截止2022.11.13,COCO数据集上最高精度为65.4mAP,InternImage杀死比赛。
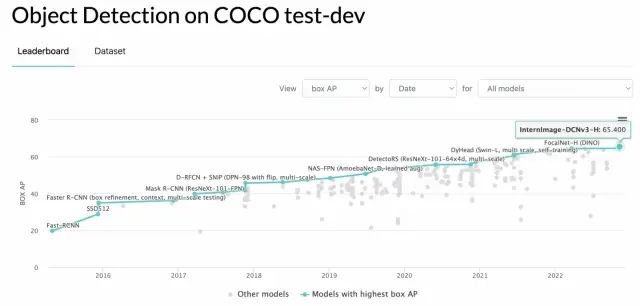
写到哪说到哪,近些年SOTA检测器是如何发展的,以及63mAP之后的检测器们(下文都以test-dev的精度为例)。
大概2021年,COCO数据集一直卡在61mAP,上不去了。这时候出来三种比较关键的做法:
引入图文的对比学习,增加图文数据,以GLIP为代表
增大模型规模,以SwinV2为代表
Objects365做预训练,以DINO为代表
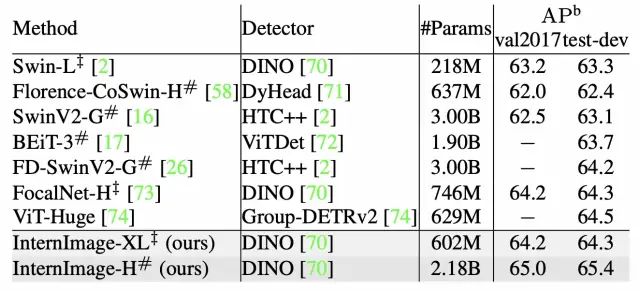
63mAP之后的发展,主要在三个检测器框架上展开的,一个是HTC++,一个是ViTDet,另一个则是DINO。
HTC++是Mask R-CNN检测器框架的加强版,在这个检测器框架之上,主流的做法是不断的扩展模型规模,或者是更好的预训练backbone,其中SwinV2-G通过模型规模,是第一个精度站上63mAP的检测器。而FD-SwinV2-G则沿用了SwinV2-G,用了更大规模的模型和更好的预训练,是第一个站上64mAP的检测器。但是SwinV2-G和FD-SwinV2-G的模型实在是太大了,3B的参数量啊!
ViTDet使用ViT-H作为backbone,只用COCO数据训练就可以达到61.6mAP,这应该是唯一一个只用COCO数据就能站上61mAP的检测器。但是ViTDet需要使用large scale jillter数据增强,并且需要训练100个epoch,这个训练资源是难以想象的(根据我的实验,即使是ViT-B,也需要16张A100训练3天,ViT-H根本不敢想)。BEiT-3则基于ViTDet,用了更多的图文数据训练,站上了63.7mAP,参数量需要1.9B!
而DINO检测器,得益于Deformable DETR的稀疏化设计,用SwinL作为backbone,只需要36个epoch和8张A100训练2天就能到58.5mAP。相比于ViTDet,算力要求上可小太多了。DINO在Objects365的预训练下,站上了63.3mAP,只需要218M的参数量!
