表格数据需要深度学习吗?
NIPS 2022, Why do tree-based models still outperform deep learning on typical tabular data?
尽管大多数发表的表格深度学习研究声称能够击败或匹敌基于树的模型,但这些声称受到了质疑,有些简单的深度学习模型(如Resnet),似乎能够与一些「新模型」竞争,并且大多数这些方法似乎在新的数据集上表现不佳。
本文中作者进行了广泛的基准测试,包括使用标准和新颖的深度学习方法以及基于树的模型,如XGBoost和随机森林,涵盖了大量不同数据集和不同的超参数组合。
实验细节
实验数据集
作者选择了45个来自不同领域的表格数据集,这些数据集主要来自OpenML。选择这些数据集的标准包括:
- 异质的列:数据集中的列应该对应不同性质的特征,而不是像图像或信号数据集。
- 低维度:只保留具有d/n比例低于1/10和d低于500的数据集。
- 无文档数据:移除那些缺乏足够信息的数据集,但如果数据集中的特征是异质的,即使列名未提供,也会保留这些数据集。
- I.I.D.数据:移除流式数据集或时间序列数据,以确保数据是独立同分布的。
- 真实世界数据:移除人工生成的数据集,但保留一些模拟数据集。
- 不过于小:移除具有太少特征(< 4)和太少样本(< 3,000)的数据集。
数据预处理
- 平衡的类别:对于分类问题,如果存在多个类别,作者会对目标进行二元化处理,即取最多样本的两个类别,并保持每个类别的样本数量一致。
- 低基数的分类特征:作者移除了具有超过20个不同项目的分类特征。
