
统计学和机器学习为数据分析提供理论基础,入门时我看过很多统计学相关书籍,复杂的公式和推导过程让我一度陷入迷茫。对于数据科学/分析师来说,如何使用统计学知识并应用到我们的分析场景中更为重要。本文主要基于数据分析工作中的实际应用场景,分享一些魔法统计学/机器学习指数,对一些基础指数、原理及公式推导不过多阐述。
▐ 短期增速
一般增长率增速:超大盘增速 ;相对排名增速:排名增速
混合增速=GMV增速+相对排名增速
加权混合增速=指标增速*log(1+指标)
▐
长期增长趋势:CAGR复合增长率
CAGR是复合年增长率的缩写,它是一种衡量某个指标在一段时间内的平均增长率的方法。CAGR通常用于衡量投资回报率、销售增长率等指标。举例:开始值5,结束值20,年数2(包含首尾值),则复合增长率=100%。
数据分析的目的有三种:描述现状、定位原因和预测未来,趋势预测即在分析过去和现在的数据,进而预测未来的过程,辅助作出决策。
▐ 线性趋势预测:Forecast.linear()
它通过使用现有或过去的值来预测或计算值。基于线性回归函数通过自变量x值来预测y。如果数据中存在线性趋势(即y线性依赖于x值),则此函数的效果最佳,

举例:选中数据,插入带平滑线和数据标记点的散点图,增长趋势线显示公式,预测相同的未来值。▐ 季节性预测:Forecast.ets()
电商中更多的为带有季节性的数据,Excel为此类数据提供了高级预测功能。此函数通过三重指数平滑方法进行此预测。此方法是加权方法,越久远的值,权重越小,也就意味着,重要性越小。- Forecasting.ets.seasonality()
它返回基于历史数据检测到的季节性周期的长度,如有的数据是3个月重复一次,那么它的周期就是3。

第4个参数表示季节性模式的长度。默认值 1 表示自动检测季节性。举例::根据Forecasting.ets.seasonality()我们知道数据的周期为3,所以第4参数填入3。
它返回指定目标日期的预测值的置信区间。默认的置信区间为95%。这意味着95%的预测值将在该值的范围内。

样本量悬殊比较:WilsonScore
我们在进行AB-test或其他分析中,总会涉及比较商品点击率&转化率等情况。
举例:如A商品曝光UV为1000 & 点击UV15,A商品曝光UV为100000 & 点击UV1000,A商品的点击率为1.5%,B商品的点击率为1%,但在比较时并不能代表用户更喜欢A商品,因为AB样本量较为悬殊。
那么如何进行判断呢?WilsonScore平衡样本数量差异的影响,解决小样本的准确性问题。本质上,威尔逊区间其实就是用户喜欢率的一个区间估计。但是该区间估计考虑了样本过小时候的情况,根据样本量对区间估计进行了修正,使得该区间估计能够较好的衡量不同样本量情况。该得分算法经常应用于各个网站的排序上。比如知乎的搜索排序。
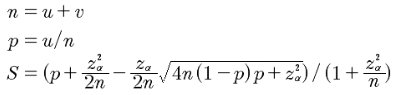
from odps.udf import annotateimport numpy as np@annotate('string->string')class wilsonScore(object): #威尔逊区间下限 def evaluate(self,input_data): pos = float(input_data.split(',')[0]) total = float(input_data.split(',')[1]) p_z=1.96 pos_rat = pos * 1. / total * 1. # 正例比率 score = (pos_rat + (np.square(p_z) / (2. * total)) - ((p_z / (2. * total)) * np.sqrt(4. * total * (1. - pos_rat) * pos_rat + np.square(p_z)))) / \ (1. + np.square(p_z) / total) return str(score)
