我们都说大模型会改变所有应用的形态,ChatGPT 现在走完了变革的最后一步。
刚刚,ChatGPT 进行了一次重要更新,不管是 GPT-4 还是 GPT-3.5 模型,现在都可以基于图像进行分析和对话了。ChatGPT 中的新图像识别功能允许用户使用 GPT-3.5 或 GPT-4 模型上传一张或多张图像配合进行对话。OpenAI 在其宣传博客文章中声称该功能可用于各种日常应用:从通过拍摄冰箱和食品储藏室的照片来让 AI 决定晚餐吃什么,到排除烧烤炉无法启动的原因。OpenAI 还表示,你可以使用设备的触摸屏圈出他们希望 ChatGPT 关注的图像部分。就像这个视频所演示的,用户能够询问如何升起自行车座椅,需要提供的是照片、使用手册和用户工具箱的图片。然后,ChatGPT 会做出反应并建议用户如何完成这一过程。OpenAI 还表示,ChatGPT 的移动端 App 还将添加语音合成选项,与现有的语音识别功能配合使用时,我们就能与人工智能助手进行完全直接的口头对话。与此同时,在音频方面,ChatGPT 新的语音合成功能据说由 OpenAI 所称的「新文本到语音模型」驱动,尽管文本到语音问题已经解决了很长时间。该公司表示,该功能推出后,用户可以在应用设置中选择语音对话,然后从「Juniper」、「Sky」、「Cove」、「Ember」和「Breeze」等五种不同的合成声音中进行选择。OpenAI 表示,这些声音都是与专业配音演员合作制作的。
这让人想起了 OpenAI 2022 年开源的语音识别系统 Whisper,今后这一系统将继续处理用户语音输入的转录工作。自 ChatGPT iOS 应用程序今年 5 月推出以来,Whisper 就一直集成在其中。OpenAI 计划 「在未来两周内」向 Plus 和 Enterprise 订阅者推出 ChatGPT 中的这些功能,它还指出,语音合成仅适用于 iOS 和安卓端应用,不过图像识别功能在网络界面和移动应用程序上均有提供。鉴于 ChatGPT 的数亿用户们还没有亲自测试过这些功能,所以我们还不能判断它的效果如何。而且对于它的工作原理,OpenAI 也和以往一样没有详细说明,仅着重强调了大模型的安全性。参考同类的 AI 研究可以推测,多模态 AI 模型通常会将文本和图像转换到一个共享的编码空间,从而使它们能够通过相同的神经网络处理各种类型的数据。OpenAI 可以使用 CLIP 在视觉数据和文本数据之间架起一座桥梁,将图像和文本表征整合到同一个潜在空间(一种矢量化的数据关系网)中。这种技术可以让 ChatGPT 跨文本和图像进行上下文推理。今年 3 月,OpenAI 上线 GPT-4 ,展示了 AI 模型的多模态功能,在现场演示时,我们见识到了 GPT-4 对文本和图像的处理能力,但一直以来,这种功能普通用户都无法使用。相反,OpenAI 在与 Be My Eyes (是一款为盲人和弱视人士提供免费移动应用程序)的合作中创建了一款可以为盲人解读场景照片的应用程序。然而,由于隐私问题导致 OpenAI 的多模态功能至今未能发布。最近几周,科技巨头一直在竞相推出多模态方面的更新,将更多 AI 驱动的工具直接集成到核心产品中。谷歌上周宣布对其 ChatGPT 竞争对手 Bard 进行一系列更新,同样在上周,亚马逊表示将为其语音助手 Alexa 带来基于生成式 AI 的更新。在最近 ChatGPT 更新公告中,OpenAI 指出了对 ChatGPT 进行功能扩展的一些限制,并承认存在潜在的视觉混淆(即错误识别某些内容)以及视觉模型对非英语语言的不完美识别等问题。OpenAI 表示,他们已经在极端主义和科学能力等领域进行了风险评估,但仍然建议谨慎使用,尤其是在高风险或科学研究等专业环境中。