- 高基数的数值特征:作者移除了具有少于10个唯一值的数值特征。具有2个唯一值的数值特征被转换为分类特征。
超参数搜索
- 随机搜索:作者对每个数据集运行约400次的随机搜索,其中基于树的模型在CPU上运行,神经网络模型在GPU上运行。
- 模型性能研究:为了研究性能与随机搜索迭代次数n的关系,作者在这n次迭代中,通过在验证集上找到最佳的超参数组合,然后在测试集上评估模型性能。
- 默认超参数:在每次随机搜索中,作者始终从每个模型的默认超参数开始。
特征工程
- 高斯化特征:对于神经网络训练,特征被使用Scikit-learn的QuantileTransformer进行高斯化处理。
- 转换回归目标:在回归设置中,当目标变量的分布呈重尾分布时(例如房价),目标变量进行对数变换。
- 独热编码:对于那些不能原生处理分类变量的模型,作者使用ScikitLearn的OneHotEncoder对分类特征进行独热编码,以便模型可以处理这些特征。
实验结果
模型精度对比
在基准测试中,研究者选择了一系列树模型和深度学习模型进行性能评估。树模型包括以下三个被从业者广泛使用的最先进模型:
- Scikit Learn的RandomForest:随机森林模型。
- 梯度提升树(GradientBoostingTrees,GBTs):在使用分类特征时使用HistGradientBoostingTrees。
此外,他们还对以下深度学习模型进行了基准测试:
- MLP(多层感知器):一种经典的多层感知器模型,使用了Pytorch的ReduceOnPlateau学习率调度器。