分析过程我们经常遇到需要结合长期历史表现,对用户/商品/商家打分,用于衡量价值及资源分配。sigmoid函数也叫Logistic函数,它可以将一个实数映射到(0,1)的区间。
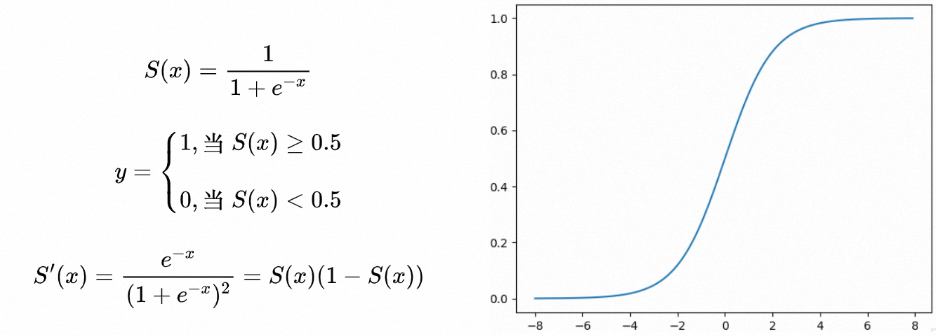
举例:通过对商品历史表现(点击率&GMV)的进行Sigmoid递减打分
三大统计学相关系数:Pearson&Spearman&kendall
▐ 数值型&正态分布相关性度量:皮尔森(Pearson)相关系数
EXCEL和DataWorks中配置了也内置了相关函数,可直接进行调用
EXCEL求相关性:CORREL(S24:S28,T24:T28)
odps:corr(a,b)
通过上述公式我们可以求得两个数值型变量的相关系数,如何评估两个变量之间的相关性呢,我们一般使用假设检验来判断是否显著。
在进行Pearson相关系数检验时,需要先设定显著性水平α,常用的显著性水平有0.05和0.01。然后计算出样本相关系数,根据样本大小n和显著性水平α查找对应的临界值。如果样本相关系数大于临界值,则拒绝原假设,认为两个变量之间存在显著的线性相关关系;否则接受原假设,认为两个变量之间不存在显著的线性相关关系。
相关系数临界值计算器:https://www.jisuan.mobi/gqY.html
▐ 非数值型/非正态分布数相关性度量:斯皮尔曼(Spearman)相关系数
Spearman相关系数是根据随机变量的等级而不是其原始值衡量相关性的一种方法。spearman相关系数的计算可以由计算pearson系数的方法,只需要把原随机变量中的原始数据替换成其在随机变量中的等级顺序即可。
举例:
求(1,10,100,101)、(21,10,15,13)两个非正态分布分布的相关系数
将(1,10,100,101)替换成(1,2,3,4),(21,10,15,13)替换成(4,1,3,2),然后求替换后的两个随机变量的pearson相关系数即可。
▐ 排名相关性度量:肯德尔(kendall)相关系数
kendall相关系数又称作和谐系数,也是一种等级相关系数,其计算方法如下:
对于X,Y的两对观察值Xi,Yi和Xj,Yj,如果XiYi并且Xj>Yj,则称这两对观察值是同序对,否则为异序对。
kendall相关系数的计算公式如下:
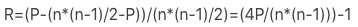
举例:假设我们有8个商品,想商品计算销量排名与GMV排名的相关性A商品销量排名为1,GMV排名为3,比排名4-8的GMV大,因此贡献5个同序对;B商品销量排名为2,GMV排名为4,比排名5-8的GMV大,因此贡献4个同序对;C品销量排名为3,GMV排名为1,比排名4-8的GMV大,因此贡献5个同序对;D品销量排名为4,GMV排名为2,比排名5-8的GMV大,因此贡献4个同序对;同序对数P = 5 + 4 + 5 + 4 + 3 + 1 + 0 + 0 = 22;总对数为 (8+7+6+5+4+3+2+1)/2=28; KL散度是量化两种概率分布P和Q之间差异,数值越小说明越相似,公式如下:
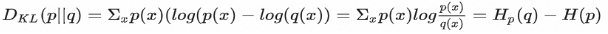
举例:求AB分布的相似度
A分布=[0.3,0.2,0.1,0.2,0.2]
B分布=[0.1,0.3,0.1,0.2,0.3]
曲线拐点:KneeLocator
寻找用户最佳留存时间点,或特征聚类计算最佳K值时,我们常需要从曲线的形状进行分析找到拐点。在python 中有一个自动帮助我们寻找拐点的包,叫kneed。这个包中只需要定义少量的参数(凹凸性及曲线方向),就可以自动地帮助我们找到一条曲线中的拐点。
from kneed import KneeLocatorimport matplotlib.pyplot as plt •x = np.arange(1,31)y = [0.492 ,0.615 ,0.625 ,0.665 ,0.718 ,0.762 ,0.800 ,0.832 ,0.859 ,0.880 ,0.899 ,0.914 ,0.927 ,0.939 ,0.949 ,0.957 ,0.964 ,0.970 ,0.976 ,0.980 ,0.984 ,0.987 ,0.990 ,0.993 ,0.994 ,0.996 ,0.997 ,0.998 ,0.999 ,0.999 ]•kneedle = KneeLocator(x, y, S=1.0, curve='concave', direction='increasing')print(f'拐点所在的x轴是: {kneedle.elbow}')