鉴于在开发上述 Be My Eyes 应用程序时遇到的隐私问题,OpenAI 指出,他们已经采取了技术措施,以限制 ChatGPT 的能力,这些系统应该尊重个人隐私。尽管存在缺陷,但 OpenAI 仍然赋予了 ChatGPT「看、听、说」的能力。然而,并不是所有人都对这一更新感到兴奋。Hugging Face AI 研究员 Sasha Luccioni 博士表示,「我们应该停止像对待人类一样对待 AI 模型。ChatGPT 拥有看、听、说的能力是不被允许的。但它可以与传感器集成,以不同的方式来提供信息。」
新能力上线之后,人们纷纷表示欢迎,有人表示这是 ChatGPT 迄今为止最大的变革之一,就差套个机器人的物理外壳了。
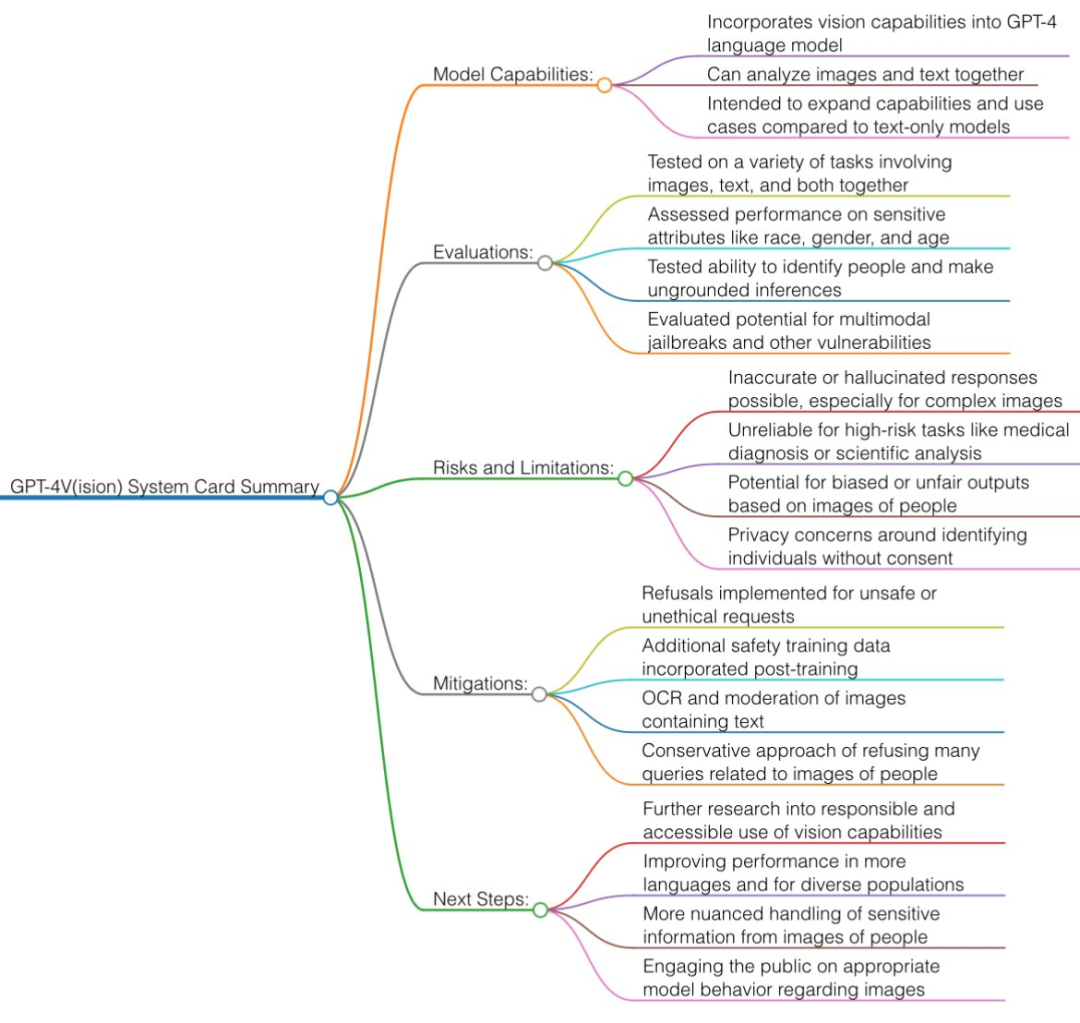
在 AI 研究领域,人们也开始分析起新版 ChatGPT 背后的技术。从 OpenAI 自己公开的简短文档看,是有一个名为 GPT-4V (ision) 的新款大模型。
文档链接:https://cdn.openai.com/papers/GPTV_System_Card.pdf英伟达研究员 Jim Fan 认为 GPT-4V 是一个整体模型。与之对应的是,谷歌的 Bard 是一个二阶段模型,首先应用 Google Lens API 进行图像字幕,然后使用纯文本 LLM 进行更多推理。OpenAI 表示,与 GPT-4 类似,GPT-4V 的训练是在 2022 年完成的,在 2023 年 3 月开始提供系统的早期访问。由于 GPT-4 是 GPT-4V 视觉功能背后的技术,因此其训练过程也是一样的。目前看来,GPT-4V 于 2022 年完成训练之后,一直在经历安全性测试。- GPT-4V 仍然是(视觉,文本)到文本模型,使用互联网图像和文本数据的混合进行训练并预测下一个单词 token,然后再用 RLHF。
- 今天的 GPT-4V 具有比 3 月份版本更好的 OCR(从像素读取文本)能力。
- 安全限制:GPT-4V 在许多类别中的拒绝回答率很高。例如,当被要求回答敏感的人口统计问题、识别名人、从背景中识别地理位置以及解决验证码时,它现在会说「抱歉,我无能为力」。
- 一种简单的技术是将图像翻译成几个单词(例如「杀人」的刀的图片),然后应用纯文本 GPT-4 过滤器加以识别。
- 多模态攻击:这是一个有趣且新颖的方向。例如,你可以上传恶意提示的屏幕截图(例如 Do-Anything-Now,臭名昭著的「DAN」提示)。或者在餐巾纸上画一些神秘的符号来以某种方式停用过滤器。
- 在严肃的科学文献(如医学)中,GPT-4V 仍然会产生幻觉,部分原因是 OCR 不准确。所以再次强调,不要接受任何 GPT 的医疗建议!
不过有人表示,看起来 Bard 对于图像的识别准确率比 ChatGPT 要高。有关新技术的贡献者,OpenAI 副总裁 Peter Welinder 本次特别感谢了工程师 Raul Puri。此外,多模态 ChatGPT 的主要贡献者还包括 Hyeonwoo Noh、Jamie Kiros、Long Ouyang、Daniel Levy、Chong Zhang、Sandhini Agarwal 等人。
https://openai.com/blog/chatgpt-can-now-see-hear-and-speakhttps://arstechnica.com/information-technology/2023/09/chatgpt-goes-multimodal-with-image-recognition-and-speech-synthesis/https://twitter.com/DrJimFan/status/1706478482296021344
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com