- Resnet:类似于MLP,具有丢失层(dropout)、批量/层规范化(batch/layer normalization)和跳连通(skip connections)。
- FT_Transformer:这是一个简单的Transformer模型,结合了一个模块,用于嵌入分类和数值特征。
通过对比实验结果,有如下初步结论:
- 调优超参数并不会使神经网络在表格数据上达到最先进的性能。
-
基于树的模型在每个随机搜索预算下表现卓越,并且即使在大量的随机搜索迭代之后,性能差距仍然较大。
- 分类变量并不是神经网络在表格数据上的主要弱点,在仅使用数值变量的情况下,基于树的模型和神经网络之间的性能差距较小。
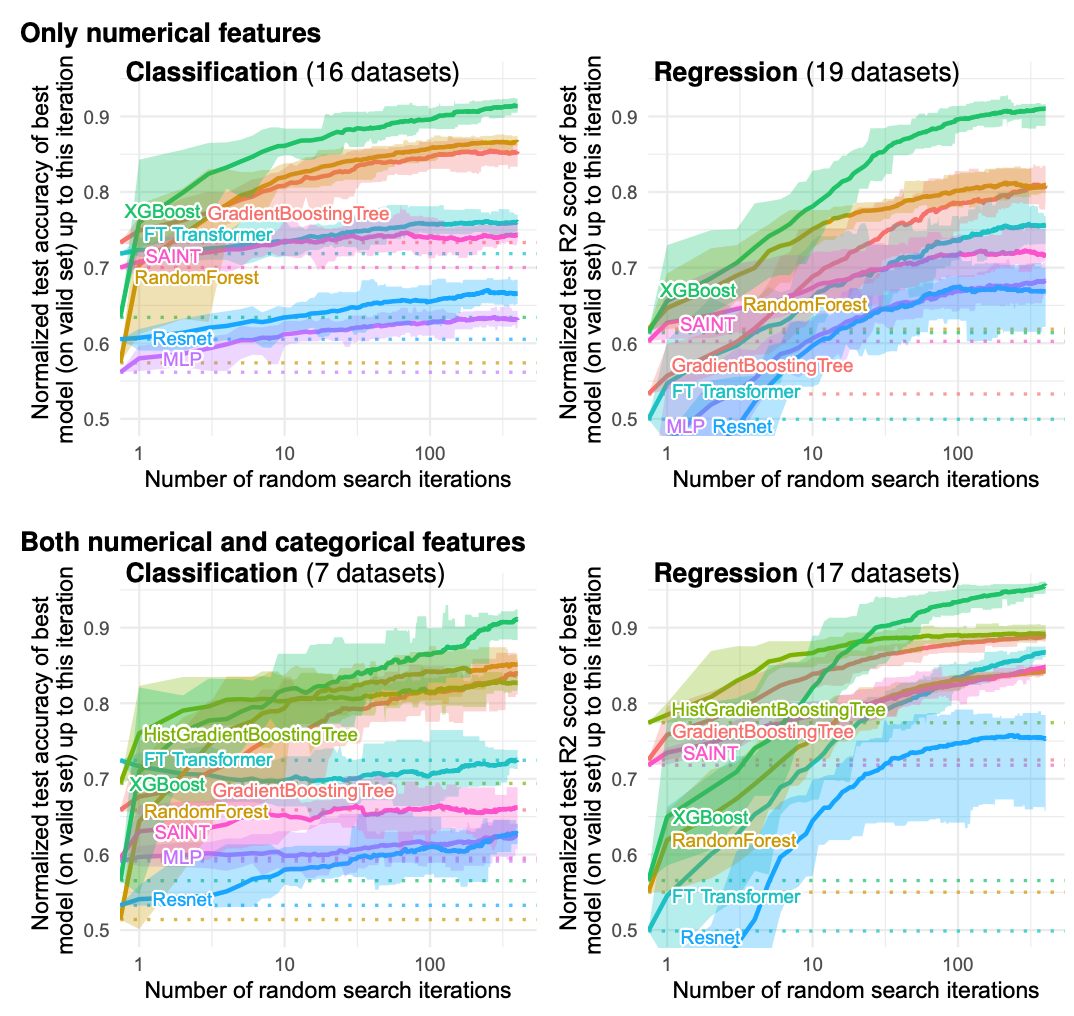
决策树的归纳偏见
发现1:神经网络倾向于过于平滑的解决方案
。对训练集上的目标函数进行平滑处理明显降低了基于树的模型的准确性,但几乎不影响神经网络的准确性。
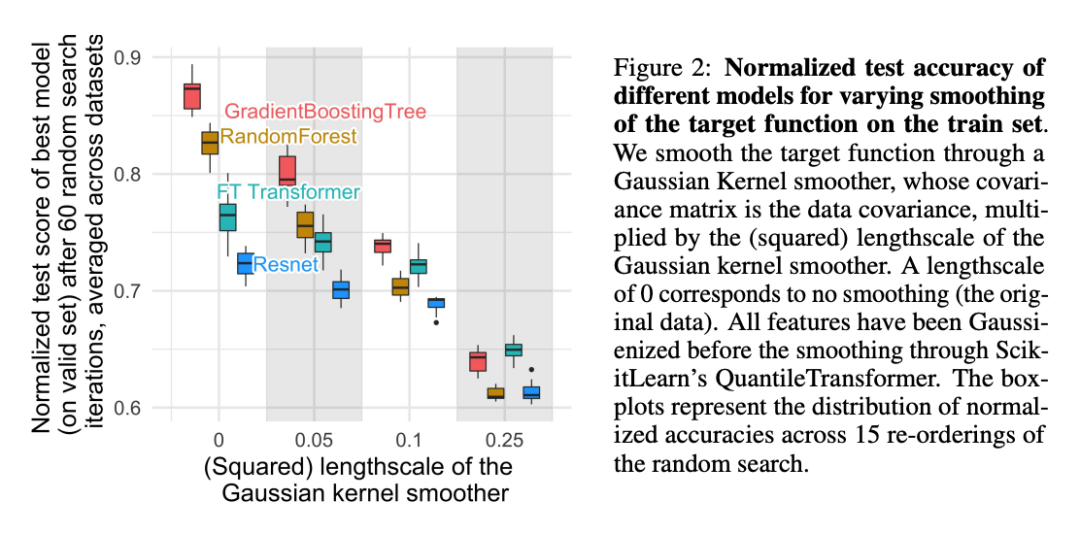
这些结果表明,我们数据集中的目标函数不是平滑的,而神经网络与基于树的模型相比,在拟合这些不规则函数方面表现不佳。神经网络倾向于低频函数。而基于决策树的模型学习分段常数函数,因此不具有这种偏见。
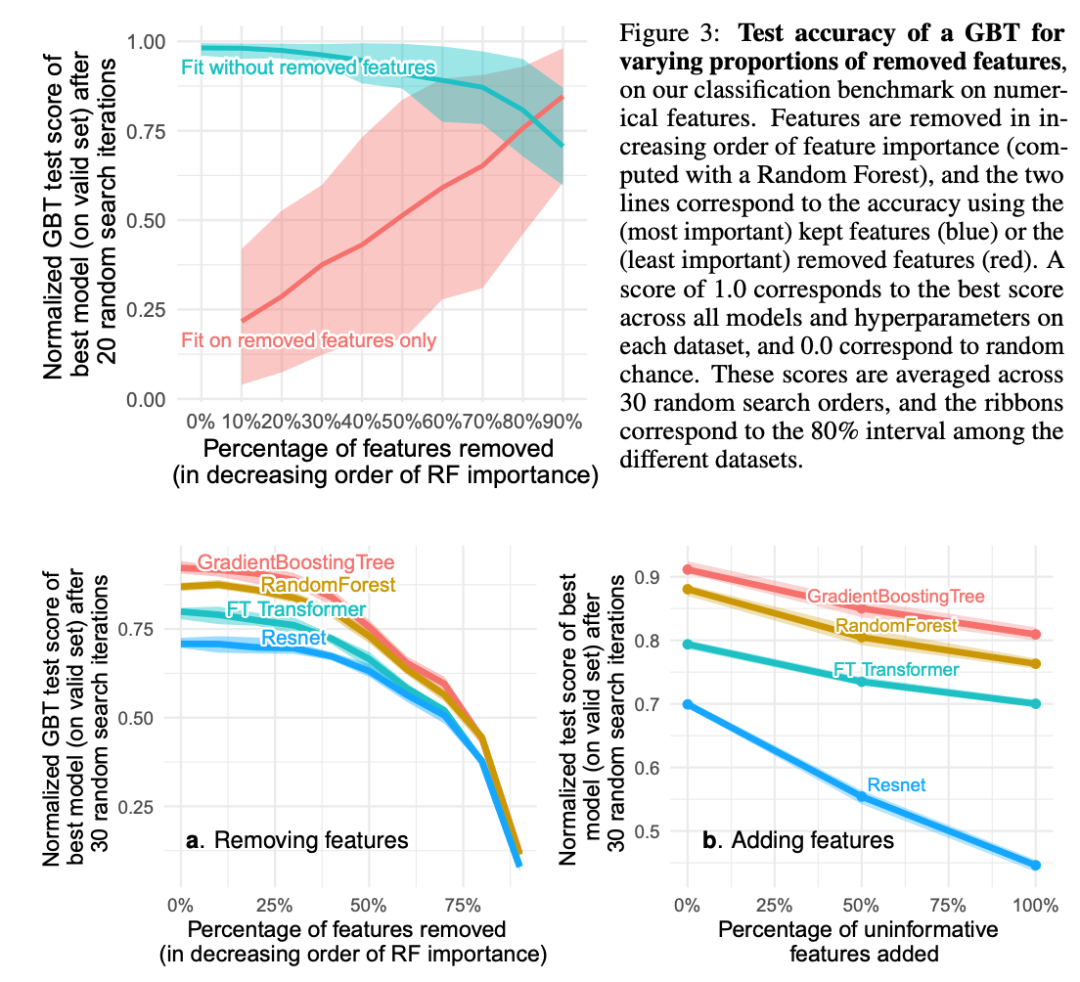
发现2:无信息特征对MLP-like神经网络的影响更大
