,目前其求解方法主要分为两类:精确算法和近似算法。基于数学规划的精确算法可以在整个解空间中搜索以找到最优解,但这些方法由于其NP-hard特性难以在合理的时间内解决大规模调度问题。因此,越来越多的近似方法(包括启发式、元启发式和机器学习技术)用于求解大规模调度问题。通常,近似方法可以在计算时间和调度结果的质量之间实现良好的折中,特别是群体智能(swarm intelligence, SI)和进化算法(evolutionary algorithm, EA),如遗传算法、粒子群算法、蚁群算法、人工蜂群算法等。
尽管与精确算法相比,SI和EA可以在合理的时间内解决FJSP,但这些方法并不能直接应用于求解产线实时运行需求下的大规模资源调度问题。基于优先级的启发式调度规则被广泛地应用于实时调度系统,例如考虑动态事件的调度问题。调度规则通常具有较低的计算复杂度,并且比数学编程和元启发式算法更容易实现。通常,用于解决FJSP的调度规则可以分为两个基本类别:工件选择规则和机器选择规则。这些规则的设计和组合旨在最小化调度目标,例如平均完工时间、平均延误、最大延误。然而,有效的调度规则通常需要大量的领域专业知识和反复试验,并且不能保证求解质量。
近年来,深度强化学习 (deep reinforcement learning, DRL)已广泛地应用于求解组合优化问题,为解决具有共同特征的调度问题提供了一种思路。然而,目前的工作主要专注于其他类型的组合优化问题,例如旅行商问题和车辆路径问题,对于更为复杂的调度问题如FJSP研究较少。
通常,常规的强化学习仅适用于单个动作的决策问题。其中,强化学习智能体与环境交互的方式为:智能体首先从环境中获取状态并根据该状态选择动作,然后获得奖励并转移到下一个状态。然而,在FJSP 中面临着工序的排序任务和机器的指派任务,即该问题是一个具有多动作空间的决策问题,这意味着常规的强化学习不能直接应用于FJSP。图5构建了 FJSP 的多动作空间的层级结构。在该层级结构中,强化学习智能体首先从工序动作空间中选择一个工序动作,然后从机器动作空间中选择一个机器动作。
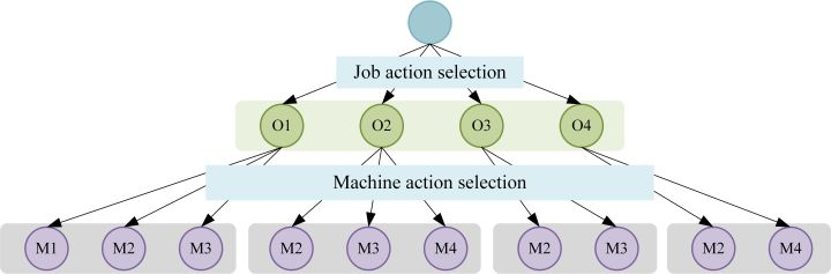
图5 FJSP的层级动作空间结构示意图
本文首先将柔性作业车间调度过程描述为多动作强化学习任务,并进一步将该任务定义为一个多马可夫决策过程(Multi-Markov Decision Process)。在此基础上,提出了一种新的基于GNN的多指针图网络(multi-pointer graph network, MPGN,如图6所示)用于编码嵌入FJSP的析取图(Disjunctive Graph)作为局部状态, 注:析取图作为调度过程中的局部状态提供了调度过程中的全局信息包含数值和结构信息,如工序优先级约束、调度后的工序在每台机器的加工顺序、每个工序的兼容机器集合以及兼容机器的加工时间等。
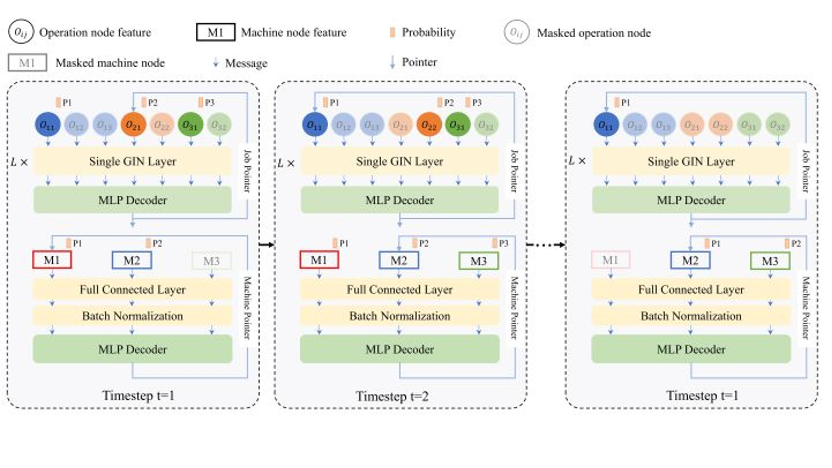
图6 MPGN wolkflow.
该网络适用于 FJSP、列车调度问题等多动作组合优化问题(结构如图7所示)。此外,为训练该网络结构设计基于actor-critic风格的多近端策略优化算法(multi-proximal policy optimization algorithm, multi-PPO)来训练所提出的MPGN。
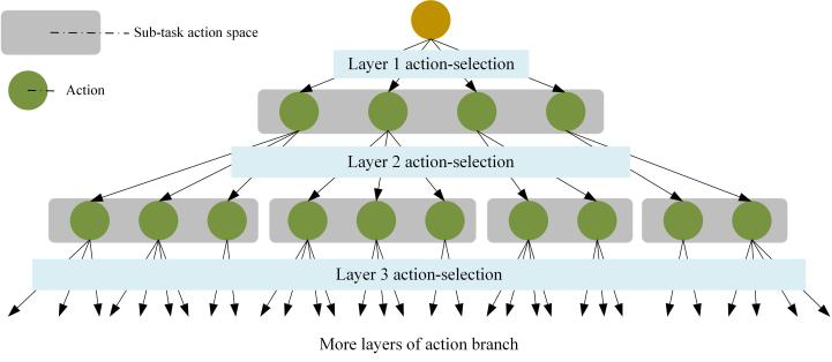
图7 多动作(任务)组合优化问题动作树状结构
具体实现细节及实验结论请参考原文链接。
#-------此外, 我们近期还投稿了使用分层强化学习(Hierarchical Reinforcement Learning)端到端地求解动态调度问题的文章,后续也会开源代码,大家感兴趣可以持续关注下








