
◆为MySQL填充亿级数据---问题描述
在编写代码之前,应先针对业务设计的数据格式创建表结构,然后填充亿级数据,此阶段出现的典型问题如下:
(1)对于新上线的项目,我们希望能测试出它的最高承载用户量,在数据库为空的情况下,应如何增加亿级数据?
(2)在学习和工作工程中,经常需要使用数据量庞大的表来模拟系统在真实环境中的响应情况。如果只写一段代码,之后循环使用INSERT语句插入数据则实在是太慢了,是否有更快速的方法?
◆问题分析与解决方案
当通过Java、C#、Python等语言对MySQL进行操作时,不仅有语言自身的消耗,还有语言和数据库连接的消耗,所以当想要为数据库增加大量数据时,建议通过中间件或计算机系统对其增加数据量,切勿通过语言连接的方式。
另外,在执行时应尽可能减少事务、链表等相应情况,即减少一切损失执行速度的可能性,这样便可用最快的速度填充整个数据库。例如,在程序设计上,Redisson通过Lua脚本的方式控制Redis,将每一页的Lua脚本交由Redis自身,而非使用Jedis连接的方式来解决,所以Redisson的性能一向优良。
我们分别通过INSERT INTO SELECT、存储过程和Loadfile三种方案为MySQL快速填充亿级数据。其中,INSERT INTO SELECT方案是MySQL提供的SQL语句,而SQL语句可直接在MySQL内执行,所以速度更快。存储过程方案可减少事务提交次数,并且可以增加包含逻辑结构的数据,以快速填充数据库。
Loadfile方案可将外置资源文件导入数据库,通过数据迁移的方式快速填充数据库。
◆为MySQL填充亿级数据实战
这里只准备了一台服务器作为MySQL服务器。该服务器内存1GB、硬盘20GB、CPU 1核、系统版本CentOS 6.5、MySQL版本5.1.73。
增加的测试数据的表结构如下所示:
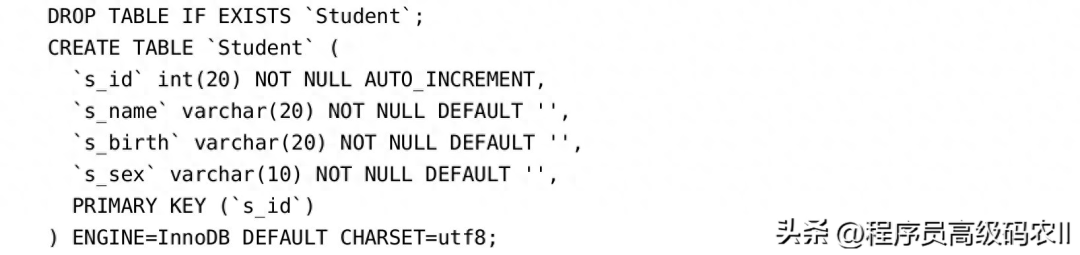
在创建表之后,可以通过如下命令查看创建的表语句:

注意:该表仅用来测试,无其他特殊含义。
◆INSERT INTO SELECT方案
INSERT INTO SELECT语句可以先从一个表中复制数据,再把复制的数据插到一个已存在的表(目标表)中,并且目标表中已存在的行完全不受影响。从一个表中复制所有的列插到目标表中的命令如下所示:

也可以从一个表中只复制某些列插到目标表中:

1. INSERT INTO SELECT语句的优点和缺点
为数据库填充测试数据最快且最容易的方案是使用INSERT INTO SELECT语句。该方案不涉及任何I/O方面的消耗,最大的缺点是在创建数据时数据自由度不高。
注意,INSERT INTO SELECT语句只能为数据库填充数据,绝不能为数据库迁移数据。例如,需要将表A的数据迁移到表B中,虽然貌似可以使用INSERT INTO SELECT语句完成需求,但是INSERT INTO SELECT语句采用全表扫描的方式读取数据库资源,在默认的数据库隔离级别下,表B会被逐步行锁(扫一条锁一条),表A则会被表锁(全表加锁)。由于锁住的数据越来越多,进而导致数据库增删改大量失败,从而导致应用程序崩溃。
2. INSERT INTO SELECT语句的实现过程
(1)插入初始化数据:
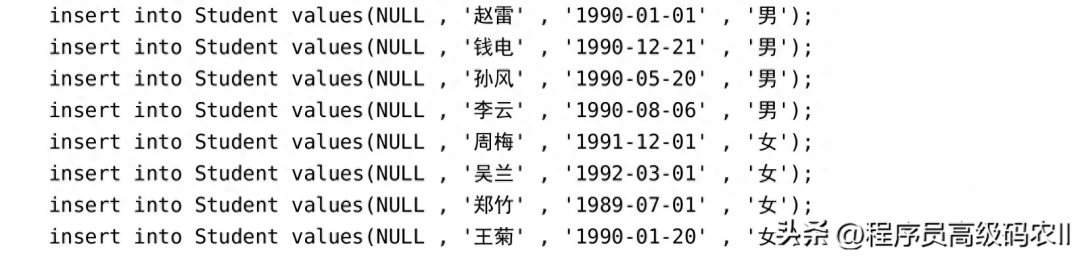
初始化结果如图2-1所示。
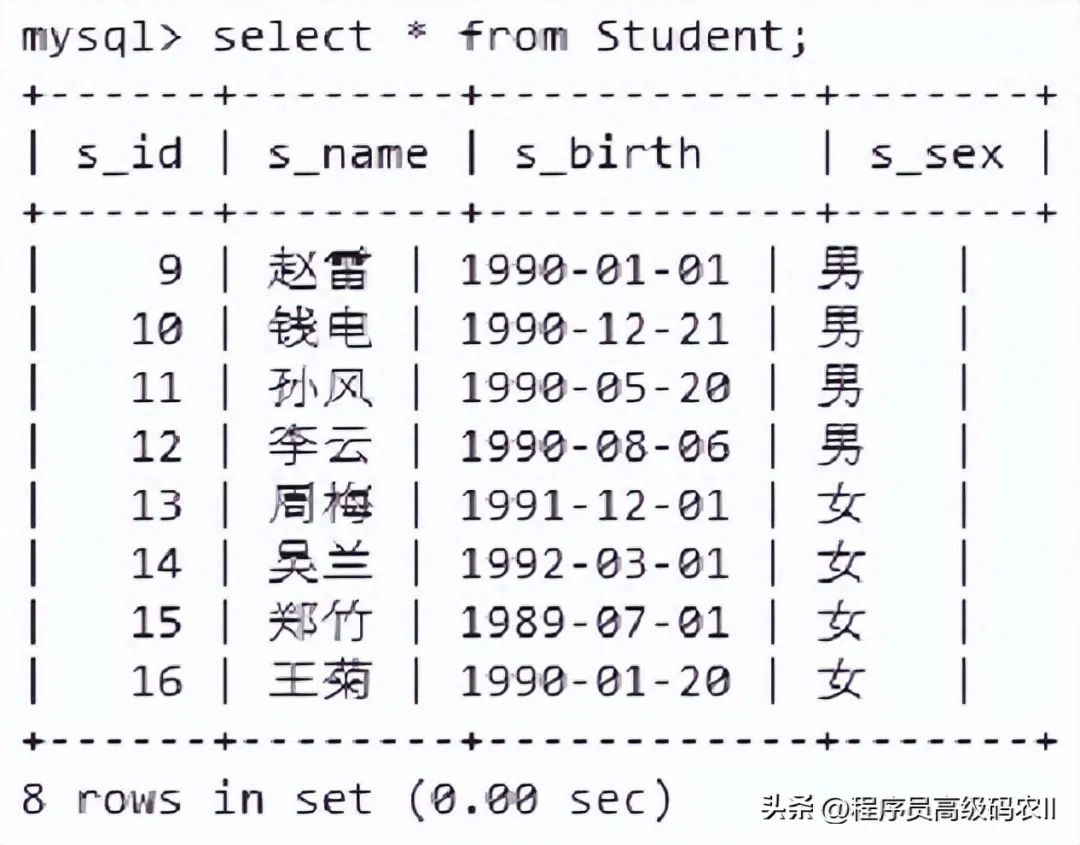
图2-1
(2)通过INSERT INTO SELECT语句创建数据:
在多次使用INSERT INTO SELECT语句之后,每次使用该语句都会使数据量翻倍。在硬盘与CPU足够的情况下,几秒即可填充亿级数据,结果如图2-2所示。
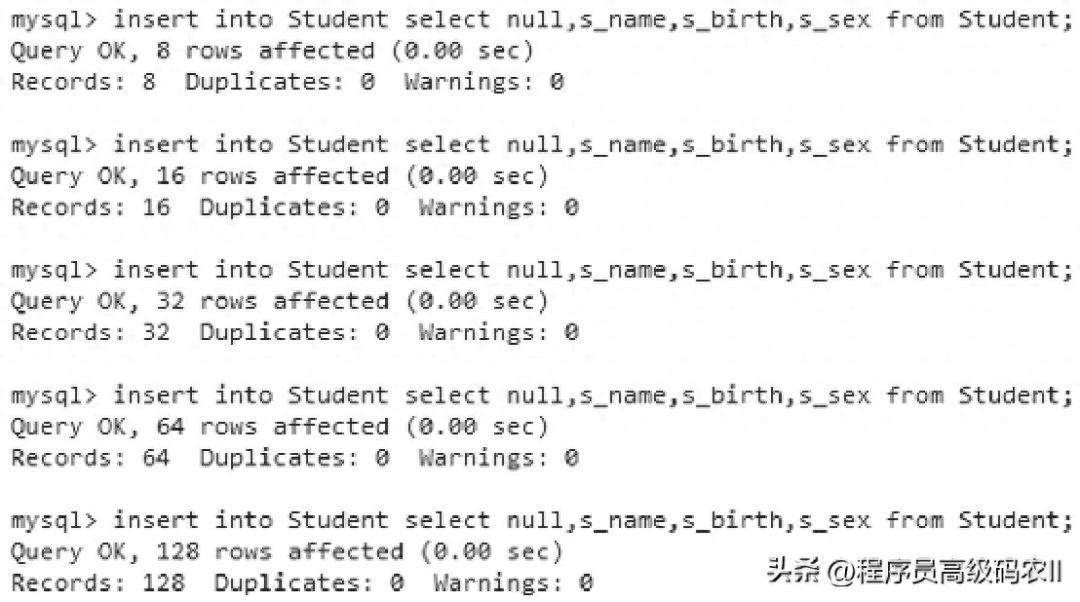
图2-2
3. INSERT INTO SELECT语句可能出现的异常
当复制400万条数据到表中时已经出现了错误,如下所示:

这是由于缓冲区不够导致的,属于MySQL缓冲区异常。
此时需要在InnoDB buffer Pool中处理缓存,处理的缓存内容如下所示:
(1)数据缓存(InnoDB数据页面)。
(2)索引缓存(索引数据)。
(3)缓存数据(在内存中已修改但尚未写入磁盘的数据)。
(4)内部结构(如自适应哈希索引、行锁等)。
.……
因此,当MySQL大批量执行INSERT INTO SELECT语句时,要求InnoDBBuffer Pool要足够大,并且当InnoDB Buffer Pool较大时,还会提高INSERTINTO SELECT语句的执行效率。解决MySQL缓冲区异常的方式只有两种:
(1)在INSERT INTO SELECT语句中增加LIMIT限制性语句,保证每次增加的数据量缓冲区都可以承载。
(2)增加innodb_buffer_pool_size的值。
4. 增加innodb_buffer_pool_size的值的步骤
(1)使用下面的命令可以查看当前表使用了哪种数据库引擎:

结果如图2-3所示。

图2-3
(2)使用下面的命令可以查看当前数据库引擎状态中的参数:

运行之后,截取部分参数,如表2-1所示。从表2-1中可以看出,innodb_buffer_pool_size的值为“8388608”,即为8MB。
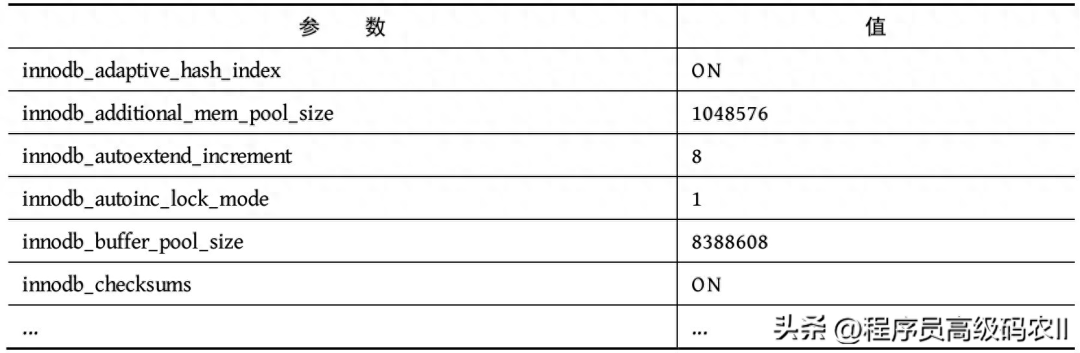
表2-1
(3)查看当前数据库引擎状态中的参数。
查找配置文件,在Linux系统中,配置文件是my.cnf;在Windows系统中,配置文件是my.ini。设置innodb_buffer_pool_size=64MB。更改之后,重 新 运 行 MySQL , 再 次 查 看 数 据 库 引 擎 状 态 中 的 参 数 可 以 发 现 ,innodb_buffer_pool_size的值已经修改了,如图2-4所示。
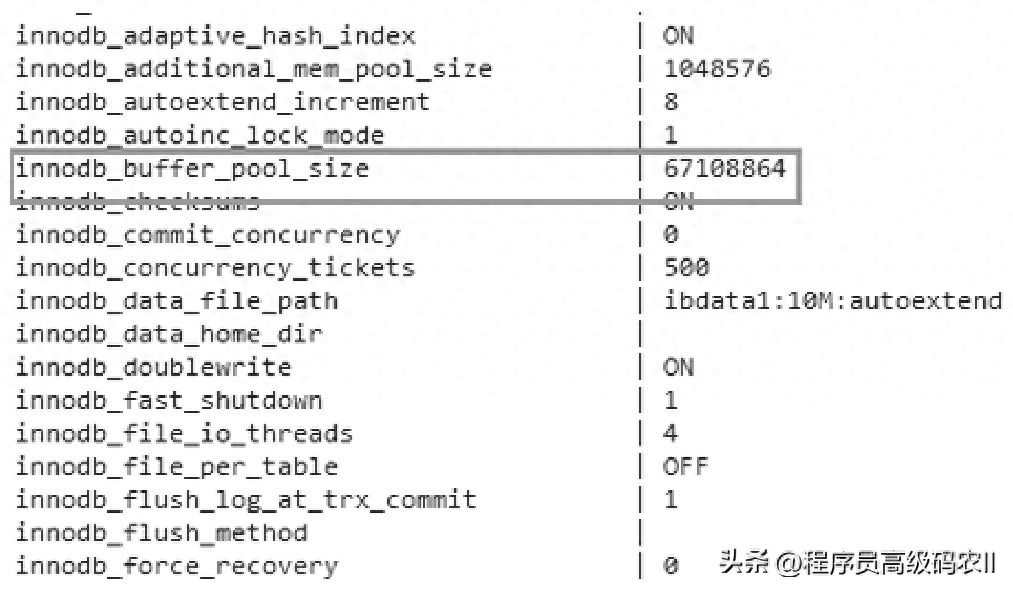
图2-4
◆存储过程方案
存储过程(Stored Procedure)是数据库中可以完成某种特定功能的SQL语句集。用户可以通过指定存储过程的名称并给定参数(需要时)来调用并执行存储过程。我们可以把存储过程简单地理解为数据库在SQL语言层面的代
码封装与重用。MySQL是从5.0版本开始支持存储过程的。
1. 存储过程方案的优点和缺点
优点:
(1)存储过程可封装,并隐藏复杂的商业逻辑。
(2)存储过程可以回传值,并且可以接收参数。
(3)存储过程无法使用SELECT指令来运行,因为它是子程序,与查看表、数据表或用户定义函数等不同。
(4)存储过程可以用在数据检验上,强制执行商业逻辑等。
缺点:
(1)存储过程往往定制化于特定的数据库上,当切换到其他数据库时,因为支持的编程语言不同,需要重写原有的存储过程。
(2)存储过程的性能调校与编写通常受限于数据库。
2. 存储过程方案的实现过程
声明存储过程,如下所示:

注意:此处可以使用存储方案的随机数函数来创建数据。另外,如果要
增加事务,则不要过于频繁提交事务,否则会出现磁盘I/O异常。
调用存储过程如表2-2所示。

表2-2
◆ Loadfile方案
Loadfile方案相当于使用Java或Python等语言先创建CVS、txt等文件,再把数据存放在这些文件中,最后通过MySQL的Loadfile命令,把文件中的数据导入MySQL中。
1. Loadfile方案的优点和缺点
Loadfile方案与INSERT INTO SELECT方案和存储过程方案相比,自由度更高。但是从需要准备的文件来看,Loadfile方案整体所需要的时间比INSERT INTO SELECT方案和存储过程方案要多。
2. Loadfile方案的实现过程
(1)准备文件。
通过Java或Python等语言编写代码,输出相应的CVS文件或txt文件,文件内容如图2-5所示。
图2-5
(2)把文件导入MySQL中。
使用如下命令把文件上传到服务端的/var/lib/mysql/目录下:
Navicat和SQLYog等工具也有上传文件的功能,但是数据库在连接这类工具时速度会慢很多。
◆第三方解决方案
1. DataFactory
DataFactory是一个大数据生成工具,可以按照数据的某些规律大批量地生成数据。该工具的特点是简单易用。
2. Datafaker
Datafaker是一个大批量测试数据和流测试数据的生成工具,是一个多数据源测试数据构造工具,可以模拟生成大部分常用数据类型的数据。
◆最终结果
当数据量为1亿1千万条左右时,如图2-6所示。另外,单表亿级数据量在硬盘中约占用5.4GB。因为表结构不同、数据量不同,所以不同的表对硬盘的占用情况也不同,此值只能作为参考。
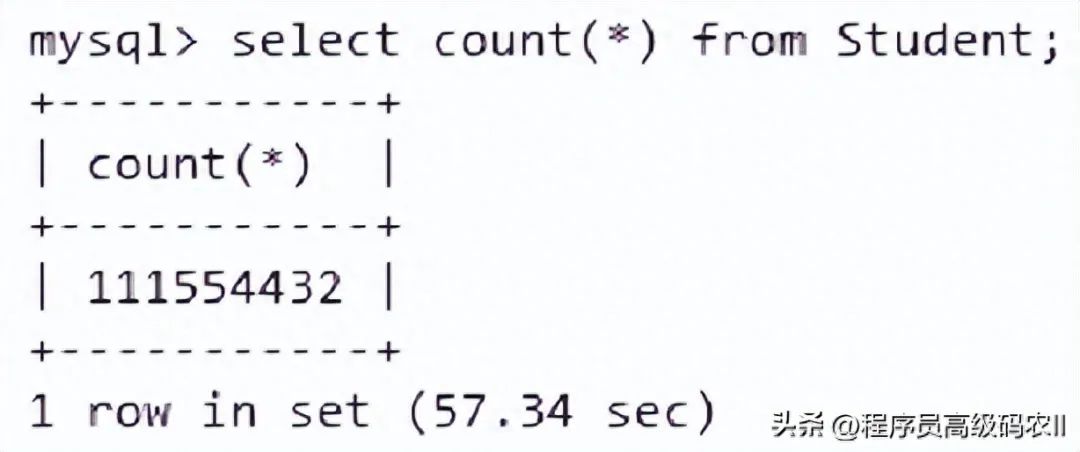
图2-6
通过SQL语句在无索引、单线程、无判断、无跨表,且单核CPU、1GB内存的情况下,获取当前表结构亿级表中的10条,所需时间约为0.061s。在优化SQL查询与表结构的过程中,可以把此值作为参考参数对SQL进行优化。
在实际工作中,可以用8核CPU、16GB内存、当前表结构和实际工作中的SQL并发数查询SQL,以得到最快响应时间,根据此响应时间长短进行优化。
要么修改表结构,修改SQL优化索引,要么修改代码减少查询次数,或者查看网络带宽是否到达上限。
若在实际工作中无法完成网络带宽受限的测试,那么就把代码中的响应时间与SQL响应时间进行对比。如果SQL响应速度更快,则优化代码与网络。
如果SQL响应速度较慢,则优化索引。如果无法优化索引,就修改表结构。
图2-7与图2-8分别展示了空表和亿级数据下,两种不同的磁盘使用(根据表结构与存储内容的不同,此数值仅作为参考)。
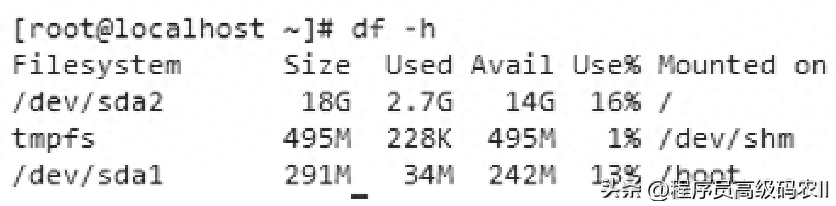
图2-7
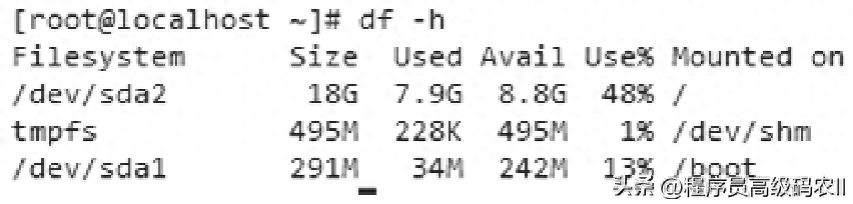
图2-8
来源:https://www.toutiao.com/article/7273309528844780091/?log_from=1474724ee1609_1693960191870
“IT大咖说”欢迎广大技术人员投稿,投稿邮箱:aliang@itdks.com
IT大咖说 | 关于版权
由“IT大咖说(ID:itdakashuo)”原创的文章,转载时请注明作者、出处及微信公众号。投稿、约稿、转载请加微信:ITDKS10(备注:投稿),茉莉小姐姐会及时与您联系!
感谢您对IT大咖说的热心支持!