表格数据集包含许多无信息特征。对于每个数据集,根据特征的重要性(由随机森林排名)逐渐删除了越来越多的特征。删除高达一半的特征对GBT的分类准确性影响不大。
MLP-like架构对无信息特征不够健壮,添加无信息特征则扩大了差距。由于删除了这些特征,准确性下降被删除无信息特征所补偿,这对MLP比对其他模型更有帮助(我们同时删除了冗余特征,不应影响模型)。
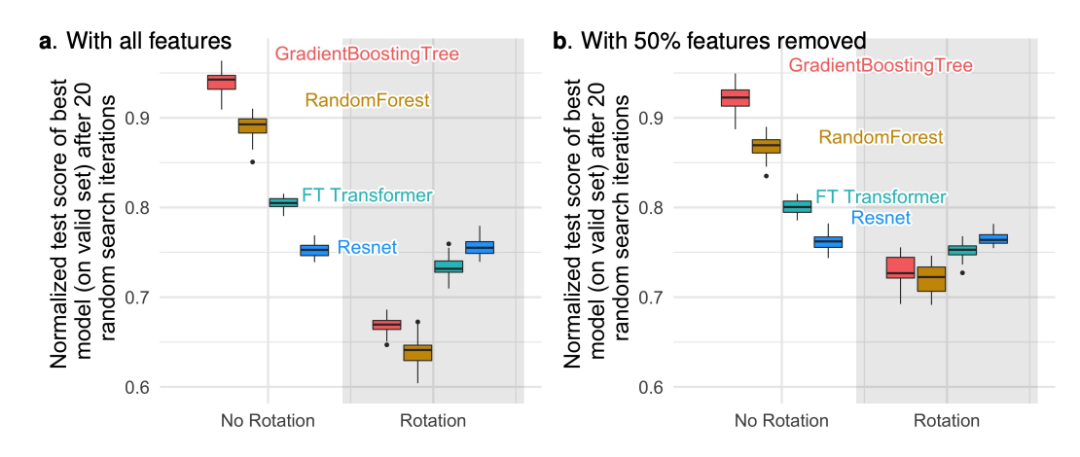
发现3:数据不具备旋转不变性,因此学习过程也不应具备旋转不变性
为什么MLP相比其他模型更受无信息特征的限制?一个答案是,这种学习器是旋转不变的:在训练集上学习MLP并在测试集上评估它的学习过程,在对训练集和测试集的特征应用旋转(单位矩阵)时不会发生变化。
实验结果表明只有Resnets是旋转不变的。更令人惊讶的是,随机旋转反转了性能顺序:神经网络现在高于基于树的模型。在每个数据集中去除最不重要的一半特征(在旋转之前),所有模型的性能都下降,除了Resnets,但下降幅度不如使用所有特征时显著。
实验结果
树模型更容易产生良好的预测,并且计算成本要低得多。这种优势是由表格数据的特定特征解释的。
研究结果表明,对于中等规模的数据集(大约10,000个样本),基于树的模型在速度方面表现出色,即使不考虑速度优势,它们仍然在性能上领先。
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的二维码加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)