DINO的63.3mAP在SOTA的位置大概保持了半年之久,这大概是从2015年至今,保持SOTA时间最久的检测器了吧。这其中大概有三点原因:
以SwinV2-G为代表的增大模型规模,基本饱和,并且没有更大的算力继续增加模型规模。
DINO没前几个月没有开源,没有更好的检测器框架刷点。
ViTDet虽然上限可能比DINO高,但是算力成本实在是太大了。
而随着DINO检测器在发表之后大概几个月之后,开源了代码,时间是2022年7月。
随后的几个月里,BEiT-3和FD-SwinV2-G用了更大的模型和更多的数据,才得以打败DINO。FocalNet-H和Group-DETRv2则基于DINO的框架,模型规模从200M量级提升到了600M量级,并且只使用Objects365作为额外数据,以更小的算力成本重返SOTA位置。
但是Group-DETRv2的SOTA只停留了大概2天。原本我以为64mAP这个级别上,还能再鏖战个小半年,但是InternImage的65.4mAP,直接杀死比赛,模型规模提高到了2.18B!这意味着没有同等算力的人不许入场。然而在600M的模型规模下,InterImage和FocalNet-H/Group-DETRv2几乎没有本质差别,也就是说收益基本上完全来自于模型规模的增加。
从2022年11月的这个时间节点来看,DINO之后,无论哪个检测器都没有框架设计上本质的改变,无非是更多的数据,更大的算力,更大的模型。要知道63 -> 64和64 -> 65不是一个概念的,63 -> 64,模型规模从200M提高到600M,而64 -> 65,模型规模从600M提高到了2B!要知道的是,在大模型面前,各种tricks基本上都会被抹平,600M模型规模下提升1个点,除非框架上有本质的变化。
未来想要在65mAP这个级别上继续提升精度,其实就两种路径了:
更多的数据、更大的算力、更大的模型
设计出更好的检测器框架
显然现在这两条路都不太容易了,想要比InternImage模型规模更大,基本上没有几个单位能做到,200M的模型规模需要至少32张A100 80G,600M就已经不敢想象了,更何况是2B!
而我在之前的文章中也提到过,检测器框架设计经过近些年的发展,各种排列组合基本上也已经摘的干干净净了。要不是DETR强行续命了2年,估计前两年就已经摘干净了。
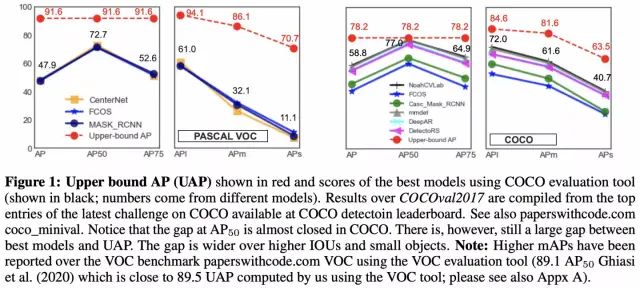
另外要说的是,2019年的一篇检测上限分析的文章中,通过将检测框crop出来,然后用resnet152额外训练一个分类器作为检测框的分类分数,以此作为上限(意思是分类足够准确的情况下,检测上限能到多少)。该文分析到,基本上AP50和APl快到上限了,而AP75和APs还差的比较多。
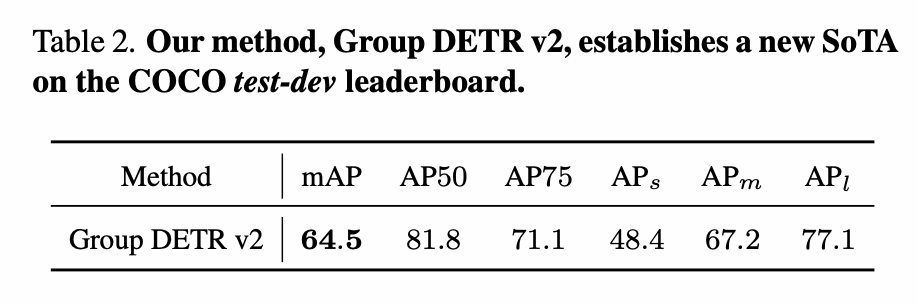
而Group DETRv2中report出来的最好结果,在AP50上则已经超过78.2的上限了。当然这里的比较是不严谨的,因为Group DETRv2的backbone用的是SwinL,用SwinL作为分类器理论上限会更高,而且Group DETRv2用了Objects365作为预训练,但是也基本能说明检测器在低质量框和大物体上基本已经饱和。
- 机器学习交流qq群955171419,加入微信群请扫码