▐ 熵值法
熵值法是指用来判断某个指标的离散程度的数学方法。离散程度越大,该指标对综合评价的影响越大。可以用熵值判断某个指标的离散程度。熵值法求权重步骤如下:
STEP1:数据标准化
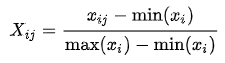
STEP2:计算各指标信息熵
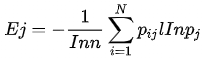
STEP3:确定各指标权重
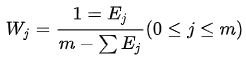
熵值法确定权重只是考虑数据各个指标的离散程度,即数据取值越多其权重就越大,并没有结合具体的实际问题,因此在应用熵值法确定权重时需要结合具体的问题才能使用。
▐ 主成分分析
主成分分析,是考察多个变量间相关性一种多元统计方法,研究如何通过少数几个主成分来揭示多个变量间的内部结构,即从原始变量中导出少数几个主成分,使它们尽可能多地保留原始变量的信息,且彼此间互不相关,作为新的综合指标。DataWorks中的机器学习PAI配置了PCA组件,可直接进行调用,详见:https://pai.dw.alibaba-inc.com/component/detail/255?projectId=21225&spm=a2c3x.12342929.0.0.38e64a9bhMFlBH
STEP2:确定综合得分模型系数
对STEP1中所得的各指标所拥有的三个主成分进行加权平均:
举例:指标3得分模型系数为
STEP3:指标权重归一化
即,将各因素在综合得分模型中的系数进行归一化。
举例:指标3的权重系数为


市场竞争度量/核心圈选:集中度
帕累托法则是帕累托于1906年提出了著名的关于意大利社会财富分配的研究结论:20%的人口掌握了80%的社会财富。在数据分析中,帕累托法则是常应用于业务分析和需求分析两个方面。▐
CRN
指品类销售额排名TOPN的品牌销售额之和占品类销售额的比值。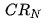 数值越低,说明头部品牌市占率低,其头部品牌的市场瓜分能力较弱,腰尾部品牌面临的机会相对较多。
数值越低,说明头部品牌市占率低,其头部品牌的市场瓜分能力较弱,腰尾部品牌面临的机会相对较多。▐ 消费集中度
指贡献前N%市场份额的用户/商品占比,即二八法则中贡献前80%市场份额的用户/商品占比,可基于市场份额贡献度进行核心类目圈选及品规坑位数规划。
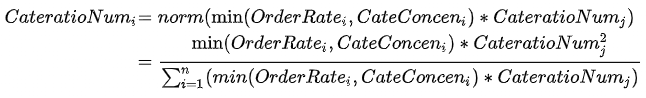
TF-IDF是倾向于过滤掉常见的词语,保留重要的词语,公式如下:
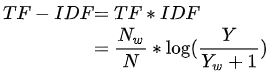
举例:搜索词A在类目X的搜索次数较多,但搜索词A在其他类目上搜索较少,那么搜索词A更能代表类目X,则趋势得分越高,反之越低。
《用数据讲故事》系列,不仅见证了我这个数科小白近两年的点滴成长,也回答了我学生时期关于“大学知识有用论or无用论”的困惑。在我看来大学作为通识教育,注重的是融合价值的塑造和学习能力培养。作为受益者十分感恩学校教会了我“是什么”、“为什么”,工作后能花费最低的认知成本去实践“怎么做”。未来山高水长,我也会将更多的实践总结和思考与大家分享,欢迎一起交流学习!
结语
我们是大聚划算数据科学团队,负责支持聚划算、百亿补贴、天天特卖等业务。我们聚焦优惠和选购体验,通过数据洞察,挖掘数据价值,建立面向营销场、服务供需两端的消费者运营和供给运营解决方案,我们与运营、产品合力,打造最具价格优惠心智的购物入口,最具爆发性的营销矩阵,让货品和心智运营变得高效且有确定性!










